Persistent Memory(PMem)
PMem 在 2018 年的时候还仅限于学术界的探讨,而如今已经来到了工业界。Intel 在 2019 年 4 月份发布了第一款 Intel Optane DC Persistent Memory(内部产品代号 Apache Pass),可以说是一个划时代的事件。如果你完全没有听说过 PMem,那么可以先通过我之前的文章了解一下。
我们先来看一下实物的样子

首先,由于 PMem 是 DIMM 接口,可以直接通过 CPU 指令访问数据。读取 PMem 的时候,和读取一个普通的内存地址没有区别,CPU Cache 会做数据缓存,所有关于内存相关的知识,例如 Cache Line 优化,Memory Order 等等在这里都是适用的。而写入就更复杂了,除了要理解内存相关的特性以外,还需要理解一个重要的概念:Power-Fail Protected Domains。这是因为,尽管 PMem 设备本身是非易失的,但是由于有 CPU Cache 和 Memory Controller 的存在,以及 PMem 设备本身也有缓存,所以当设备掉电时,Data in-flight 还是会丢失。
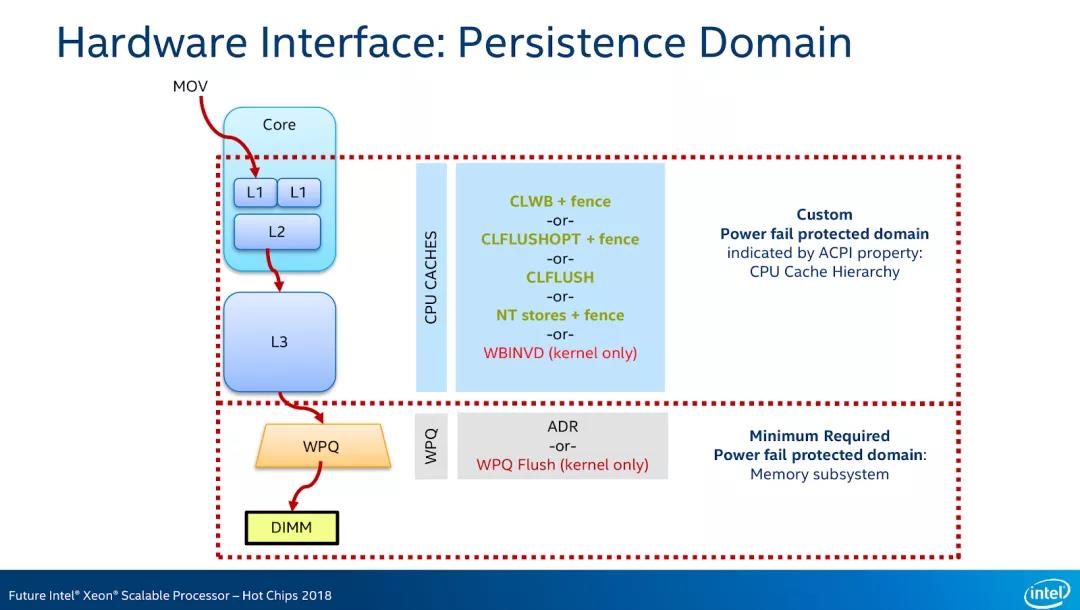
和 CLFLUSHOPT 对应的,是 CLWB 指令,CLWB 和 CLFLUSHOPT 的区别是,CLWB 指令执行完成后,数据还保持在 CPU Cache 里,如果再次访问数据,就可以保证 Cache Hit,而 CLFLUSHOPT 则相反,指令执行完成后,CPU Cache 中将不再保存数据。
此外 Non-temporal stores(NTSTORE)指令(经专家更提醒,这是一个 SSE2 里面就添加的指令,并不是一个新指令)可以做到数据写入的时候 bypass CPU Cache,这样就不需要额外的 Flush 操作了。NTSTORE 后面也要跟随一个 SFENCE 指令,以保证数据真正可以到达持久化区域。
看起来很复杂对吧,这还只是个入门呢,在 PMem 上写程序的复杂度相当之高。Intel 最近出了一本书 “Programming Persistent Memory”,专门介绍如何在 PMem 上进行编程,一共有 400 多页,有兴趣的小伙伴可以读一读。
为了简化使用 PMem 的复杂度,Intel 成立了 PMDK 项目,提供了大量的封装好的接口和数据结构,这里我就不一一介绍了。
PMem 发布以后,不少的机构都对它的实际性能做了测试,因为毕竟之前大家都是用内存来模拟 PMem 的,得到的实验结果并不准确。其中 UCSD 发表的 “Basic Performance Measurements of the Intel Optane DC Persistent Memory Module” 是比较有代表性的。这篇文章帮我们总结了 23 个 Observation,其中比较重要的几点如下:
-
The read latency of random Optane DC memory loads is 305 ns This latency is about 3× slower than local DRAM -
Optane DC memory latency is significantly better (2×) when accessed in a sequential pattern. This result indicates that Optane DC PMMs merge adjacent requests into a single 256 byte access -
Our six interleaved Optane DC PMMs’ maximum read bandwidth is 39.4 GB/sec, and their maximum write bandwidth is 13.9 GB/sec. This experiment utilizes our six interleaved Optane DC PMMs, so accesses are spread across the devices -
