作者:IOMesh 产品研发工程师 鲁子银
为了保证 Kubernetes 集群的稳定性与可靠性,不少用户都会采用 Kubernetes 持久化存储,为 Kubernetes 节点提供高可用保障。但是,一些用户在实践中仍会碰到这样的问题:
- 某一 Kubernetes 节点发生故障,该节点上的 Pod(绑定 RWO 类型 PVC)尝试迁移到其他节点,但在新节点上可能会出现 PVC 绑定失败而无法启动的情况,从而造成停机影响。
为什么会出现这样的情况?为了避免上述故障,SmartX 的 Kubernetes 原生存储 IOMesh 通过 Pod HA 为 Kubernetes 集群提供高级别高可用保障。本文将结合这一故障场景,对 IOMesh Pod HA 机制原理进行深入解读。(更多 IOMesh 产品特性,请阅读文末电子书《IOMesh 用户指南》)
Kubernetes 默认机制:绑定 RWO 类型 PVC 的 Pod 会出现 HA 失败
Kubernetes 由于某些默认机制,会导致绑定了 RWO(Read-Write-Once)类型 PVC 的 Pod 故障 HA 失败:某一 Kubernetes worker 节点故障时,RWO 的 PVC 对应的 VolumeAttachment 未能被 Kubernetes 删除,导致该节点的 Pod 在新节点启动并绑定 PVC 时,被 Kubernetes 层面判定为“该 PVC 正在被另一个 Pod 使用”,因此无法完成挂载。具体过程如下:
- 故障一分钟后,用户通过 kubectl get nodes 会看到故障节点的状态变为 NotReady。
- 故障五分钟后,NotReady 节点上所有 Pod 的状态将变为 Unknown 或 Terminating。
- StatefulSets 具有稳定的标识,默认不会在其他健康节点上重建已经进入 Terminating 状态的 Pod, Kubernetes 也不会为用户强制删除 Pod。
- Deployments 没有稳定的标识,默认会在其他健康节点上创建一个新的 Pod 来保证 Deployments 的 ready 副本数符合预期。这时故障 Pod 依然保留在 Terminating 状态,Kubernetes 不会强制删除。如果 Pod 挂载了 RWO 类型的 PVC,则会出现开头描述的问题,此时如果没有人工或其他程序的干预,新的 Pod 将卡在 ContainerCreating 状态。
问题原因:Pod 与 Node 的绑定关系不会被主动删除
Pod HA 失败可以认为是 Kubernetes attach/detach controller(后续简称 A/D controller)没有做出正确的决策。A/D controller 是 Kubernetes 的内置控制器。该控制器根据 kube-scheduler 给出 Pod 的调度决策,做出“volume 应该 attach 到哪个 node”或“volume 应该从哪个 node detach”的决策。
为了做出正确的干预,我们通过代码分析了 A/D controller 的工作方式。这一过程可简化为:
- A/D controller 启动时,一次性从 apisever 获取当前哪些 Node 绑定了哪些 volume,并将绑定关系和相关信息缓存在 actualStateOfWorld 结构中。
- 之后,A/D controller 会定期从 apisever 拉取 Pod 的调度信息,将 Pod 和其期望调度到的 Node 或已经调度到的 Node 的映射关系缓存在 desiredStateOfWorld 结构中。
- A/D controller 也会定期对 desiredStateOfWorld 和 actualStateOfWorld 做 diff,根据 diff 做相应的 attach/detach 操作。比如在 desiredStateOfWorld 中看到 Pod-A(绑定了 PVC-A) 期望调度到 Node-A,但在 actualStateOfWorld 看到 PVC-A 未 attach 到 Node-A,则会主动进行 attach。
- 根据操作结果将 actualStateOfWorld 缓存的数据更新到最新的正确状态。对于 csi 的场景,attach 操作为创建对应的 VolumeAttachment,运行在 csi-driver pod 内的 csi-attacher sidecar 监听到 VolumeAttachment 创建后会调用 ControllerPublishVolume RPC。
现在,结合 A/D controller 的工作原理,我们再来描述 Pod HA 失败的故事:假设 Deployment-A 管理分别运行在 Node-A 和 Node-B 上的 Pod-A 和 Pod-B,他们分别绑定一个 RWO 类型的 PVC。此时 Node-A 断网,Pod-A 进入 Terminating 状态,Kubernetes 不强制删除 pod-A,因此在 A/D controller 的 desiredStateOfWorld 缓存内依然存在 Pod-A 和 Node-A 的绑定关系,不会触发 detach 删除 Node-A 上对应的 VolumeAttachment。此时 Deployment-A 发现运行的副本数小于期望的副本数,于是打算在 Node-C 上重建 Pod-A。由于 PVC 类型为 RWO,且 A/D controller 发现 Node-A 已存在对应的 VolumeAttachment,因此拒绝了 Pod-A 的绑定请求,Pod 卡在 ContainerCreating 状态,导致了最终的 HA 失败。
