作者:SmartX 金融团队 张俊 熊上
目前,不少企业都在推进 VMware 虚拟化的替代,这就要求基于 KVM 技术的国产虚拟化能够提供与之对标的产品能力。其中,SmartX 原生虚拟化 ELF 经过 10+ 年的持续迭代,不仅已广泛应用于金融、医疗、制造等行业的头部企业生产环境,还将实践中积累的经验转化为更好用、更智能的产品能力,帮助用户解决日常使用与运维中遭遇的各种挑战。
本期,我们聚焦“自定义告警”功能,解读 SmartX 榫卯企业云平台如何通过“可灵活设置+细粒度提示”的告警机制,帮助企业及时发现虚拟机问题、精准快速根因并节约监控成本!
为什么需要细粒度的自定义告警功能
传统的告警机制多聚焦于主机或集群层面,虽能识别硬件故障或资源异常,却难以精准捕捉单台虚拟机的性能瓶颈、资源紧张及持续异常使用等情况,缺乏足够细粒度的识别和提示能力。这导致以下几类问题频繁出现:
1. 告警判断标准单一:虚拟机持续异常状态难捕捉
当虚拟机出现内存持续高占用、磁盘 I/O 长时间异常等持续性问题时,传统平台无法结合多个维度的监控数据进行判断并及时发出预警,往往要等业务方感知到异常后才被动处理,缺乏对“持续异常状态”的主动识别能力。