Optane DC reads scale with thread count; whereas writes do not. Optane DC memory bandwidth scales with thread count, achieving maximum throughput at 17 threads. However, four threads are enough to saturate Optane DC memory write bandwidth -
The application-level Optane DC bandwidth is affected by access size. To fully utilize the Optane DC device bandwidth, 256 byte or larger accesses are preferred -
Optane DC is more affected than DRAM by access patterns. Optane DC memory is vulnerable to workloads with mixed reads and writes -
Optane DC bandwidth is significantly higher (4×) when accessed in a sequential pattern. This result indicates that Optane DC PMMs contain access to merging logic to merge overlapping memory requests — merged, sequential, accesses do not pay the write amplification cost associated with the NVDIMM’s 256 byte access size
尽管峰值带宽高,但单线程吞吐率低,甚至远比不上通过 SPDK 访问 NVMe 设备。举例来说,Intel 曾发布过一个报告,利用 SPDK,在 Block Size 为 4KB 的情况下,单线程可以达到 10 Million 的 IOPS。而根据我们测试的结果,在 PMem 上,在 Block Size 为 4KB 时,单线程只能达到 1 Million 的 IOPS。这是由于目前 PMDK 统一采用同步的方式访问数据,所有内存拷贝都由 CPU 来完成,导致 CPU 成为了性能瓶颈。为了解决这个问题,我们采用了 DMA 的方式进行访问,极大的提高了单线程访问的效率。关于这块信息,我们将在未来用单独的文章进行讲解。
另一个坑就是,跨 NUMA Node 访问时,效率受到比较大的影响。在我们的测试中发现,跨 NUMA Node 的访问,单线程只提供不到 1GB/s 的带宽。所以一定要注意保证数据访问是 Local 的。
关于 PMem 的使用场景,其实有很多,例如:
-
作为容量更大,价格更便宜的主存,在这种情况下,PMem 实际上并不 Persitent。这里又有两种模式: -
OS 不感知,由硬件负责将 DRAM 作为 Cache,PMem 作为主存 -
OS 感知,将 PMem 作为一个独立的 memory-only NUMA Node,目前已经被 Linux Kernel 支持,Patchset -
作为真正的 PMem,提供可持久化存储能力
Distributed Consensus and Consistency
Distributed Consensus 只是手段,Strong Consistency 才是目的。
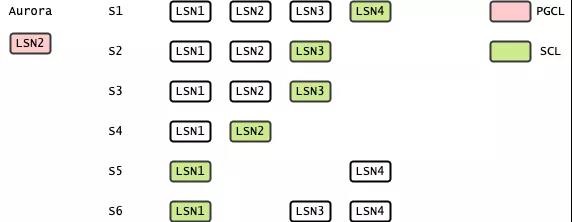
实现 Strong Consistency 的方法还有很多。在过去一段时间里面,我认为最经典的要数 Amazon 的 Aurora。
Amazon Aurora 目前共发表了两篇文章。第一篇是 2017 年在 SIGMOD 上发表的 “Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases”,另一篇是在 2018 年的 SIGMOD 上发表了一篇论文 “Amazon Aurora: On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes”。第二篇论文主要讲述了他们如何在不使用 Distributed Consensus 的情况下,达到 Strong Consistency 的效果。
