作者:SmartX 存储组研发工程师 柯杰伟
在 SMTX OS 的 分布式块存储模块( ZBS ) 中,Meta 负责集群元数据管理的功能,其中很重要的一项任务是数据副本的管理。今天,我们主要聊一聊 SMTX OS 4.0 数据副本管理相关的数据再平衡策略。
数据再平衡策略涉及到两种跨节点的数据 IO 类型:数据恢复和数据迁移。
数据恢复的目标是保证副本数。一般来说,分布式存储的数据通过将多个副本分布在不同节点上的方式保证数据安全。在 ZBS 中,我们推荐使用 2 副本或者 3 副本方式保存用户数据。当集群中发生节点失联、磁盘数据损坏等事件,Meta 发现数据的活跃副本数量小于期望副本数量时,将会触发数据恢复动作,Meta 会在集群中选择一个节点作为副本恢复的目的节点,将活跃副本数据拷贝到目的节点,以达到期望副本数量。
数据迁移的目标是保证副本分布。副本具体分配在哪些节点上有诸多影响。首先,副本位置影响着数据的安全性,数据副本尽可能分布在物理拓扑的不同分支上,可以减少物理故障带来的损害。其次,影响 IO 性能,多个副本的其中一个应该尽可能分布在离访问点最近的节点,降低数据访问的延迟。最后,影响节点的负载和物理资源占用,尽可能的让所有存储节点的实际承担容量近似,平均访问负载并降低节点异常时的损失。因此,Meta 会定期收集集群信息,对副本分配做出近似最优的选择,以满足「拓扑安全」、「本地优先」、「负载均衡」等目标。每个目标在集群不同负载情况下,其优先级有所不同。当集群中发生节点故障,搬迁,新增/删除等事件,Meta 发现数据分布不符合预定目标的现象,将会触发数据迁移,以便达到副本分布满足既定目标。
在 4.0 之前,为了防止恢复/迁移流量影响业务 IO,Meta 对恢复/迁移都做了限速(每一节点恢复和迁移限速分别是 100 MB/s 和 40 MB/s),这存在一定的局限性:
- 数据恢复和迁移的速度为单个节点配置,无法做到全局统一;
- 数据恢复和迁移的速度的修改只能通过重启节点存储服务实现;
- 数据恢复和迁移的速度只能够设置上限,无法根据当前集群的负载进行自适应的调整;
- 待恢复和待迁移数据的扫描由 Meta 进行,由于扫描消耗计算资源,扫描周期较长,无法立刻触发数据的恢复和迁移。
因此,SMTX OS 4.0 针对分布式块存储增加了更智能的动态数据恢复和迁移限速策略。
使用场景
下面列举几个数据再平衡策略的使用场景。
场景一
POC 测试过程中,刚做完破坏性测试,希望能够尽快完成数据恢复和迁移,以便于进行下一个测试。
场景二
集群中某个节点需要被移除出集群,希望能够快速将这个节点上的数据迁移出去。
场景三
滚动升级的过程中,集群很空闲,希望能够快速完成数据恢复,以进行下一个节点的升级。
原理介绍
SMTX OS 4.0 引入的数据再平衡策略提供了两种模式供用户选择,以便调整默认限速:
- 智能调节(AUTO):以保护业务 IO 为前提,系统根据当前业务负载自适应地调整恢复/迁移速度。默认运行在该模式下。
- 静态调节(STATIC):用户人工设置速度限额。当用户希望保护正常 IO 时,可以将恢复速度设置为较小的值(例如,可以采用恢复和限速的默认限速值)。当用户希望加速恢复时,可以设置为较大值(例如,500 MB/s)。静态设置只允许对集群中所有节点设置同一限额,不能够对每个节点单独设置。
两种模式都需要保证设置的限速落于合法范围内。目前数据恢复和迁移都选择同样的取值范围:1 MB/s ~ 500 MB/s。取值的依据是:
- 下限值:由于每个恢复、迁移 IO 的最大超时时间为 18min,也就是恢复、迁移速度最低为 256KB/s,这里选择下限值为 1MB/s;
- 上限值:上限值由 FLAGS_max_recover_limit 和 FLAGS_max_migrate_limit 两个 GFlags 指定,默认值是 500 MB/s,如果磁盘性能更好,在部署时候可以给定一个更大的值。500 MB/s 对于通用磁盘的顺序读写已经足够大,还预留了部分带宽给业务的 IO。
- 注意:这里不支持将限速设置为 0MB/s。如果要关闭恢复或者迁移,需要使用 zbs-meta recover/migrate disable。
静态调节的逻辑相对简单,下面主要介绍智能调节模式的原理。
将 IO 分为 APP IO(即业务 IO)和 Recover IO 两种。智能调节的目标是,遵循 APP IO 优先的原则,对 Recover IO 的速率进行调节,以加速 Recover IO。
判断 APP IO 空闲或者繁忙的依据,采用的是 IOPS(IO Per Second) 和 BPS(Bytes Per Second),忽略 Latency(Latency 跟 IO size 关系较大,需要分别统计,实现复杂;也受到不同硬件影响,阈值选择不大容易。另外,Latency 过大可能由于磁盘故障,应该加速恢复和迁移)。智能调节策略阐述如下:
- 当发现节点当前 APP IO 负载较高(APP IO IOPS >= 1000 或者 BPS >= 100 MB/s),那么重置限速到默认值(Recover 100MB/s,Migrate 40MB/s),起到保护 APP IO 的目的。
- 当发现 Chunk 当前 APP IO 负载较低(APP IO IOPS < 1000 且 BPS < 100 MB/s),且当前的恢复/迁移速度超过限速的 80%,说明快要达到限速,那么提高限速,起到加速恢复的目的。每次提升限速为原值的 1.5 倍。当增长到上限值时,将不再增长。当前的恢复/迁移速度应该包括来自本地和来自远端两部分恢复/迁移速度。
上述策略采用了一种快速增减的方式,同时调节的周期为 4s,可以灵敏地根据负载调节限速。由于调节限速是自治的,由每个节点独立完成,因此策略本身是可拓展的,不受限于集群大小。Meta 仅通过定期的心跳向每个节点传播当前设置的模式类型,并从每个节点处获取当前的动态恢复/迁移阈值。
再平衡策略的判定周期默认为 1 小时,但在集群进入高负载状态时会自动的加速至每 5 分钟扫描一次节点负载状态进行再平衡。避免节点出现单节点容量过载的现象。
示例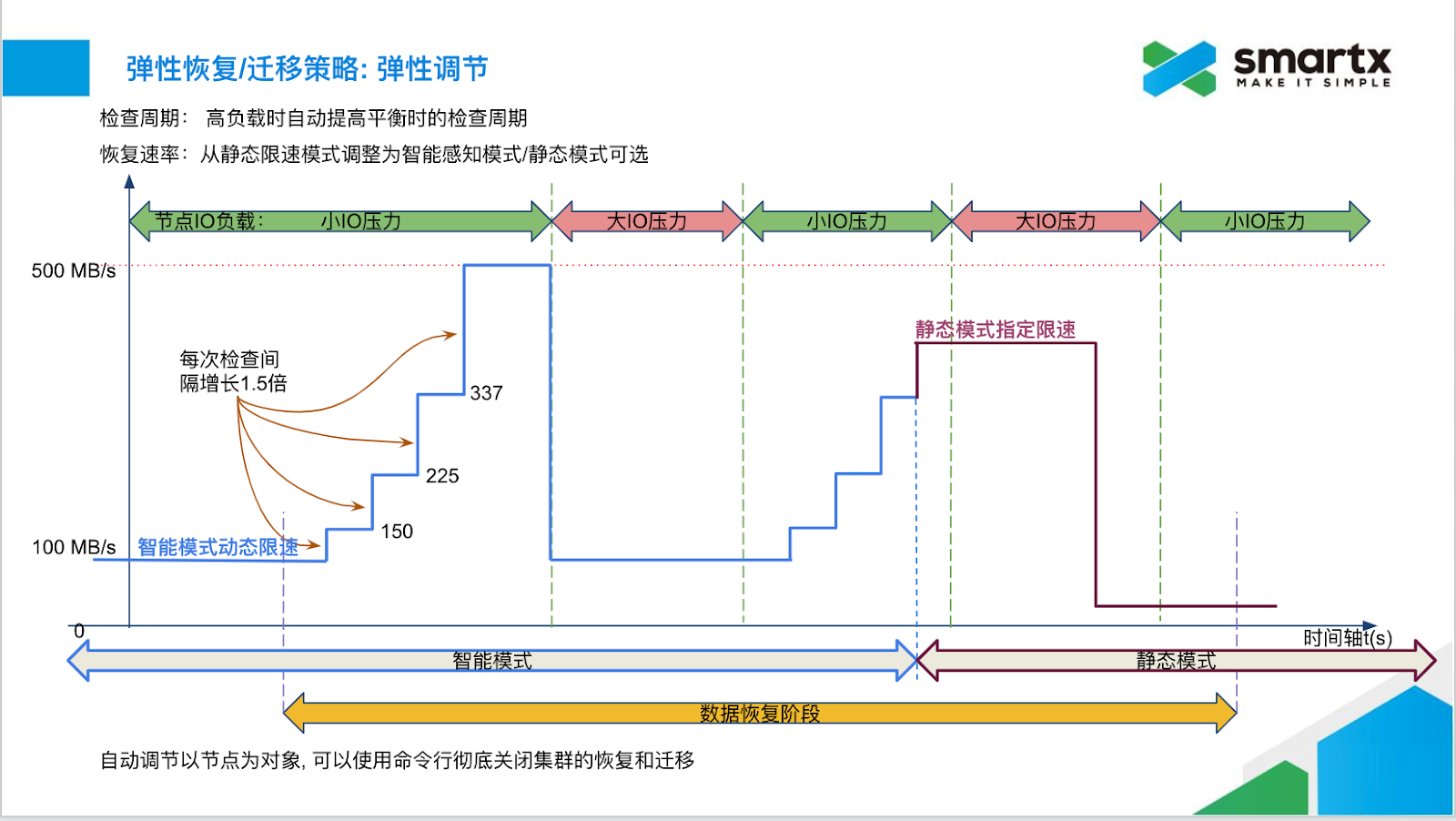
上图示意了在不同 IO 压力下数据恢复限速的变化。节点所在的集群默认采用智能调节模式,节点默认恢复限速为 100 MB/s。节点发生了数据恢复,由于节点的业务 IO 比较小,该节点的恢复限速很快攀升到最高限速 500 MB/s,(每次判断是否需要提升限速的检查间隔为 4s,每次提升至原值的 1.5 倍),并以此最大速度尽力恢复数据。当发现节点的业务 IO 变大时,节点的限速立刻降低到 100 MB/s,以便保证业务 IO 运行。当业务 IO 变小后,恢复限速又开始放开。后续人工设置了集群的恢复限速,那么节点会更新自身的限速,并按照这一限速继续恢复,不管业务 IO 压力情况。
