随着越来越多大语言模型(LLM)在行业落地,不少企业已开始进行生成式 AI 应用的试点、开发,或在生产环境中试用 AI 应用。这些应用场景不仅要求强大的算力,还非常考验 IT 基础设施对 GPU 的支持能力、资源调度灵活性、混合负载支撑能力,以及可满足多样化数据的存储能力。
针对企业用户的 AI 使用需求,SmartX 推出了面向 AI 应用的超融合基础设施解决方案,通过算力融合、工作负载融合和存储融合,为企业级 AI 应用提供高性能、低时延、灵活敏捷的计算与存储资源支持。以下,我们将针对 AI 应用场景的 IT 基础设施需求,深入解读 SmartX 提供的解决方案。
您可访问 AI 基础设施解决方案专题页面,并下载阅读电子书《超融合技术原理与特性解析合集》,进一步了解 SmartX 超融合 GPU 直通与 vGPU 支持等 AI 应用场景支持特性。
企业级 AI 应用对 IT 基础架构有哪些要求
目前,大部分企业用户都选择基于已训练好的行业大模型(在微调后)进行 AI 应用的开发,或直接在生产环境中使用已开发好的 AI 应用。虽然这些场景不需要大模型训练级别的算力支持,但仍对 IT 基础架构的性能、资源利用率、容器环境支持、多样化数据存储能力等方面有较高的要求。
灵活的计算与存储资源调度
在进行 AI 应用开发时,不同开发组对 GPU 资源的需求量不同,一些开发任务也不会完全占用一块 GPU 卡的资源;在使用 AI 应用时,不同应用对 GPU 和存储的资源需求也不尽相同,且需求量可能变化频繁。这些都要求 IT 基础设施能够灵活切分、调度计算与存储资源,同时支持高性能 CPU 与 GPU 算力,在提升资源利用率的同时满足不同应用/开发任务的资源需求。
高性能、低时延的存储支持
对行业大模型进行微调时使用的 GPU 规模较大,要求存储能够为 GPU 并行计算提供高性能、低时延的数据支持。AI 应用的全流程也要面对多个数据源的大量数据读取/写入:源数据通过预处理,可参与到大模型的微调和推理过程,并对推理形成的文本/语音/视频数据进行保存和输出。这些工作都要求存储具备高速写入与读取能力。
