2026 年 3 月 24 日——志凌海纳 SmartX 正式发布榫卯超融合 6.3 版本。该版本在业内率先基于超融合架构提供同步复制容灾(RPO=0)及 RDMA 存储网络跨网卡高可用、SR-IOV 高可用等高性能业务连续性保障能力,并通过底层架构的深度演进,充分发挥高速存储网络与存储介质优势,提供三节点集群千万级 IOPS 和百 GB 带宽性能。
配合同步发布的无代理杀毒、国密算法加密等安全合规特性,榫卯超融合 6.3 可提供超融合架构下对关键业务承载业内最全面的支撑能力。
发布背景
当前,企业面临降本增效、硬件涨价与 VMware 替换等诸多挑战。尤其在成本投入最高昂的关键业务场景,相比传统的物理机/VMware + 高端全闪阵列的三层架构方案,国内主流云基础架构产品往往难以同时在极致的高性能低延迟、高可用和容灾等关键能力上对齐,无法发挥其在成本、运维和弹性扩展等方面的价值。
榫卯超融合 6.3 通过高可用、容灾、性能和安全合规等能力的全面跃升,在业内率先提供关键业务场景完整的支撑能力,为用户大幅降低 TCO 提供真正可行的替代选项。
关键生产业务高可用能力:高速网络与高速虚拟化设备高可用支持
榫卯超融合 6.3 重点为关键业务高性能场景技术栈提供更完整的高可用保障,让用户兼得关键业务所必须的高性能和高可用能力。
- RDMA 存储网络跨网卡高可用:通过引入 RDMA 存储网络跨网卡绑定技术,构建高可靠存储网络冗余路径,在提升存储网络带宽的同时,从物理链路层面夯实超融合集群的底层容错能力与可用性基础。
- SR-IOV 网卡高可用:挂载 SR-IOV 网卡的虚拟机支持启用 HA。低延迟金融交易等业务在利用高性能网络设备时,如遭遇物理主机故障,可有效缩短停机时间,快速恢复运行,保障业务连续性。
- 海光 HCT(Hygon Cryptographic Technology)设备高可用:HCT 等 CPU 加密技术因更高加密性能和更低加密成本被广泛应用在国密改造等场景中。针对采用 CPU 加密能力的安全性业务,榫卯超融合 6.3 新增对使用了 HCT 设备的虚拟机 HA 支持,确保合规类负载的连续运行。