用户故事 1:磁盘 I/O 高负载潜伏 6 天,传统告警 “视而不见”
某金融客户的 VMware 虚拟化 + 第三方分布式存储环境中,因防病毒软件策略异常,部分终端代理持续重复扫描虚拟机内磁盘文件,导致磁盘 I/O 满负荷运行长达 6 天。这类 I/O 流量在存储和虚拟化层看似正常,却已严重挤占带宽,暗藏读写延迟与业务稳定性风险。但传统告警机制仅依赖瞬时阈值判断,既无法识别 “I/O 高负载持续时间”,也不能结合历史基线分析动态波动的流量。这正是典型的“正常流量中的异常行为”,也是 SmartX 建立告警体系试图解决的关键问题。
同时,这种“告警阈值统一配置”的方式,也难以根据不同业务系统对资源波动的容忍度差异进行区别设置,系统无法区分业务轻重缓急,运维人员也难以按需调优。
2. 告警显示粒度粗:阻碍故障精准 & 快速定位
传统告警机制多聚焦于主机或集群层面,告警提示范围大,用户难以根据告警信息准确定位到出问题的具体组件,影响故障根因与解决效率。
用户故事 2:分区写满告警模糊,业务中断才知问题所在
某金融客户生产环境中,一台核心业务虚拟机突发数据写入失败,引发上层应用接口频繁报错。运维人员初步判断为磁盘空间问题,但传统平台仅显示虚拟机整块磁盘使用率未满载,无法快速定位具体哪个分区耗尽空间。