跳转到您所在的国家或地区
我们建议您访问当前所在地的网站,了解针对您所在的国家或地区提供的产品与服务。
我们根据 IP 地址判断大致位置。若您正通过代理服务器访问,则位置可能与实际不同。隐私政策
留在 HK & Macao (English) 站点
内置对文本生成、Embedding、Reranking 等主流模型类型的支持,满足丰富的企业级应用场景。
可从 Hugging Face 一键拉取开源模型,也支持上传自定义模型,便于企业使用自研或第三方模型。
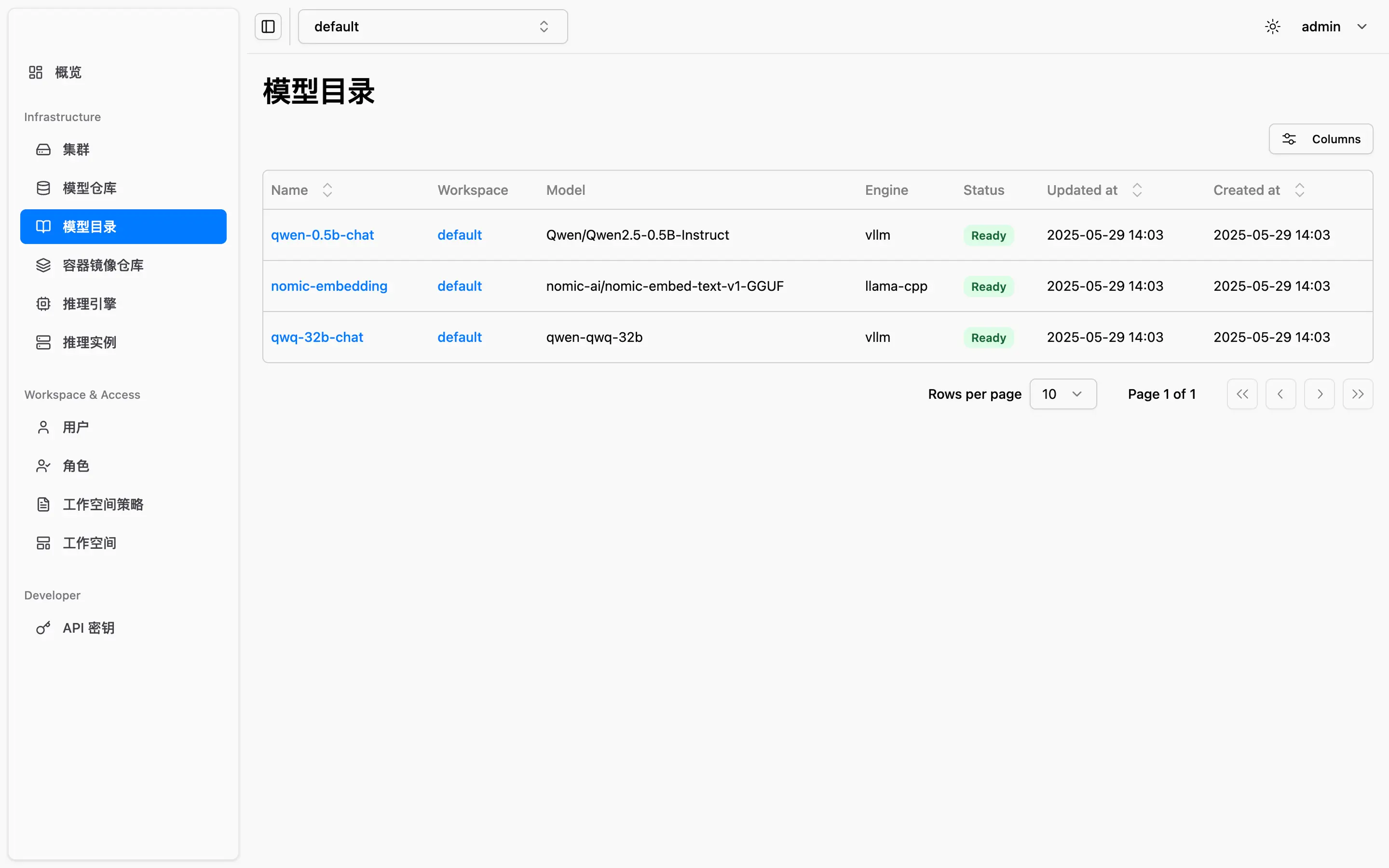
通过模型目录功能,预设推理引擎、资源规格与运行参数,实现模型部署标准化,降低运维成本。
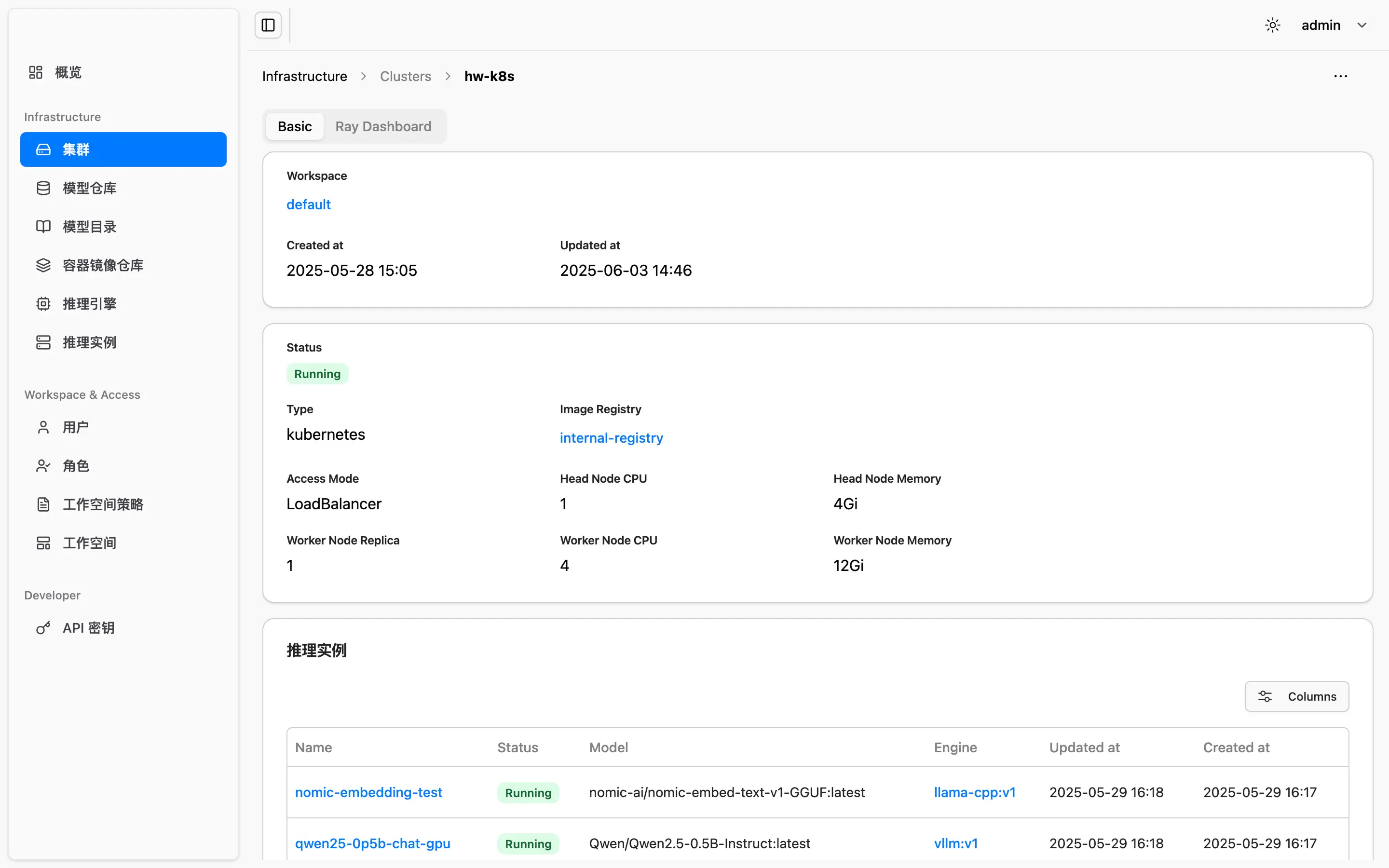
支持将来自不同厂商(如 NVIDIA、昇腾等)的 GPU 统一纳入平台管理,实现资源统一调度。