多样化的数据存储支持
上述 AI 应用相关的工作流程中,需要同时处理结构化数据(如数据库)、半结构化数据(如日志)和非结构化数据(如图像和文本),要求 IT 基础设施能够支持适用于不同类型数据的不同存储技术。AI 工作的不同环节使用存储数据的需求也各不相同,有些需要提供高速存储响应,另一些可能更需要共享读写能力。
虚拟化与容器化工作负载的统一支持
得益于 Kubernetes 的灵活调度能力,越来越多的 AI 应用正在采用容器化和云原生化的运行模式,而基于虚拟机运行的应用仍将长期存在,这就要求 IT 基础设施能够为虚拟化和容器环境提供统一支持和管理。
此外,为了支持 AI 应用的快速上线并跟随业务发展的规模,IT 基础架构也应具备灵活扩展、简易运维、快速部署等能力。
面向 AI 应用的 SmartX 超融合基础设施解决方案
SmartX 超融合基础设施可为企业用户提供满足 AI 应用需求的计算与存储资源服务:
- 算力融合:超融合集群中的主机上,可以灵活选择配置数量不同、型号不同的 GPU,用户工作负载可从超融合集群按需获得所需的 CPU 算力和 GPU 算力。SmartX 超融合支持 GPU 直通和 vGPU,并支持 MIG(多实例切分)、MPS(多进程服务)等技术,允许用户对 GPU 进行灵活切分,提升虚拟化和容器环境中 GPU 使用效率和 AI 应用运行效率。
- 工作负载融合:搭配 SMTX Kubernetes 服务(SKS),用户可使用超融合架构统一支持虚拟化和容器化 AI 应用,实现工作负载的融合部署,满足不同工作负载对性能、安全、敏捷等方面的不同需求。
- 存储融合:SmartX 自主研发的分布式存储可支持多种存储介质,满足 AI 应用的多样化数据存储需求,并为高 I/O 场景提供卓越、稳定的存储性能。