运维人员只能登录虚拟机内部排查,不仅陷入被动,更导致业务中断。这暴露出传统平台存在告警粒度粗、响应滞后的问题,也由此推动 SmartX 自定义告警开发分区可视化能力。
3. 监控成本高:授权收费模式制约业务扩张
企业的 IT 资源不是静态的数字,而是支撑业务创新的动态载体。如果监控工具的授权模式束缚了资源的灵活伸缩,就会变成业务发展的 “隐形枷锁”。多数第三方监控工具采用 “按虚拟机数量授权” 的收费模式,当企业虚拟机规模从数十台增至数百台时,监控成本会同步飙升。
用户故事 3:数百台虚拟机扩容,误认为监控费上涨是常态
某金融客户部署 SmartX 超融合架构初期选用第三方监控工具进行虚拟机运维管理。随着业务规模扩大,虚拟机数量从最初的数十台快速增至数百台,客户逐渐发现第三方工具按单台虚拟机授权收费的规则,导致监控成本随资源扩容同步上升。随着业务持续扩张不断累加,监控费上涨与客户“降本增效”的战略目标愈发相悖,甚至让业务部门在规划资源扩容时产生了顾虑。
在此之前,客户并非没有意识到成本压力,但由于市场上多数监控工具都采用类似的按节点收费模式,用户一度认为 “监控成本随虚拟机数量增长” 是行业常态。