支持多种算力运行环境,如虚拟机/物理机和 Kubernetes 集群。
多模型实例可共享同一张 GPU,通过智能分片与隔离技术,有效避免算力浪费,提升总体吞吐。
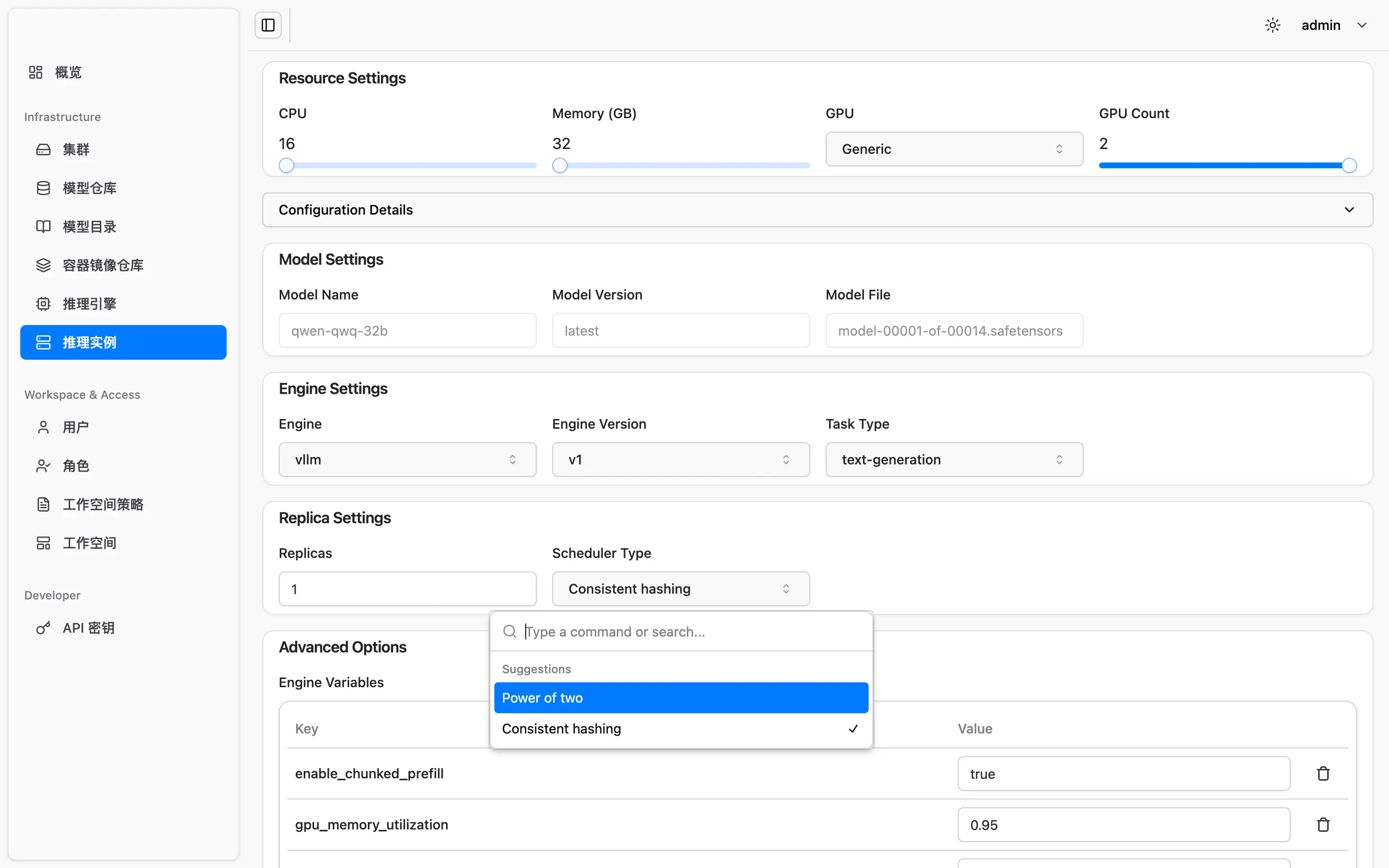
平台基于 KVCache 感知的多副本负载均衡机制,智能优化推理请求路由,有效提升 KVCache 命中率,从而显著提升大模型推理性能与响应效率,满足高并发业务场景需求。