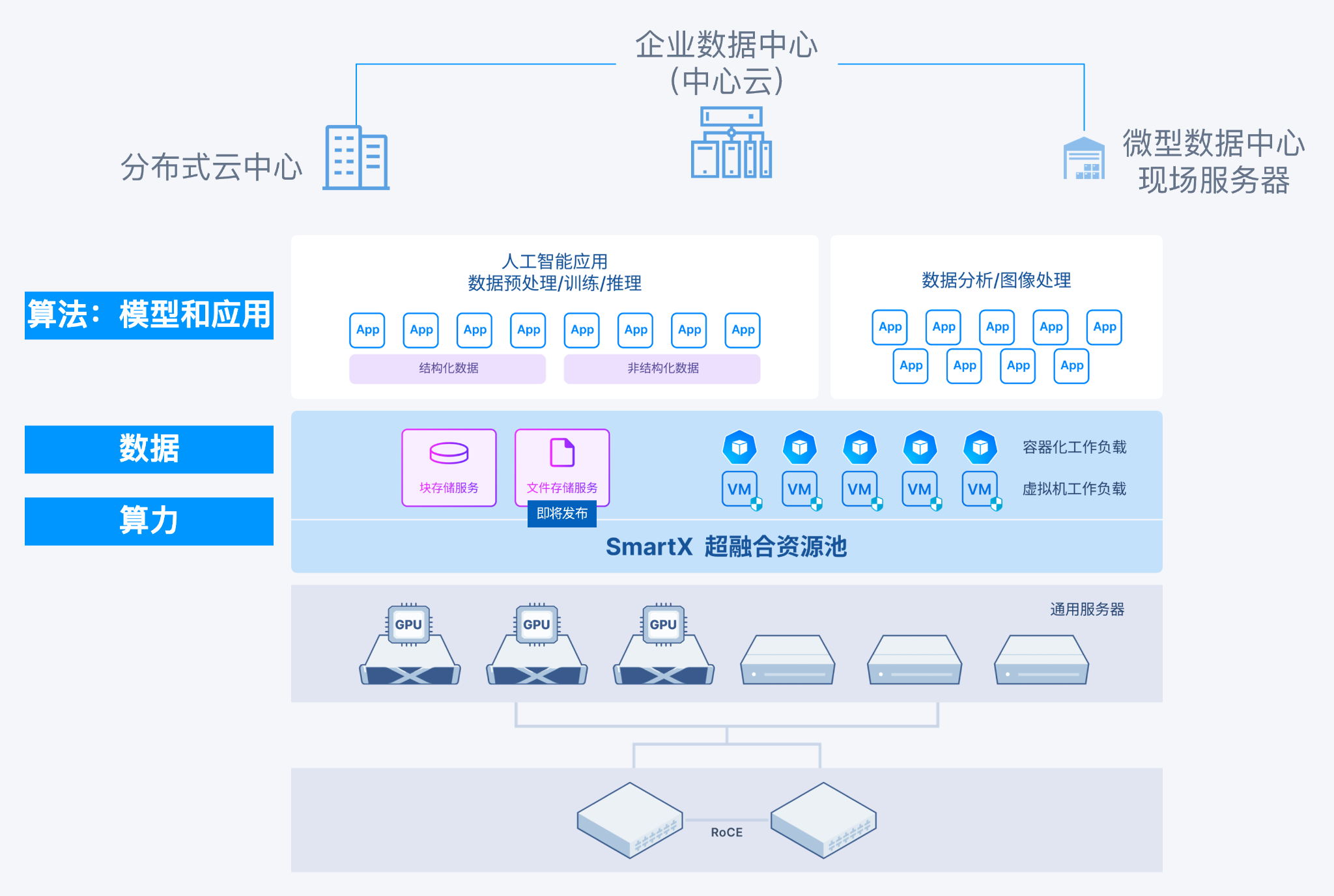
算力融合:综合计算平台灵活提供 CPU 与 GPU 资源
在基于大模型的 AI 应用不仅需要 GPU 的并行计算能力,用于生成式 AI 场景的资源池,应当综合考虑不同类型的工作任务对 CPU 和 GPU 的需求,减少不必要的跨资源池调度。SmartX 超融合集群上各种配置的服务器可以混合部署,不仅支持不同型号的 CPU,也支持每台主机上使用不同数量、不同型号的 GPU,统一为超融合架构上的 AI 应用和非 AI 应用提供计算资源。
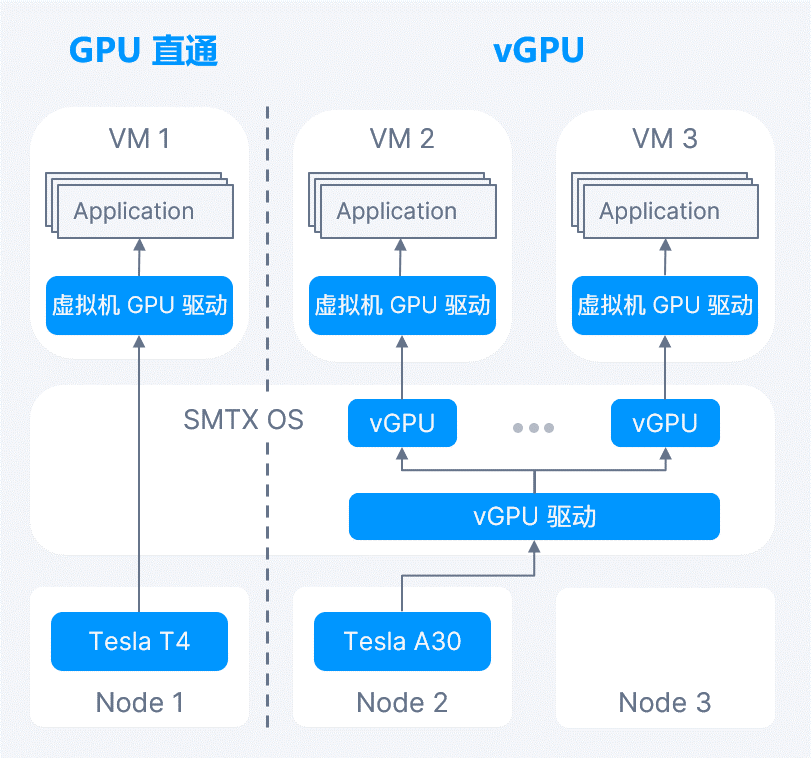
其中,在并行算力方面,SmartX 超融合支持 GPU 直通和 vGPU,为虚拟化环境中运行的 AI 应用(如人工智能、机器学习、图像识别处理、VDI 等)提供 GPU 计算资源,vGPU 功能支持用户按实际需求切分、分配不同 GPU 资源,允许多个虚拟机共享 GPU 处理能力,提升 GPU 资源利用率的同时提升 AI 应用性能。欲深入了解该功能特性,请阅读:GPU 直通 & vGPU:超融合为 GPU 应用场景提供高性能支持。
此外,NVIDIA 的 MPS 和 MIG 技术也可以在 SmartX 超融合集群上使用,用户可由此获得更加灵活的 GPU 共享使用能力。
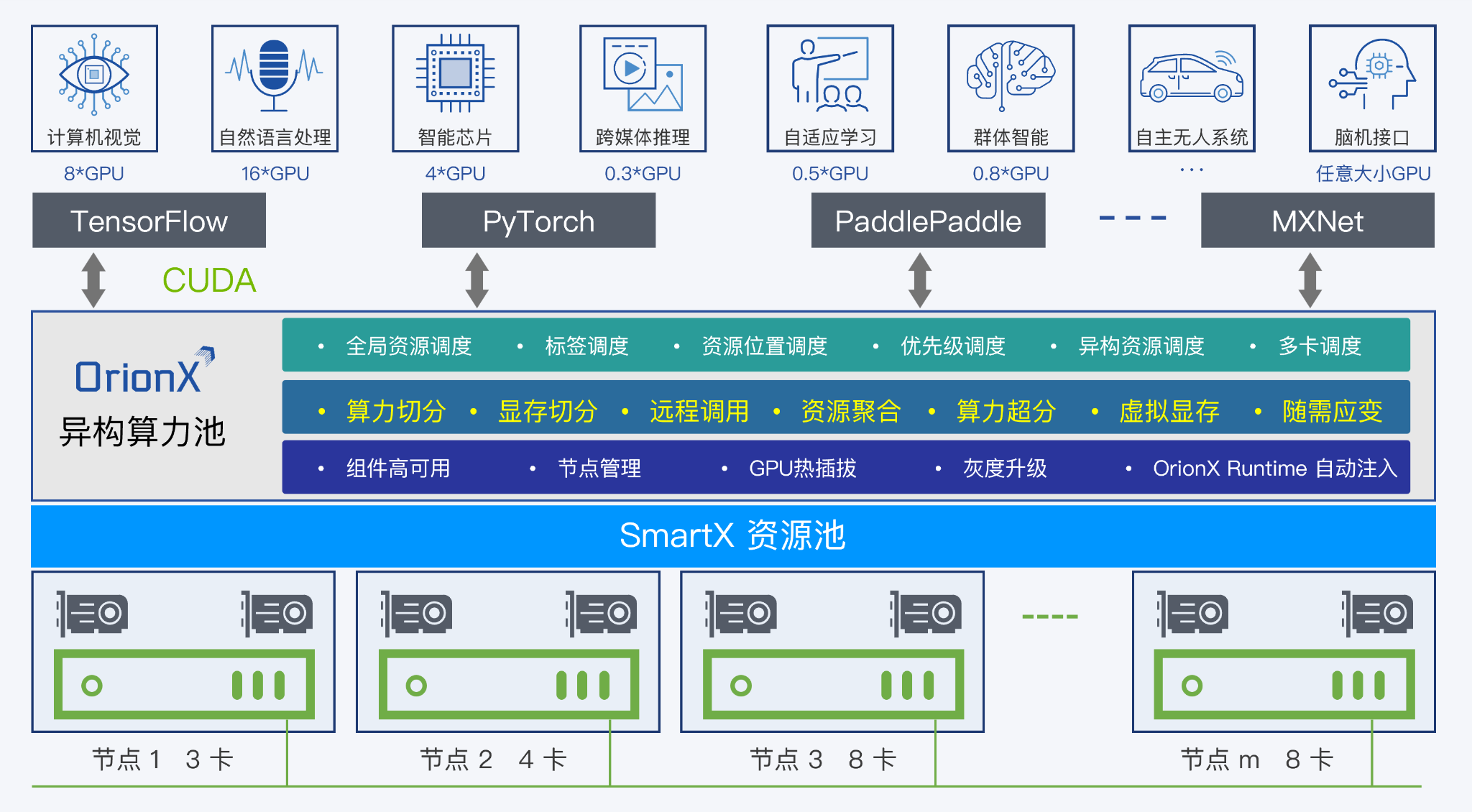
SmartX 还联合趋动科技推出了基于超融合的 AI 算力资源池解决方案,利用 OrionX 软件定义的 AI 算力池化管理和调度能力,实现 GPU 资源细粒度的切分与调度(如将一块 GPU 切分成 0.3 块,并与其他节点的 GPU 资源整合使用),同时提供异构算力芯片纳管能力,帮助企业进一步提升计算资源利用率和管理灵活性。欲深入了解该方案,请阅读:志凌海纳 SmartX 携手趋动科技推出可提供 AI 算力池化的超融合平台联合解决方案
