目前,不少企业都开始开发或者使用 AI 应用支持业务发展。不过在进行 AI 基础设施规划时,很多 IT 决策者只关注到 AI 场景对于算力的需求,而忽视了存储方案的规划,系统难以及时将数据传输给 GPU,反而浪费了重要的计算资源。对此,Gartner 在《Top Storage Recommendations to Support Generative AI》报告中,解读了生成式 AI(GenAI)在存储层面的 3 大高级功能需求,并针对不同用户的使用场景提供了存储建设与部署方案。我们将通过今天的文章进行分享和解读,您还可观看 以下视频,了解更多内容。
重要建议
- 直接使用现成的 LLM 或尝试部署生成式 AI 时,建议采用一体式 AI 融合存储方案。
- 使用既有企业存储平台(SAN、NAS、对象存储或 HCI)进行小规模数据训练或支持训练好的模型。
- 大规模使用生成式 AI 应用时,需要搭建一个端到端的存储基础设施,满足生成式 AI 工作流程中各个阶段(从数据收集、训练、微调、推理到归档)在存储方面的需求。存储设施需要能够对各个源端(包括数据中心、边缘和公有云)的数据进行灵活管理。
- 如果没有数据安全/合规方面的限制,或者计算和存储需求难以预估,可以使用公有云运行生成式 AI 应用。
Gartner 预测
到 2028 年,75% 使用生成式 AI 训练数据的企业都将部署单一存储平台进行数据存储,尽管这一比例在 2024 年仅有 10%。
生成式 AI 需要 3 大高级存储能力
生成式 AI 应用对企业的底层存储设施提出了一些高级能力要求,主要包括以下 3 类:
- 多元化数据存储能力:企业需要以一套可扩展的数据湖存储平台,为所有用于 AI 模型训练的数据提供存储服务,不论这些数据是基于文件还是对象形式进行存储、对吞吐量或延迟是否敏感、文件是大是小、更侧重于元数据或是数据访问。
- 强劲的存储性能:存储方案需要通过一些功能特性来提供足够强大的性能,以保证整个 AI 训练阶段 GPU 能够被充分利用,并快速完成模型检查点和恢复过程。如果存储不能快速将数据投喂给 GPU,就会出现 GPU 资源浪费的情况。
- 全局数据管理能力:由于 AI 模型训练或微调时可能会使用来自各个站点的数据,存储方案需要能够对本地机房、多云平台和边缘站点进行全局数据管理,避免数据复制带来的复杂运维与容量浪费。
想要获取这些能力,企业可能需要对存储设施进行现代化改造,这对于基于大规模数据进行新 LLM 模型训练的企业而言尤为迫切。虽然大多数企业可能并没有类似的需求,但支持生成式 AI 应用依旧需要存储层具备类似的高级功能或能力。
生成式 AI 存储建设与部署方案
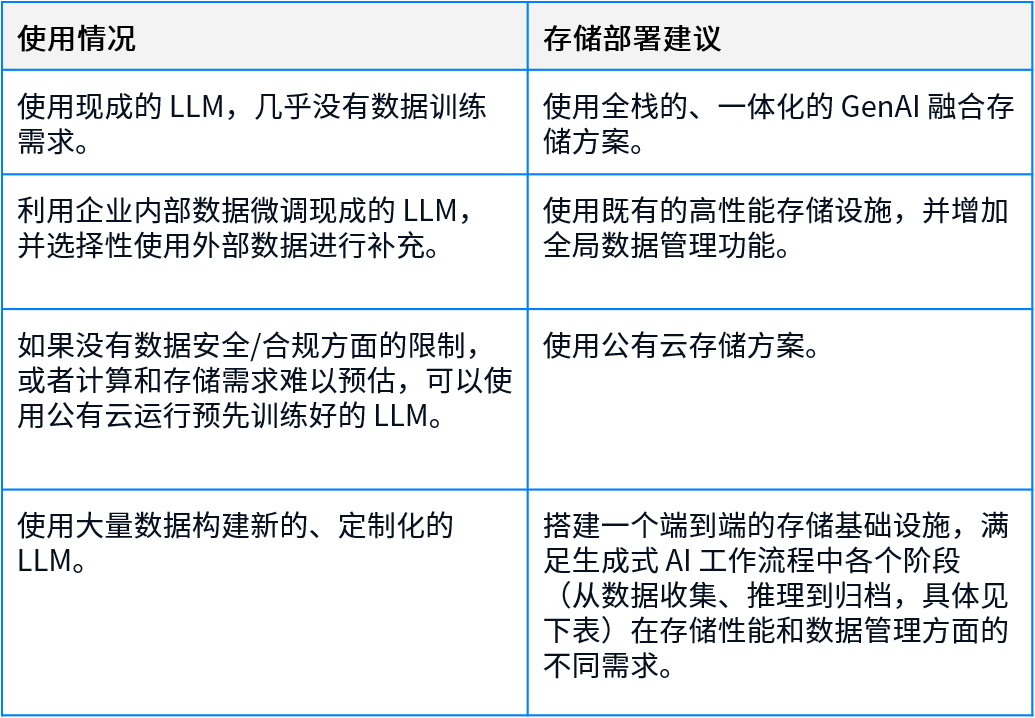