同时,榫卯超融合 6.3 还提供了 vGPU 高可用能力,对 AI 、VDI 等场景提供业务连续性保障。
关键生产业务容灾能力:原生同步复制与管控平台容灾
榫卯超融合 6.3 针对金融、医疗等行业对数据高度一致性的需求,提供了原生同步复制(RPO=0)、管控平台自动切换等增强特性,有效降低传统双活架构对昂贵外部存储阵列的依赖,在实现核心业务实时数据保护的同时,优化容灾建设的成本与运维复杂度。
- 虚拟机级同步复制实现 RPO=0:在已经具备拉伸集群双活能力的基础上,榫卯超融合 6.3 在国内率先提供以虚拟机为粒度的 RPO=0 原生同步复制能力。相比双活拉伸集群,同步复制无需对整个集群进行保护,可自动容忍容灾网络抖动,降低对网络资源占用,并可实现故障转移和容灾演练。
- 管控平台高可用:配合 CloudTower 管控平台高可用能力,榫卯超融合 6.3 不仅可以保障数据平面的连续性,更能实现跨站点管理平面的自动故障切换,提供更完整的容灾保障。
此外,榫卯超融合 6.3 将跨站点双活集群的构建门槛由传统的 6 节点优化至 4 节点起步,降低双活建设成本,并提供放置组可用域规则,确保应用在双活可用域中的部署和切换符合业务要求。
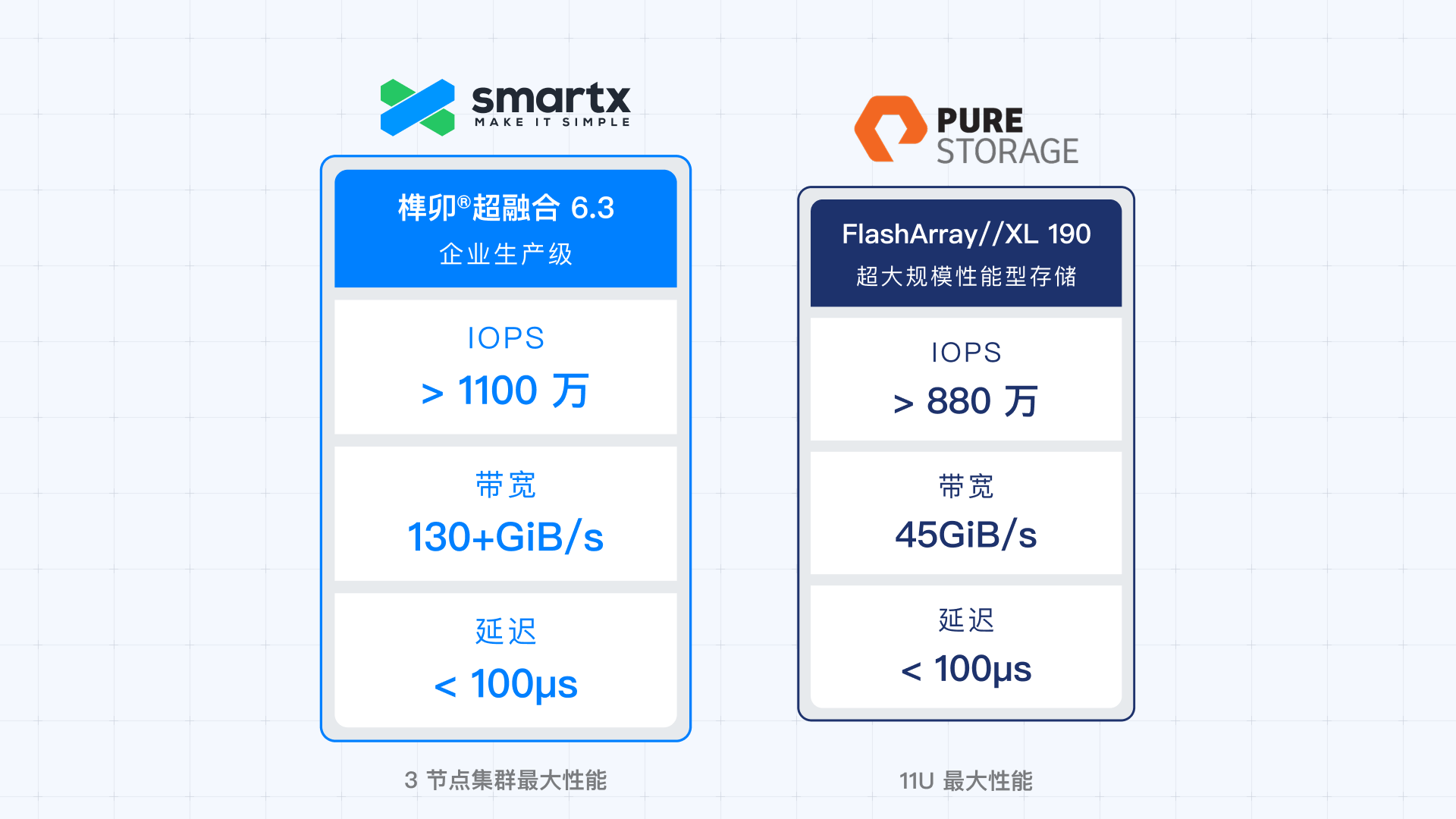
关键生产业务存储性能:突破千万级 IOPS 与百 GB 带宽,对标高端全闪阵列
榫卯超融合 6.3 通过架构级的深度演进,充分发挥高速存储介质与高速存储网络能力,有效应对核心数据库等业务对存储 I/O 延迟与并发的严苛要求。
榫卯超融合 6.3 深度集成 Intel DSA(数据流加速)、内核高性能异步 I/O 框架(IO_uring)、多存储实例与磁盘组,以及 RDMA 高速存储网络多链路聚合等技术,结合已有的条带化与 Boost 模式,实现存储效率的跨越式提升。