在规模化、多租户环境中,上述问题会被进一步放大。尤其是在金融、政企、研发测试等混合型场景下,运维团队迫切需要一种既能精准监控虚拟机运行状态,又能灵活配置规则与通知策略的告警能力,以提升整体运维效率与服务质量。SmartX 基于上述诉求,帮助企业打造适配多种业务场景、真正“以业务为中心”的智能告警体系。
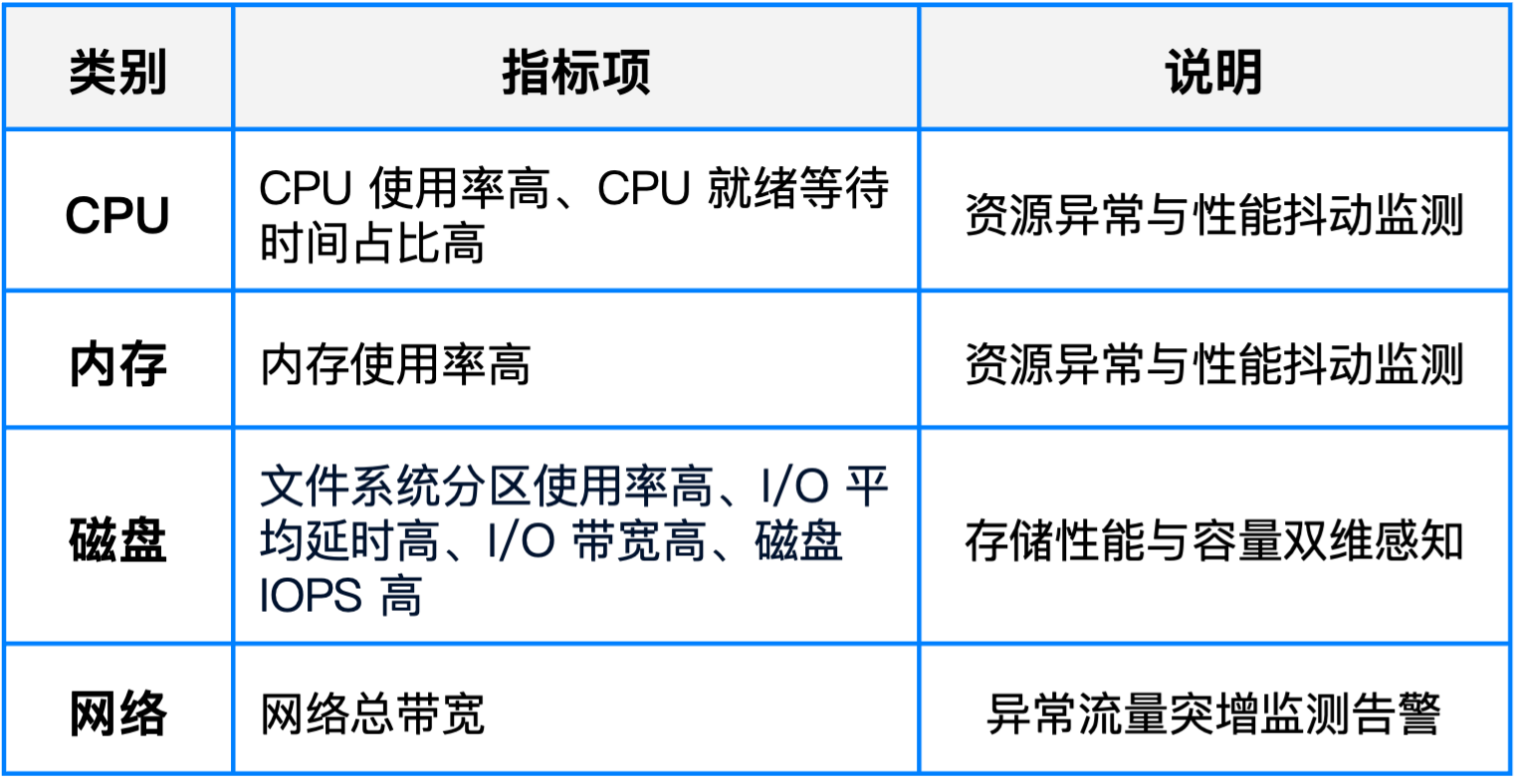
SmartX 自定义告警规则:支持虚拟机级自定义告警设置
基于 CloudTower 的可观测性平台提供“自定义告警规则”能力,以虚拟机为核心对象,提供细粒度、多维度的告警配置功能。
- 支持为单台或多台虚拟机分别配置指标类告警规则。
- 每条规则可灵活设定告警等级(信息/预警/严重)、触发阈值、持续时间条件、通知策略等。
告警维度
以上告警规则均支持图形化配置,所有策略均可在 CloudTower 界面统一管理,告警结果可多渠道通知(系统提示、邮件、webhook 等)。
创新点与产品对比

业务价值与客户收益
通过 CloudTower 提供的自定义告警功能,企业可全面增强 IT 运维体系,实现更精准的监测、更及时的响应与更智能的决策:
- 提升效率并降低风险:从“出问题再处理”转变为“异常前预警”,大幅减少人工巡检频次,提升运维响应速度;避免因资源瓶颈未及时发现而导致的业务中断,如高内存、高 I/O、分区写满等典型问题。
- 增强风险可视性:支持 CPU、内存、磁盘 I/O、分区使用率、网络带宽等多项资源指标监控,告警维度更细致、风险识别更及时,提前预警风险,减少排查时间。
- 提升监控灵活性:支持按虚拟机/虚拟机组/集群设置告警规则,支持自定义阈值、持续时间、告警等级与通知策略,灵活匹配不同业务需求。
- 打通配置与观测闭环:告警触发后可结合 CloudTower 的其他能力(如分区可视化、远程配置、快照回滚)实现快速定位与闭环处置。
用户故事 1 后续:持续高负载难察觉?组合判定方式主动识别潜伏性问题
引入 SmartX 可观测性平台后,用户借助“自定义告警”能力,根据自身实际情况添加了基于虚拟机的自定义告警规则:当某虚拟机 I/O 带宽达到过去 7 天平均值的 2 倍且持续 5 分钟,即触发告警。如此一来,平台即可第一时间识别并推送异常提醒,帮助运维快速定位到异常虚拟机并及时处理。
依托 SmartX 自定义告警机制“阈值 + 持续时间 + 历史基线”的组合判定方式,潜伏性问题也能被平台主动发现,用户无需人工长时间观察,即可自动发现潜藏在“正常流量”背后的资源异常,真正实现从被动排查到主动预警的转变。