每个租户拥有独立的资源与模型空间,确保业务之间互不干扰,数据安全可控。
支持按角色定义访问权限,覆盖模型管理、推理调用、资源调度等多个维度,便于统一治理。
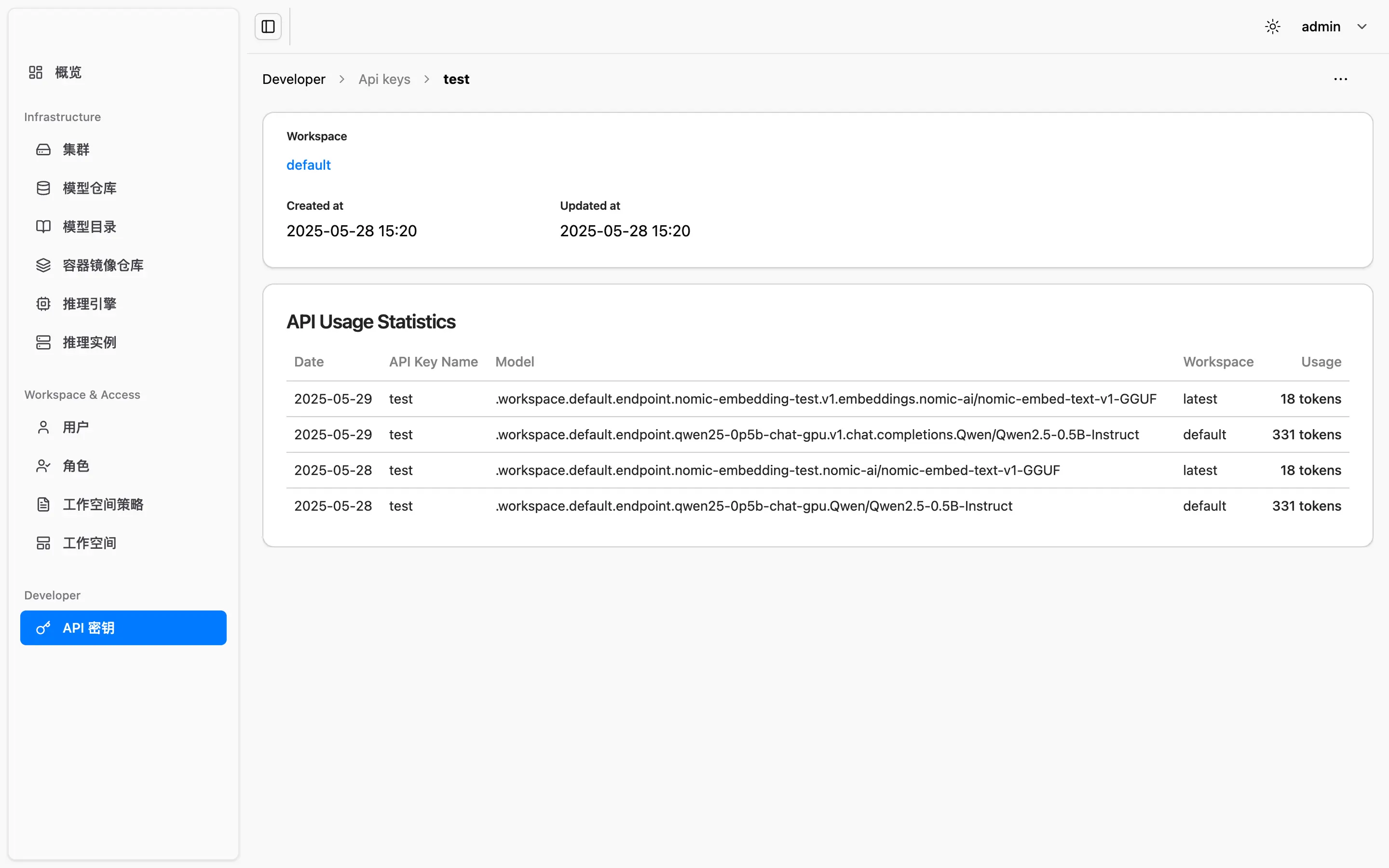
针对外部调用提供 Token 配额配置和使用量统计,帮助平台实现访问限流、成本控制与可计费能力。