在标准 Intel 3 节点集群的性能实测中,榫卯超融合 6.3 的 I/O 吞吐能力已可比肩高端全闪阵列,较 6.2 版本实现数倍增长:
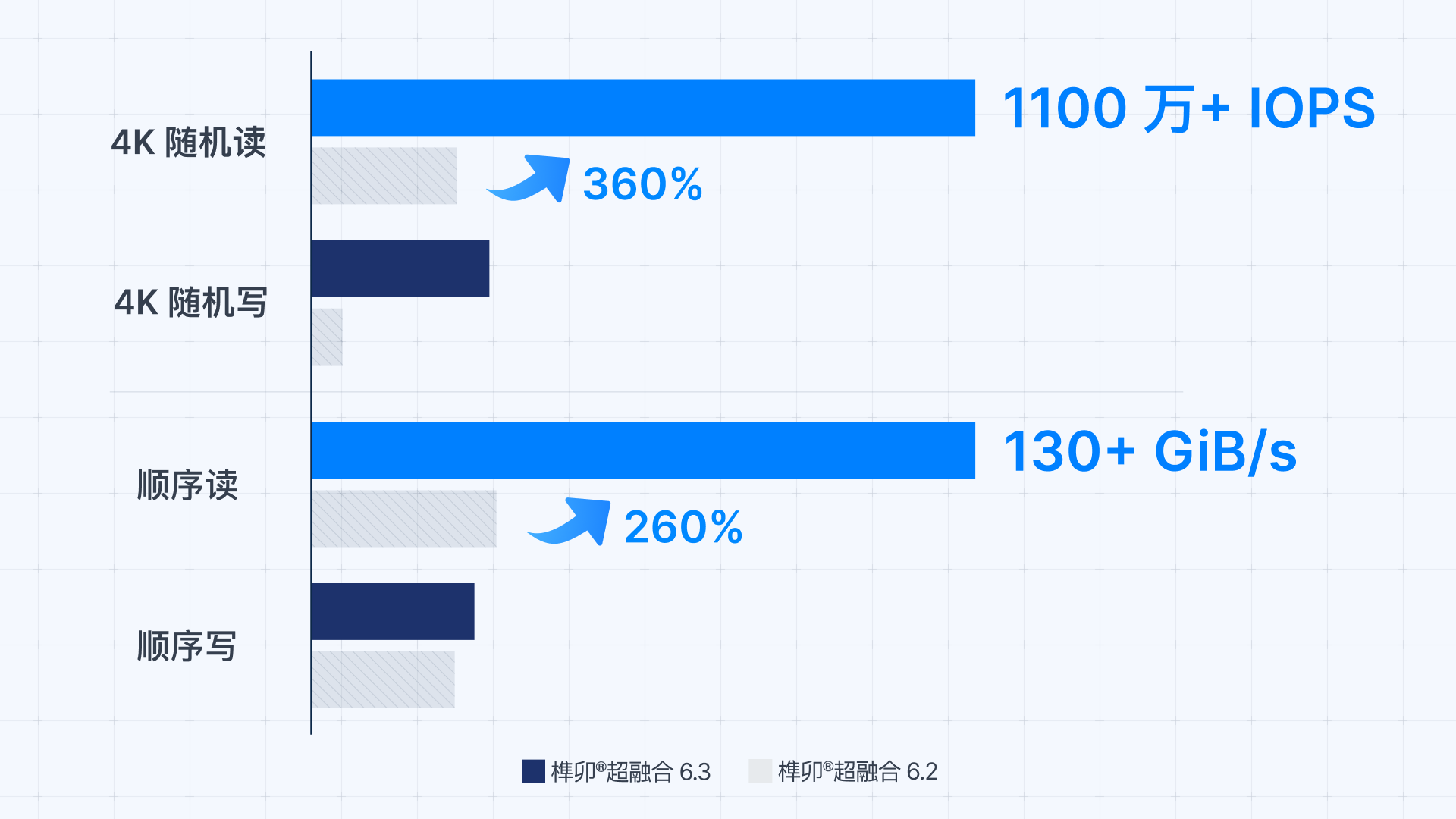
在海光与鲲鹏平台的测试中,榫卯超融合 6.3 同样展现了卓越的信创适配与加速能力。通过对国产 CPU 架构的深度底层优化,较 6.2 版本实现了数倍的性能提升:4K 随机读写性能提升达到了 350% 至 570%,顺序读写吞吐量也实现了 50% 至 200% 以上的增长。
*性能数据基于内部特定硬件配置(涵盖 Intel、海光、鲲鹏平台,3 节点集群,100Gb/200Gb 存储网络,榫卯超融合 6.3 + 4 存储实例)的测试结果;实际结果可能因系统环境、工作负载和硬件规格而异。性能提升幅度是与 6.2 版本基线对比得出的。此配置代表测试中的最高性能层级。
- 软硬协同的 I/O 路径优化:深度集成 Intel DSA(数据流加速)硬件引擎,将原本消耗 CPU 资源的内存拷贝任务卸载至专用硬件,并结合内核 IO_uring 异步框架与 RDMA 高速网络多链路聚合技术,有效降低高并发环境下的系统调用开销与处理延迟。
- 多实例架构支撑高吞吐需求:支持在单节点内配置多个物理盘池与存储实例,结合已有的条带化机制与 Boost 模式,显著提升存储底层的并行处理效率,有效承载核心数据库及高密度计算任务产生的瞬时大流量 I/O,为关键业务提供高并发性能支撑。
- 金融高性能、低延迟业务支撑能力优化:基于金融高频交易、行情分发等场景的实际客户需求反馈,提供组播、虚拟机网卡队列长度、队列数量调整等多项特性,满足业务高性能、低延迟需求的同时,降低网络高负载风险。
安全合规能力:无代理杀毒防护与国密算法支持
榫卯超融合 6.3 通过内生安全架构,深度集成无代理杀毒、国密算法支持、内置密钥管理服务(KMS)及热迁移流量加密等能力,以更优化的架构、更低的建设和运维成本,满足关键基础设施行业对数据加密与合规审计的严苛要求。