用户故事 2 后续:业务中断才能发现问题?“告警+可视”提前化险为夷
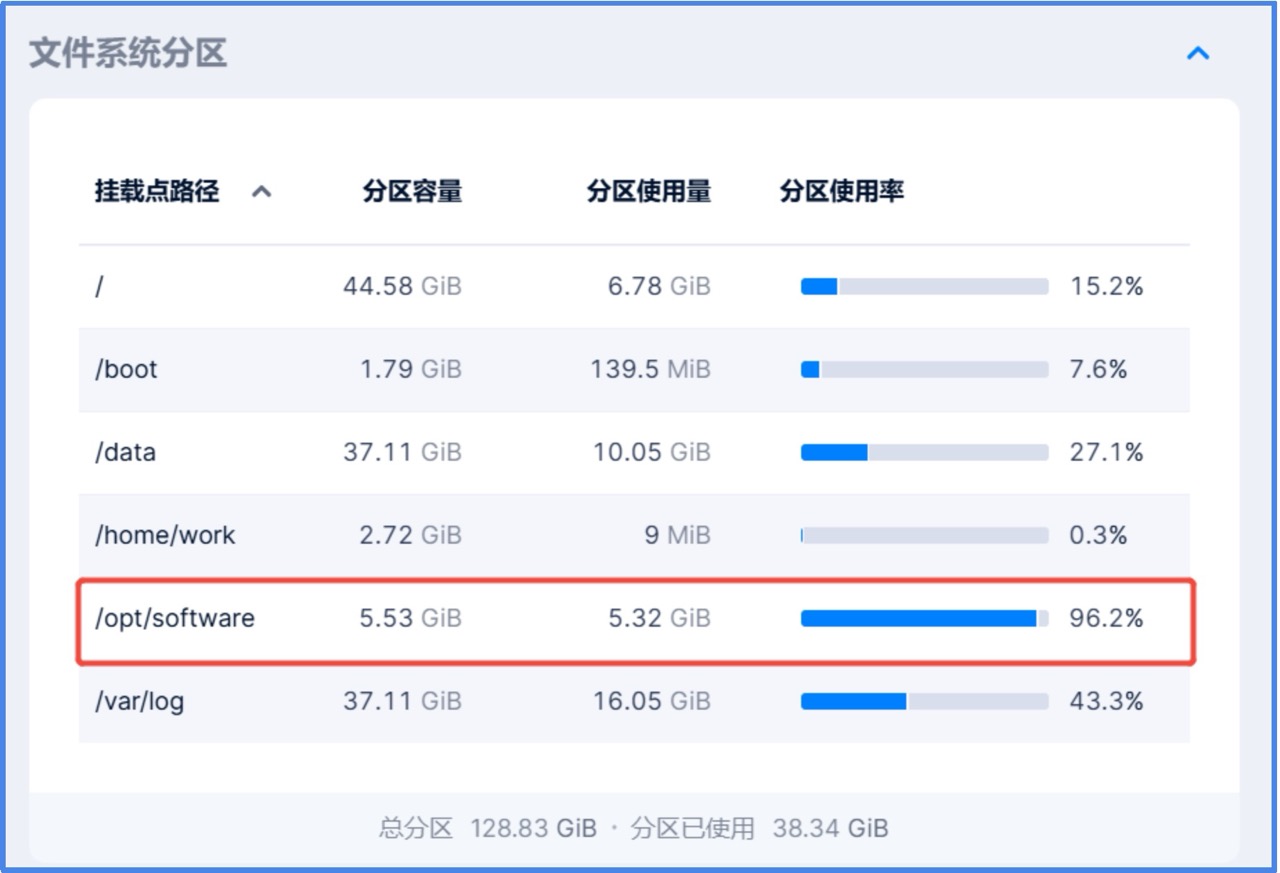
客户在 CloudTower 启用自定义告警功能,提前配置了针对虚拟机文件系统分区使用率的阈值告警策略:当任一分区使用率超过 90% 且持续 5 分钟,即触发预警。随后通过 VMTools 提供的文件分区可视化能力,管理员无需登录客户机,便可直观查看每个挂载点的使用详情,迅速定位到 /opt/software 分区空间紧张。
由于该挂载点正是业务数据写入目录,若持续堆积将直接导致写入失败。借助可观测性平台“告警”与 VMTools 的“可视”组合能力,运维人员在问题发生前即完成风险识别与处理,仅用数分钟完成分区扩容与服务保障,避免了更大范围的业务影响。

用户故事 3 后续:监控授权“越用越贵”?SmartX 可观测性服务突破成本上升困局
引入 SmartX 榫卯超融合后,客户彻底摆脱了“监控成本随虚拟机数量增长”的问题。SmartX 可观测性平台内置于 CloudTower,无需额外收费,且监控可覆盖整个超融合集群的所有资源。