为了介绍 Aurora,我们先来简单看一下通常 Distributed Consensus 是如何做到 Strong Consistency 的。
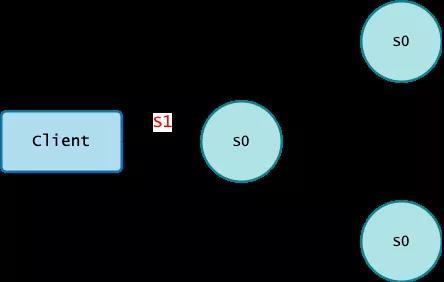
通常来说,我们在考虑 Consistency 的时候,都会结合 Durability 一起考虑。需要 Strong Consistency,就会用 Distributed Consensus,或者其他的 Replication 方式完成一次 Quorum Write,保证了 Strong Consistency 的同时,也保证了 Durability,代价就是性能差;如果只需要 Weak Consistency,那么就不需要立刻完成 Quorum Write,只需要写一个副本就可以了,然后再异步完成数据同步,这样性能会很好,但是由于没有 Quorum Write,也就丧失了 Durability 和 Consistency。所以大家一直以来的一个共识,就是 Strong Consistency 性能差,Weak Consistency 性能好。
那有没有一种方法既能保证 Strong Consistency,同时又保证 Performance 呢?Remzi 在这篇论文中提出了 “Consistency-Aware Durability”(CAD)的方法,把 Consistency 和 Durability 解耦,放弃了部分 Durability,来保证 Strong Consisteny 和 Performance。实现的方法可以用一句话总结,就是 Replicate on Read。
在 Strong Consistency 中,有一个很重要的要求就是 Monotonic Reads,当读到了一个新版本的数据后,再也不会读到老版本的数据。但换一个角度思考,如果没有读发生,是不存在什么 Monotonic Reads 的,也就不需要做任何为了为了保证 Consistency 的工作(是不是有点像薛定谔的猫?)。
另外再推荐给大家两篇论文,一篇是 Raft 作者 John Ousterhout 大神的新作 “Exploiting Commutativity For Practical Fast Replication”,还有一篇是用 Raft 实现 Erasure Code “CRaft: An Erasure-coding-supported Version of Raft for Reducing Storage Cost and Network Cost”。有兴趣的同学可以自己看一下,这里我就不做介绍了。

LegoOS 是一个非常不错的想法,但我认为在实现上会面临着非常巨大的挑战,一方面由于大部分的功能都需要依赖软件来实现,延迟可能会受到一定的影响,另一方面是 LegoOS 没有采用 Cache Coherence 的模型,而是用了 Message-Passing 的方式在各个 Component 之间进行通信。Message-Passing 可能是更优雅设计方案,但是如果真的想要在工业界中实现 LegoOS 这种思想,硬件厂商有需要根据 Message-Passing 来重新设计 Driver,这对于已有的硬件生态来说恐怕是很难接受的。
在工业界中,尽管目前还没有看到 DSM 的成功案例,但是目前已经开始看到一些相关的技术出现。这里我们会重点关注一下总线(Bus)技术。
最近几年,异构计算(heterogeneous computing)变得越来越常见,CPU 通过 PCIe 总线和 GPU、FPGA 等异构计算单元进行通讯。而由于 PCIe 总线诞生时间较早,不支持 Cache Coherence,所以为编写异构计算的应用程序带来了极大的复杂度。例如应用程序想要在 CPU 和 GPU 之间共享数据,或者 GPU 和 GPU 之间共享数据,必须自行处理可能产生的 Cache 一致性问题。
为了适应逐渐增加的异构计算场景,各个厂商开始筹划推出新的总线技术,这包括:
-
来自 Intel 的 Compute Express Link(CXL) -