工作负载融合:一套超融合架构统一支持虚拟化和容器化工作负载
利用 SKS,用户能够以一套超融合架构统一支持虚拟化和容器化 AI 应用。由于不同 AI 工作负载对资源的消耗模型各有特点,融合部署可以合理分配资源,同时满足不同应用对于性能、安全性、扩展性、敏捷性等方面的要求,从而提高资源利用率,降低总体成本。
目前,SKS 1.2 版本已新增对 GPU 的支持能力,包括 GPU 直通、vGPU、时间切片、多实例 GPU、多进程服务等,并支持通过 Kubernetes 的管理方法对 GPU 资源进行弹性灵活的管理,满足容器环境 AI 应用并行计算需求的同时优化了 GPU 资源使用率与管理灵活性。欲深入了解版本更新,请阅读:SKS 1.2 发布,全面增强 AI、信创等场景支持能力。

观看视频:Kubernetes AI 场景演示:SKS GPU 集群上的 Kubeflow 安装及图像识别应用操作展示
存储融合:为 AI 应用的数据处理和分析提供高性能、高可靠支持
AI 应用依赖多种类型的数据,使用过程中需要进行数据的收集、清洗、分类、推理、输出、归档等处理工作,对存储系统的压力(高速存取)可想而知。基于自研的分布式存储,SmartX 超融合可为 AI 应用提供卓越的性能和稳定性支持,通过 I/O 本地化、冷热数据分层、Boost 模式、RDMA 支持、常驻缓存等技术特性,满足 AI 应用的存储需求。
根据业务需求和经济性考虑,SmartX 超融合的存储技术可以适配各种硬件选择,无论是更经济的机械硬盘,还是性能更高的 NVMe 存储设备。比如,有一些冷数据或者温数据,读写频率没有那么高,适合下沉到低成本的机械盘;如果 AI 任务执行后遗留有大量冷数据,还可以通过复制或备份技术,将它们转移到成本更低的存储系统中。通过各种存储技术和存储设备的合理组合,可以达到系统容量、读写性能和建造成本之间的平衡。