部署完成后,无论客户创建多少台虚拟机,监控功能都能实时覆盖,既满足了业务快速扩容的需求,又彻底终结了监控成本随资源增长的恶性循环,首年就为客户节省了超过 90% 的监控支出,后续随着虚拟机数量持续增加,节省的费用还在不断累积。
配置实践:简单易用
在 CloudTower 统一管理平台上,可以将虚拟机作为报警对象,并配置虚拟机指标告警,为运维人员提供直观、灵活、可扩展的配置体验,打造一套真正“能看懂业务、听得见异常、喊得对对象”的智能告警体系。配置流程清晰、操作便捷、可读性强,具体操作包括:
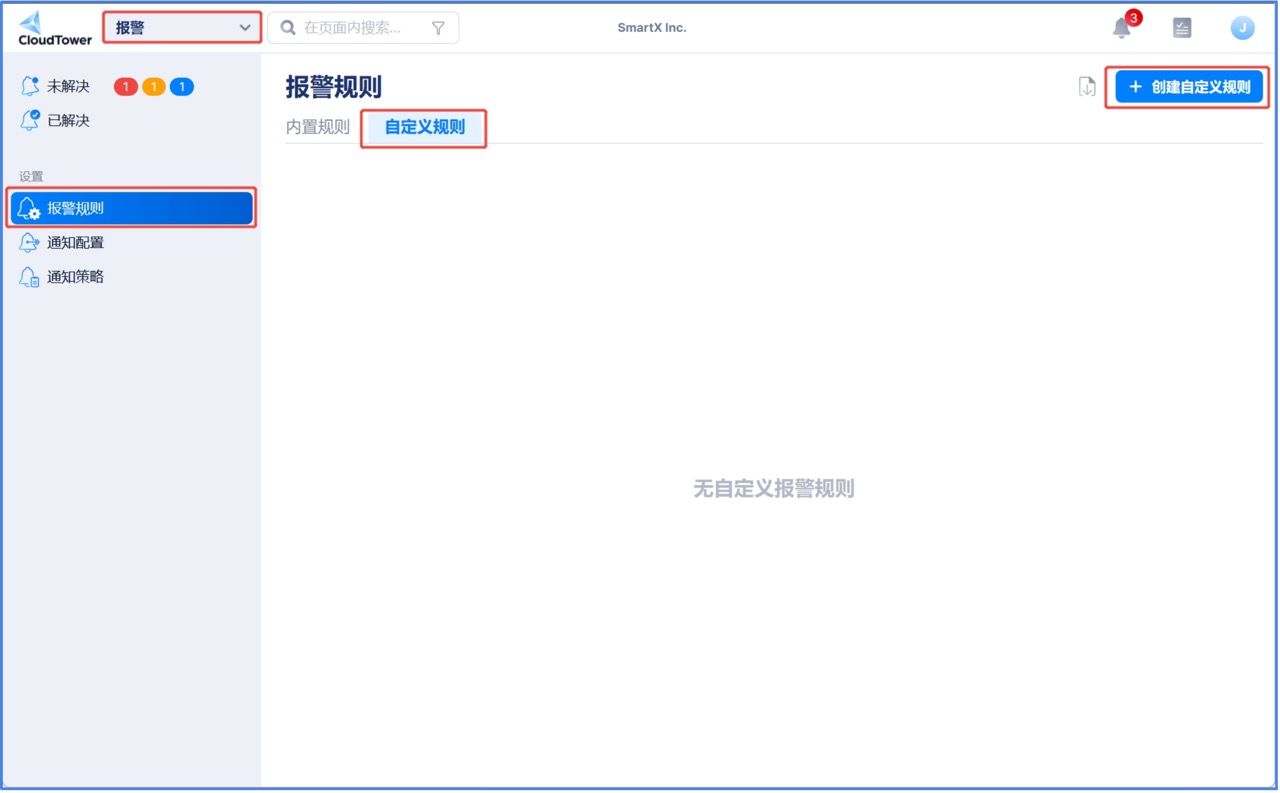
1. 在 CloudTower 的报警主界面左侧的导航树单击报警规则,然后在报警规则界面单击自定义规则。
2. 在自定义规则界面右上角单击创建自定义规则,将弹出创建自定义报警规则对话框。
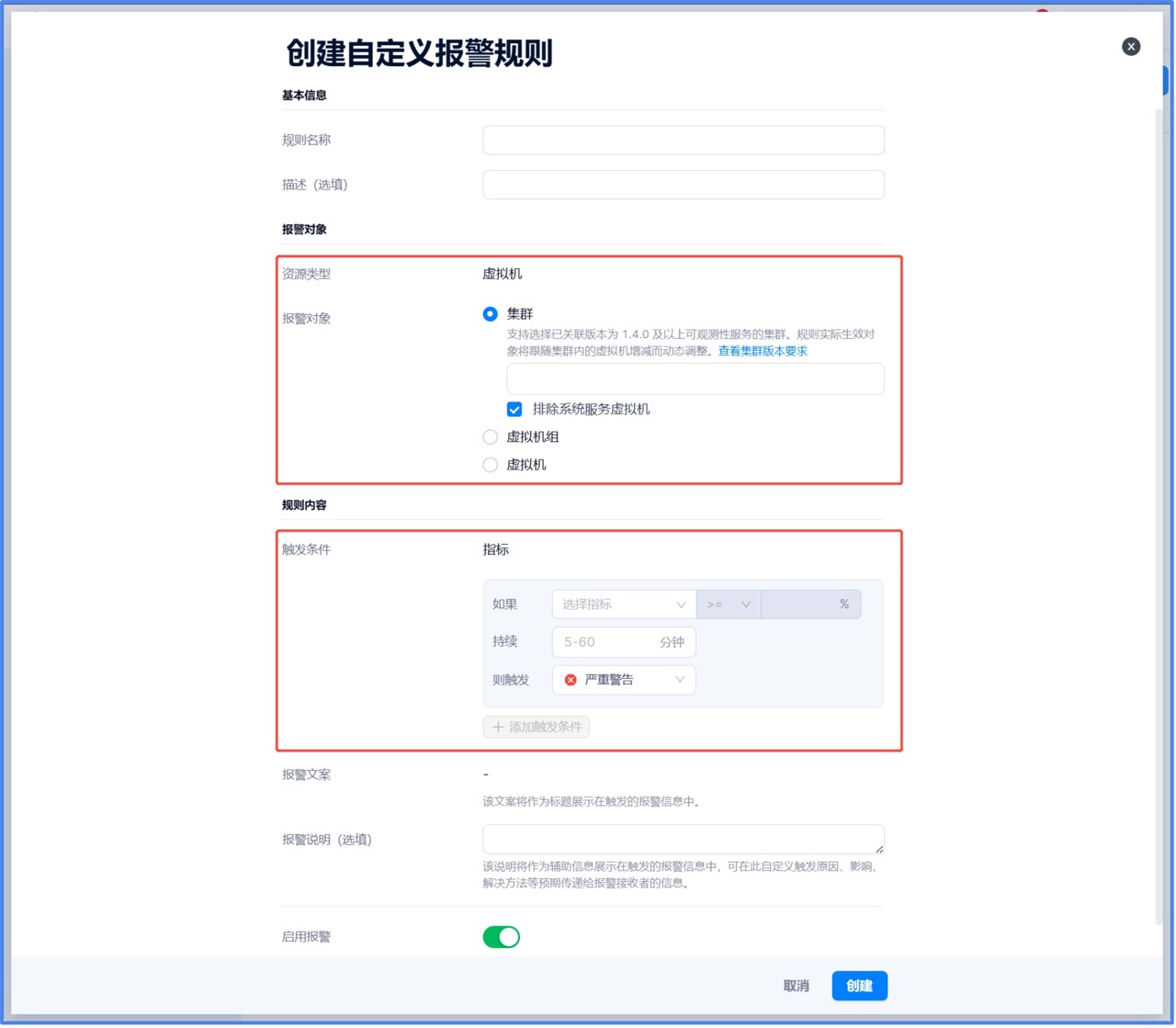
3. 其中针对虚拟机指标支持以下配置选项:
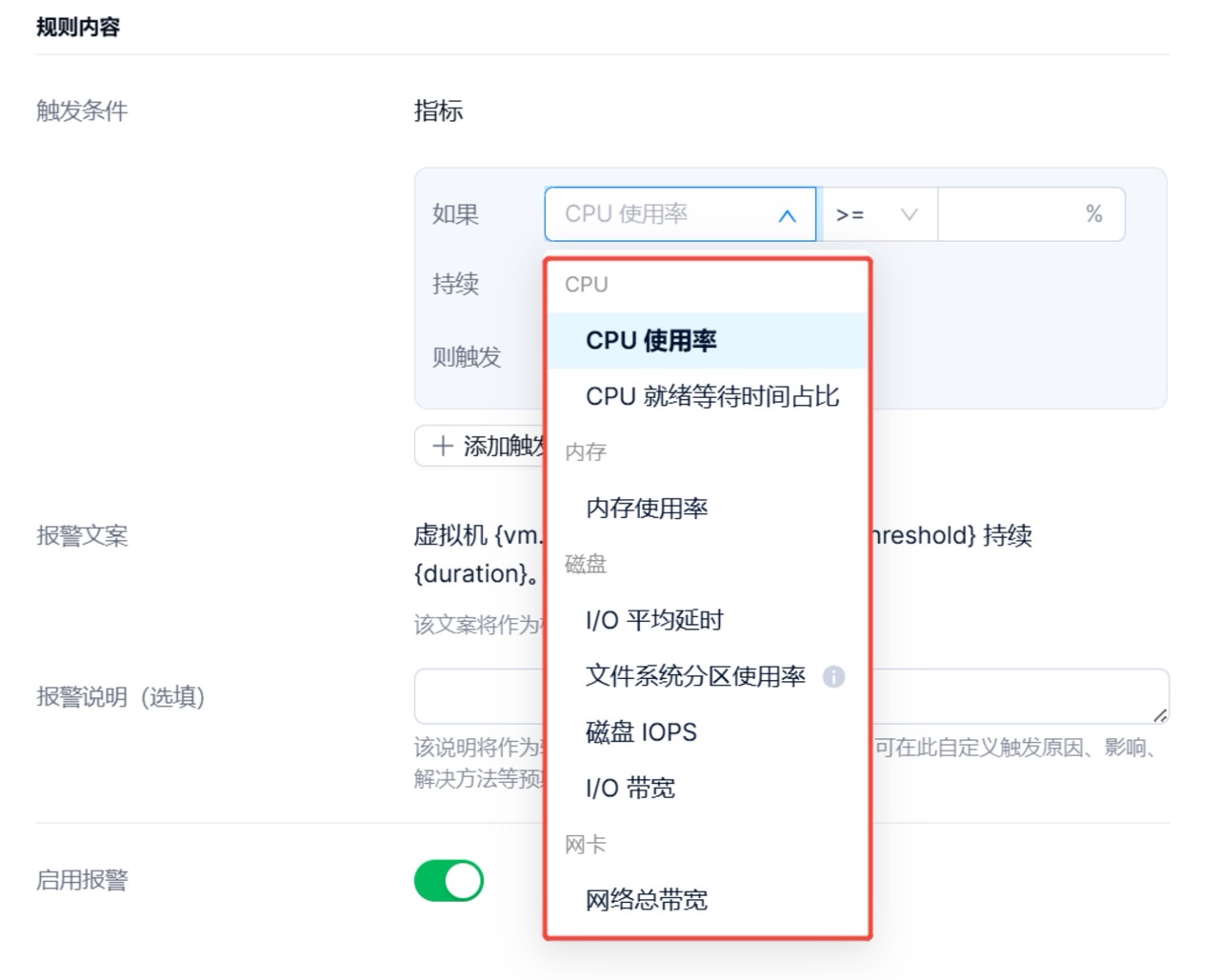
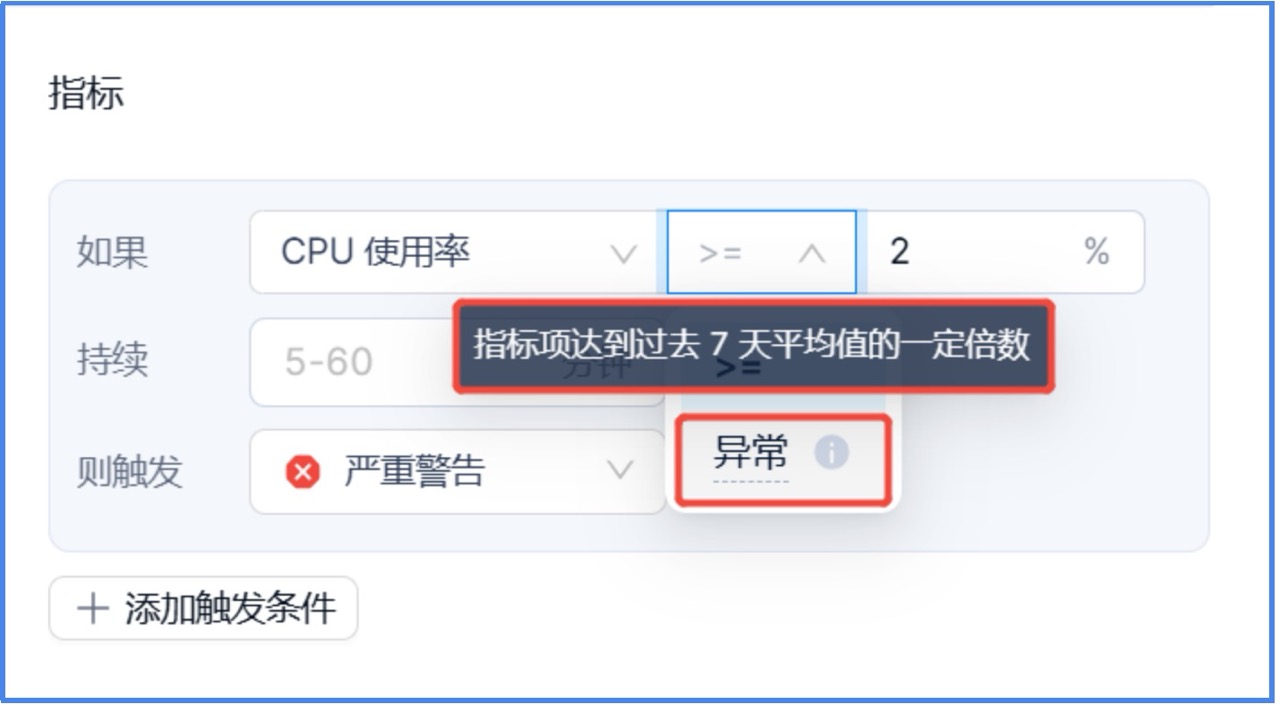