从上图可见,静态设置恢复限速可能会影响业务 IO。一般情况下,推荐用户使用默认的智能调节模式。
使用方法
SMTX OS 4.0 集群默认情况下使用智能调节模式,其相关配置都不会被用户感知到。下面主要介绍命令行模式下进行配置和查看配置的步骤。
使用智能调节模式 Mode 0(调节数据恢复速率)
// 设置为智能调节模式
$zbs-meta recover set_mode_info 0
// (其中第三个节点有数据恢复)获取更新后的配置,发现第三个节点的限速自动提升到 150 MB/s
$zbs-meta recover get_mode_info
Recover mode: RECOVER_AUTO
Recover enable: True
session_id ip current_recover_limit
------------------------------------ ---------- -----------------------
820a31b7-ffc6-4559-bddf-e64ba68ebcd0 10.0.17.71 100.00 MB
d1b16ddd-547f-4791-a3d9-30078d1b749d 10.0.17.70 100.00 MB
ee010c4b-e157-40e5-b7ee-bce5de3e9af4 10.0.17.69 150.00 MB使用静态调节模式Mode 1(调节迁移限速)
// 设置为静态调节模式,限速为 200 MB/s
$zbs-meta migrate set_mode_info 1 --migrate_limit 200
// 获取更新后的配置
$zbs-meta migrate get_mode_info
Migrate mode: MIGRATE_STATIC
Migrate enable: True
Static migrate limit: 200.00 MB智能和静态两种模式可随时切换。
发起立即扫描 Recover
一般情况下,Meta 会定期扫描集群中需要进行恢复的数据,再下发恢复指令到对应的节点。扫描的周期为 1 分钟。下面提供了命令行可以发起立即扫描待恢复数据。
$zbs-meta recover scan_immediate -h
usage: zbs-meta recover scan_immediate [-h]发起立即扫描 Migrate
一般情况下,Meta 会定期扫描集群中需要进行迁移的数据,再下发迁移指令到对应的节点。扫描的周期为 1 小时。下面提供了命令行可以发起立即扫描待迁移数据。
$zbs-meta migrate scan_immediate -h
usage: zbs-meta migrate scan_immediate [-h]关闭/开启数据恢复/迁移
$zbs-meta recover disable -h
usage: zbs-meta recover disable [-h]$zbs-meta migrate enable -h
usage: zbs-meta migrate enable [-h]了解更多产品信息,请点击:https://www.smartx.com/smtx-os/
请扫描下方二维码,关注 SmartX 微信公众号“ SmartX 超融合”,第一时间了解更多超融合选型、评估、迁移等专业知识,以及最新产品动态、行业实施方案与案例。