欲深入了解 SmartX 分布式存储优势特性,请阅读:
- I/O 本地化:浅析 VMware 与 SmartX 超融合 I/O 路径差异及其影响
- 冷热数据分层:VMware 与 SmartX 分布式存储缓存机制浅析与性能对比
- Boost 模式:SPDK Vhost-user 如何帮助超融合架构实现 I/O 存储性能提升
- RDMA 支持:ZBS 的 RoCE 技术支持与业务场景性能评测
此外,SmartX 超融合还具备灵活扩展特性,支持用户根据 AI 应用使用情况按需扩容,且性能随容量同步线性提升,助力企业敏捷发展。企业也可以使用 SmartX 超融合支持边缘站点/工厂的 AI 应用,保证计算任务与所需的数据能够在同一站点、同一节点上进行处理,减少跨节点通信带来的延迟。欲深入了解该方案,请阅读:一文了解志凌海纳 SmartX 边缘计算解决方案。
整体方案优势
- 核心稳定强大:不同规模站点上的算力、存储融合部署的模式,可减少数据传输导致的延迟。高性能、高可靠的生产级存储,支持对大量非结构化、半结构化和结构化数据进行安全地保存,AI 应用可以对数据进行高性能地处理和分析。
- 架构灵活开放:支持随着人工智能业务量的增长按需扩展硬件资源。软件定义架构与硬件设备解耦,可以根据 AI 应用的特性和算力要求灵活配置并管理不同数量和型号的服务器,包括对不同的高性能处理器(如 CPU、GPU)的灵活配置和调度。
- 混合负载支持:促进各种形态 AI 工作负载的统一构建、灵活发布和及时更新。在各种站点提供融合虚拟化和容器化工作负载的一致运行环境。
- 运维简单智能:简化了基础设施的管理复杂性,提高了 AI 应用和资源维护效率。统一管理多个站点上的虚拟化、容器运行环境及其所需的计算和存储资源。
欲深入了解 SmartX 超融合支持 AI 应用场景的功能特性,欢迎下载阅读《超融合技术原理与特性解析合集》。