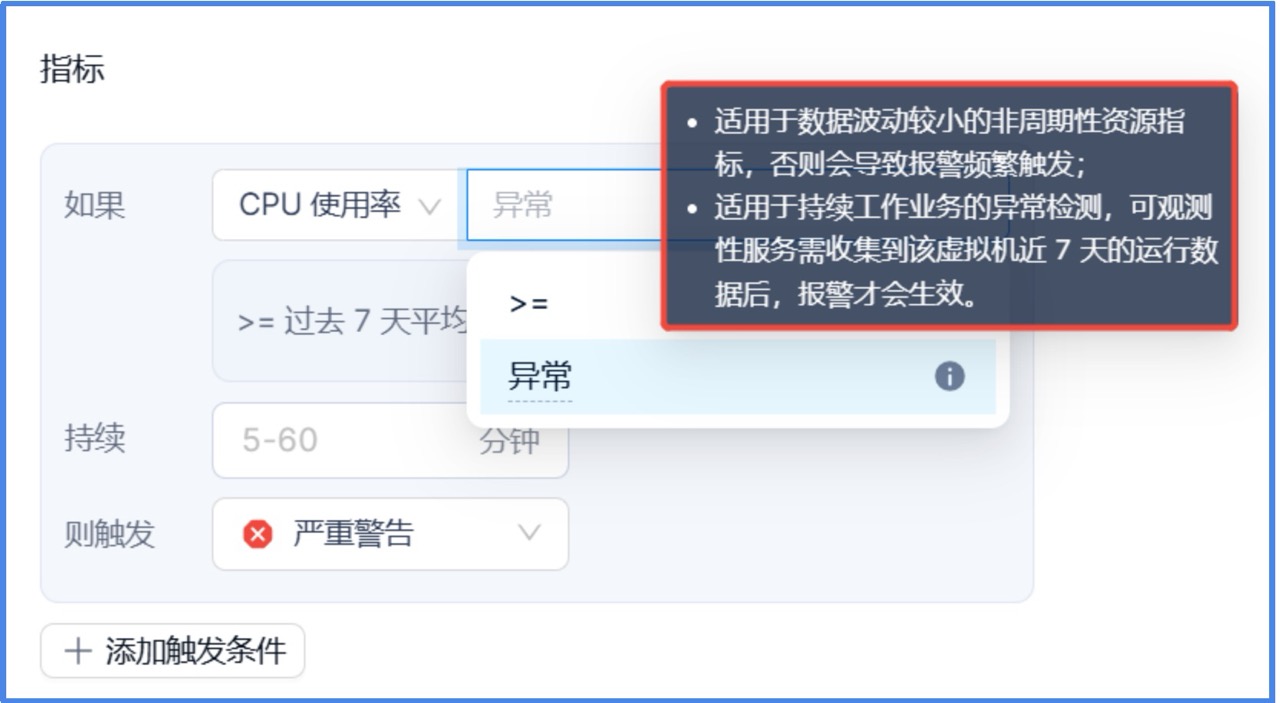
4. 除了支持监控指标高于指定使用率,还支持”异常”判断。对于不同用户业务的压力可能无法得知具体的性能基线,而通过配置“指标项达到过去 7 天平均值的一定倍数,且持续 N 分钟时,触发相应的告警“,可避免大量的手动操作。
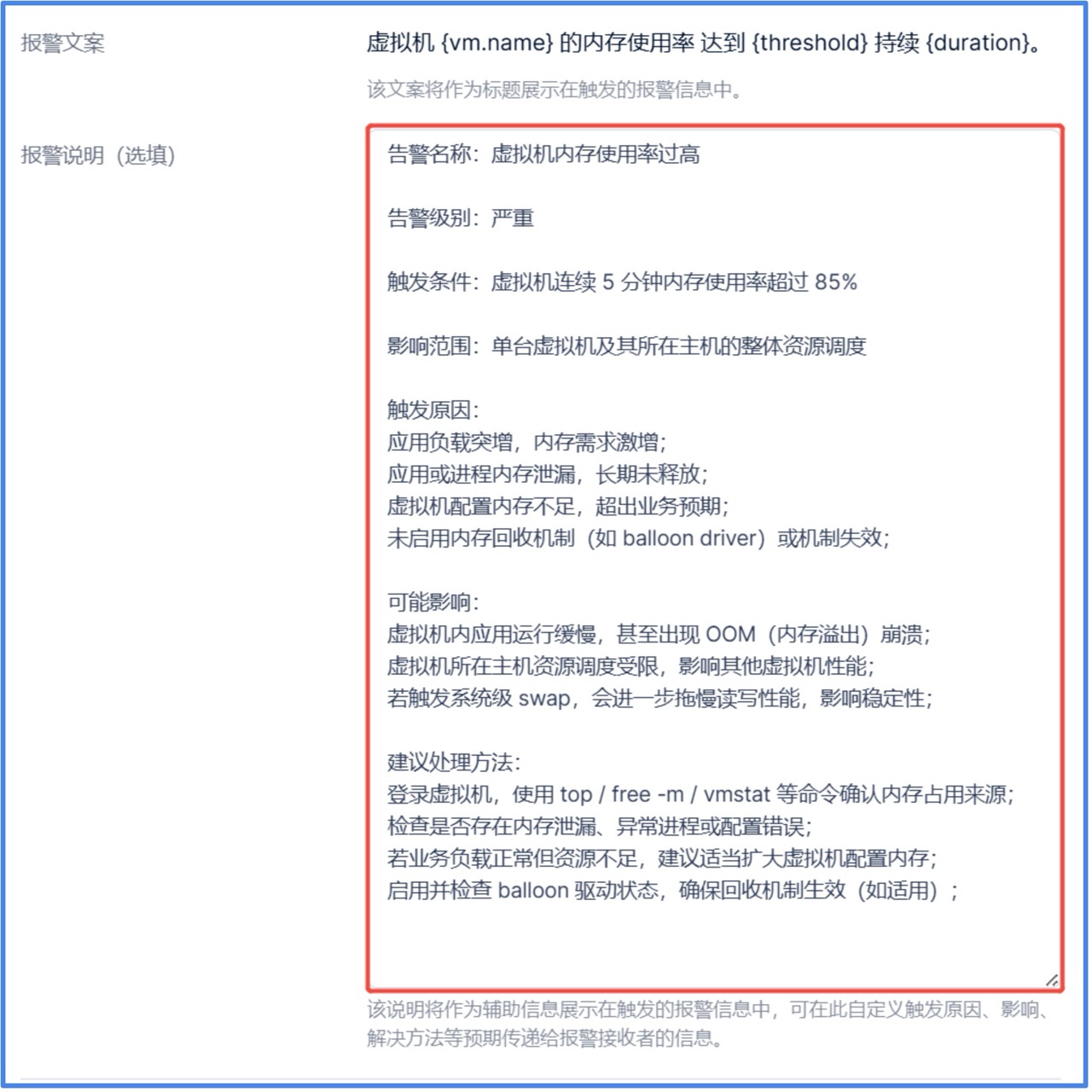
5. 支持对告警编辑报警说明,作为辅助信息展示在触发的报警信息中,可在此自定义触发原因、影响、解决方法等预期传递给报警接收者的信息。
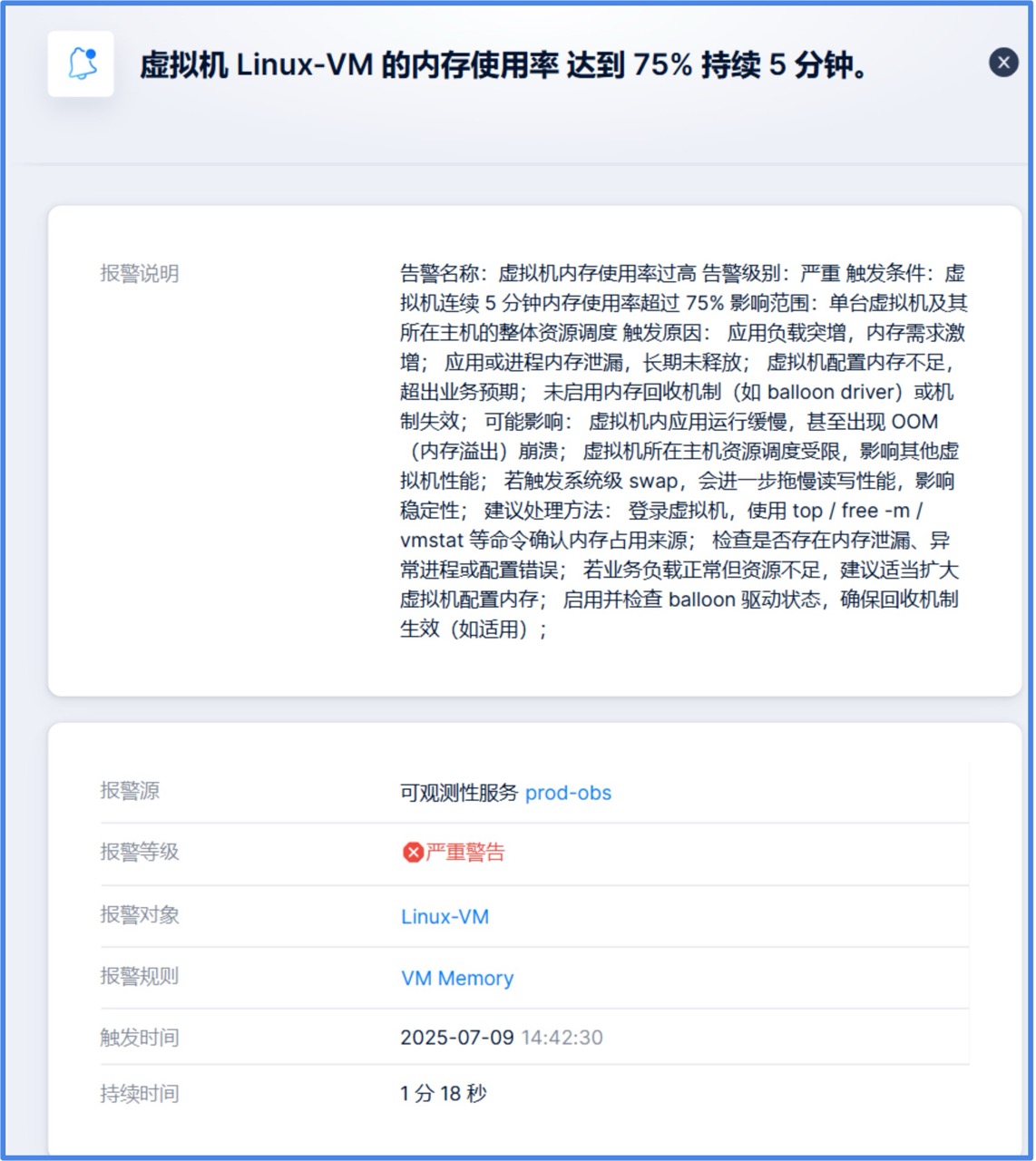
更多参考:更详细的安装与配置指南,请联系 SmartX 技术支持或查看产品文档 https://docs.smartx.com/
欲了解更多 SmartX ELF 虚拟化及榫卯企业云平台核心功能,欢迎点击链接获取电子书《SmartX ELF 虚拟化核⼼功能集》!
推荐阅读:
业务视角下的集群升级中心:三键实现全自动升级,用时缩短 70%!
业务视角下的主机维护模式:三重自动化,提升运维效率与业务连续性
业务视角下的虚拟化特性|内容库:灵活的模板分发让基线管理更便捷