来自 IBM 的 Coherent Accelerator Interface(CAPI) -
来自 Xilinx 的 Cache Coherence Interconnect for Accelerator(CCIX) -
来自 AMD 的 Infinity Fabric -
来自 NVIDIA 的 NVLink
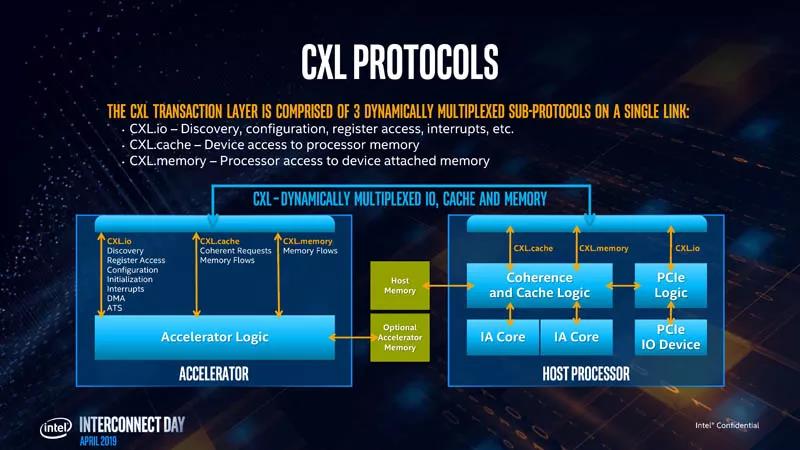
-
CXL.io:不提供 Cache Coherence 的 IO 访问,类似于目前的 PCIe 协议 -
CXL.cache:用于设备访问主存 -
CXL.memory:用于 CPU 访问设备内存
过去两年这方面的进展也比较少,我看过唯一相关的论文,是在 FAST ’19 上的一篇论文:SLM-DB: Single-Level Key-Value Store with Persistent Memory,对 PMem 上运行 LSM-Tree 进行优化。目前随着 IO 设备的速度越来越快,大家都比较认可 LSM-Tree 已经从 IO Bound 转移到 CPU Bound,LSM-Tree 的劣势越来越明显,这让大家开始反思是否应该继续使用 LSM-Tree 了。
Machine Learning and Systems
尽管两年前开始有 Machine Learning For Systems 的相关工作,但是过去两年一直没有什么实质性的进展,反倒是 Systems for Machine Learning 有一些和 GPU 任务调度相关的工作。
VirtIO without Virt
VirtIO 是专门为虚拟化场景设计的协议框架。在 VirtIO 框架下,可以支持各种不同设备的虚拟化,包括 VirtIO-SCSI,VirtIO-BLK,VirtIO-NVMe,VirtIO-net,VirtIO-GPU,VirtIO-FS,VirtIO-VSock 等等。而 VirtIO 设备虚拟化的功能一直都是由软件来完成的,之前主要是在 Qemu 里面,现在还有 VHost。而目前逐渐有硬件厂商开始尝试原生支持 VirtIO 协议,把虚拟化的功能 Offload 到硬件上完成,这样进一步降低 Host 上因虚拟化而产生的额外开销。这也是 AWS Nitro 的核心技术之一,通过把 VirtIO Offload 给硬件,使得 Host 上的几乎所有 CPU、内存资源都可以用于虚拟机,极大的降低了运营成本。
Linux Kernel
目前 Linux Kernel 已经来到了 5.0 的时代,近期比较重要的一个工作就是 IO_URING。关于 IO_URING,我们之前在文章中也做过介绍。IO_URING 和一年前相比又有了巨大的进步,目前除了支持 VFS 以外,也已经支持 Socket,为了提高性能还专门写了新的 Work Queue。IO_URING 的终极目标是 one system call to rule them all,让一切系统调用变成异步!
回顾过去两年,存储领域还是有非常巨大的进展,我们正处在一个最好的时代。工业界的进展相对更让人 Exciting 一些,非易失内存、CXL 协议、支持 VirtIO 的硬件等等,都可以说是开启了一个新的时代。而学术界尽管也有一些不错的 idea,但主要进展还是围绕在一些老的方向上,急需出现一些开创性的工作。就我们公司而言,未来的一个工作重点就是如何充分利用 PMem 的特性,提高存储系统整体的性能。如果你对文章的内容感兴趣,欢迎留言评论。如果你想要从事存储这个方向,也欢迎加入我们团队~
作者介绍
@张凯(Kyle Zhang),SmartX 联合创始人 & CTO。SmartX 拥有国内最顶尖的分布式存储和超融合架构研发团队,是国内超融合领域的技术领导者。
请扫描下方二维码,关注 SmartX 微信公众号“ SmartX 超融合”,第一时间了解更多超融合选型、评估、迁移等专业知识,以及最新产品动态、行业实施方案与案例。
<a href=”https://www.smartx.com/media-blog/weixin1.png”><img src=”https://www.smartx.com/media-blog/weixin1.png” alt=”weixin1.png” /></a>