- 无代理杀毒防护:支持无代理杀毒架构并和亚信安全形成联合解决方案,有效提升大规模云主机环境下病毒防护的及时性,降低防护运维成本。
- 国密支持与内置 KMS:原生支持基于国密算法的虚拟机磁盘加密,并提供内置 KMS 服务以简化密钥全生命周期管理。
同时,榫卯超融合 6.3 引入虚拟机热迁移流量加密机制,确保核心数据在静态存储及业务迁移过程中的机密性与合规性。在网络层面,榫卯超融合 6.3 提供 ERSPAN 网络流量镜像能力,满足网络运维和安全审计要求。
信创生态支持:深度适配,打造更高性能和灵活的国产化底座
榫卯超融合 6.3 针对国产化基础设施建设中的重载业务承载难题,完成了对鲲鹏等国产 CPU 平台的深度适配优化。通过提升虚拟机配置上限与支持异构节点热迁移,解决信创转型过程中核心应用性能受限及硬件演进困难等痛点。
- 突破计算规格限制:提升鲲鹏平台单台虚拟机的资源分配上限,最高可支持 512 vCPU 与 1 TiB 内存,为原本运行在物理机上的核心数据库等计算密集型业务提供了等效的虚拟化承载能力。
- 信创架构间的平滑演进:针对国产 CPU 同代际下的跨型号迁移需求,支持鲲鹏平台异构节点间的实时热迁移。该能力确保企业在进行国产化硬件更新或集群规模动态调整时,具备更灵活的选择,降低架构更迭的运维风险。
敏捷运维能力:化繁为简,护航大规模集群
榫卯超融合 6.3 引入 VMTools 组件批量升级、迁移路径优化等智能化运维特性,降低大规模集群在日常维护与跨集群迁移中面临的应用配置失效及网络中断风险,提升复杂环境下的运维确定性与变更效率。
- VMTools 批量升级:无需进入操作系统即可一键升级虚拟机工具,并支持在界面选择多台虚拟机完成一键批量升级,降低重复手动操作。
- 跨集群迁移效率优化:非 Boost 模式下跨集群热迁移仅迁移有效数据,减少网络带宽占用和磁盘数据迁移耗时。
- 集群 NTP 强制同步与异常快速定位:简化 NTP 的配置和使用方式。
- 多级虚拟机组:为复杂业务架构和虚拟机之间提供更清晰的映射关系,实现更高效的资源管理和批量操作。