解决方案:删除 VolumeAttachment vs. 删除 Pod
通过上述分析可以发现,若想成功实现新的绑定,要么需要删除原有的 VolumeAttachment,要么需要在 Pod-A 进入 Terminaling 状态后将其删除。
最开始,我们尝试通过手动删除 Node-A 上 VolumeAttachment 的方式让 Pod-A 在 Node-C 上恢复。该方法可以立即奏效的,而且后续可以通过在 CSI Driver 中增加一个 VolumeAttachment 控制器的方式实现自动化删除。但之后通过对 A/D controller 的代码分析,我们发现用户主动删除 VolumeAttachment 是一个非预期行为,存在一定风险:A/D controller 在删除 VolumeAttachment 后,会更新 actualStateOfWorld 缓存的信息,如果用户手动删除 VolumeAttachment,A/D controller 无法感知,缓存不会更新, actualStateOfWorld 缓存信息错误,导致 A/D controller 后续可能会做出错误的决策。
因此,我们认为,正确的做法是通过 CSI 主动删除 Pod,让 A/D controller 自动走完 detach 和缓存更新流程。这也是我们在设计 IOMesh Pod HA 机制时的理论基础。
IOMesh Pod HA:优化原有机制,提供高级别高可用保护
为了进一步保障集群高可用,避免出现上述问题,我们为 IOMesh 提供了节点感知能力,并允许用户自主选择是否需要在节点出现故障时,自动对 Pod 进行删除并在新节点重建*。
* 该机制默认关闭,用户可根据需求自行开启。
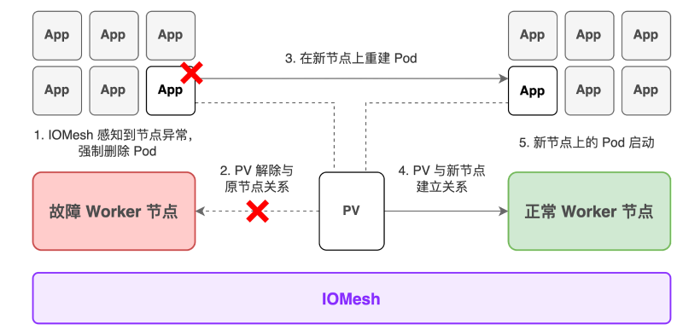
该机制的具体实现过程如下:
1. 当 IOMesh CSI Driver 发现某一 Kubernetes 节点状态由 Ready 变为 NotReady 时,开始定期探测该节点的状态。
2. 如果连续 3 次(默认,可配置)间隔 30s(默认,可配置)的探测结果均为 NotReady,则进入主动删除 Pod 流程,该节点上所有满足以下条件的 Pod 均被删除:
- Pod 至少绑定了一个 PVC 且所有 volume 都是 IOMesh CSI 的 PVC。
- Pod 的状态为非 Running。
- 集群中至少有一个健康的节点,且 Pod 可以调度至该节点(没有相关的 affinity/stain 冲突)
- 检查 Pod 的 ownerReferences(deployment or statefulset),符合启动参数的设定。
3. Pod 被删除后,A/D controller 会自动执行 detach 操作,包括在 desiredStateOfWorld 的定期更新中移除已删除的 Pod 和故障节点的绑定关系、对 Pod 绑定的 PVC 做 detach 操作、删除故障节点上的 VolumeAttachment、更新 actualStateOfWorld 的信息。
4. 当 Pod 在健康节点上重建时,由于已经走完了从故障节点的 detach 流程,因此可以顺利走完 attach 流程,完成重建。
整个 HA 的执行过程为 7 分 30 秒,其中 1 分 30 秒是从节点故障到 CSI 删除 Pod 的默认监听时间,用户可在配置 IOMesh CSI Driver 时进行设置;剩余 6 分钟是 PVC 从故障节点 detach 的时间,这一时长是 Kubernetes 为 A/D controller 设置的不可变参数。
除了节点故障时的高可用保障,IOMesh 还支持 Pod 调度至其他节点的 PV 访问和副本迁移,帮助有状态应用实现迁移,在减少业务中断的同时充分利用 I/O 本地化带来的性能优势。
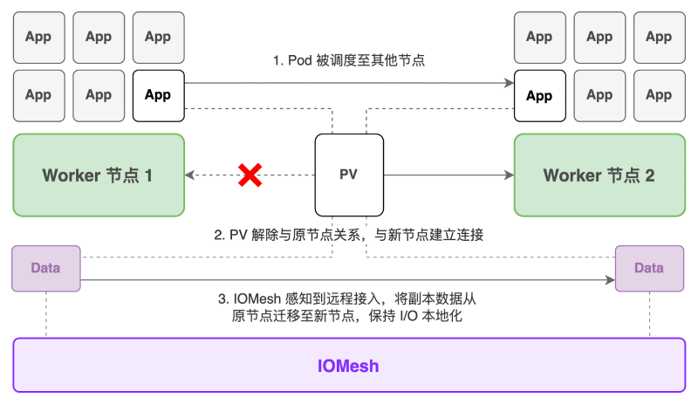
当 Pod 被调度至其他节点后,被挂载给该 Pod 的 PV 将解除与原节点的关系并与新节点建立连接。如果新节点上没有副本,IOMesh 将感知到远程接入,在稳定运行一段时间后,将副本数据从持有副本的节点迁移至新节点,保障 I/O 本地化。
作为国内首款 Kubernetes 原生的企业级分布式存储,IOMesh 不仅具备生产级别高可用与安全机制,还可为用户提供深度的 Kubernetes 集成能力与高性能支持。更多 IOMesh 技术特性,欢迎点击免费下载《IOMesh 用户指南》进一步了解(在 SmartX 用户社区中获取)。
您还可通过《Kubernetes 持久化存储方案选择:从入门到评估》,了解更多 Kubernetes 持久化存储技术知识与选型建议。