大部分企业不需要搭建新的存储基础设施
根据 Gartner 的调研,在 5 种企业生成式 AI 部署模式中,仅有一种需要搭建底层模型或从头开始构建 LLM;其余的 4 种部署模式,都是直接使用现成的、预先训练好的 LLM,仅需要企业基于内部数据(有时也需要补充外部数据)、提示工程或数据检索技术来进行微调。也有越来越多的企业选择以小型语言模型(SLM)替代 LLM——与使用数十亿参数的 LLM 相比,SLM 通常仅需要不到 1 亿个参数——以便快速测试模型,并帮助用户在特定业务场景中快速看见 ROI。

这也就意味着,在大多数情况下,企业并不需要为了生成式 AI 购买新的存储设施。不过如果企业的数据湖中还没有数据,可能还是需要构建矢量数据库进行数据训练。当主要使用现有数据进行模型微调时,有两种存储部署方案:
- 购买专用的一体式 GenAI 解决方案。这些解决方案通常基于超融合架构,同时提供适用于 AI 应用规模的存储、计算和网络基础设施,以及训练好的 LLM。
- 使用现有的存储基础设施。这里并不限制存储方案是文件、对象或是块存储,是外部存储、直连存储或是超融合存储。如果企业能够部署数据管理软件层,实现跨内部、边缘和/或公共云中的存储数据访问,则会更有帮助。
Gartner 建议
- 直接使用现成的 LLM 或尝试部署 GenAI 时,建议购买一体式 GenAI 融合存储方案。
- 使用既有企业存储平台(SAN、NAS、DFS 或 HCI)进行小规模 GenAI 试点。
- 引入数据管理方案,以便在现有存储中实现通用访问,并支持自定义标记和基于元数据的搜索。
- 在考虑其他供应商的产品之前,先了解既有存储供应商的 GenAI 支持能力。目前很多供应商都在快速构建新功能,并推出针对 GenAI 的解决方案。
大规模生成式 AI 部署需要可支持模型训练和推理的高级存储能力和全面数据管理能力
第一批大型复杂的 GenAI 部署已经开始对存储设施提出了“既要高效、又要高性能”的多重需求。一些 GenAI 工作负载会带来 PB 级的数据量,GenAI 工作流程的不同阶段也对存储性能和操作提出了不同的要求。对于这些工作负载,数据湖或分布式存储系统(如 Hadoop 和 Spark)通常用于存储训练数据和中间输出。在训练、微调和推理时,基础设施栈重点需要提供针对性的 GPU 优化和高吞吐量。
存储是基础设施栈中至关重要的角色,选择何种存储方案的则取决于 AI 模型的大小。对于体量较小的 AI 模型,本地硬盘可能就可以满足需求。但大型模型通常需要基于对象存储或并行文件系统的共享存储。对于大型 GenAI 系统,一款可扩展、大容量和低延迟的集成存储方案,能为非结构化数据的处理提供最佳性能。
GenAI 工作流程的不同阶段对存储的要求具体如下:
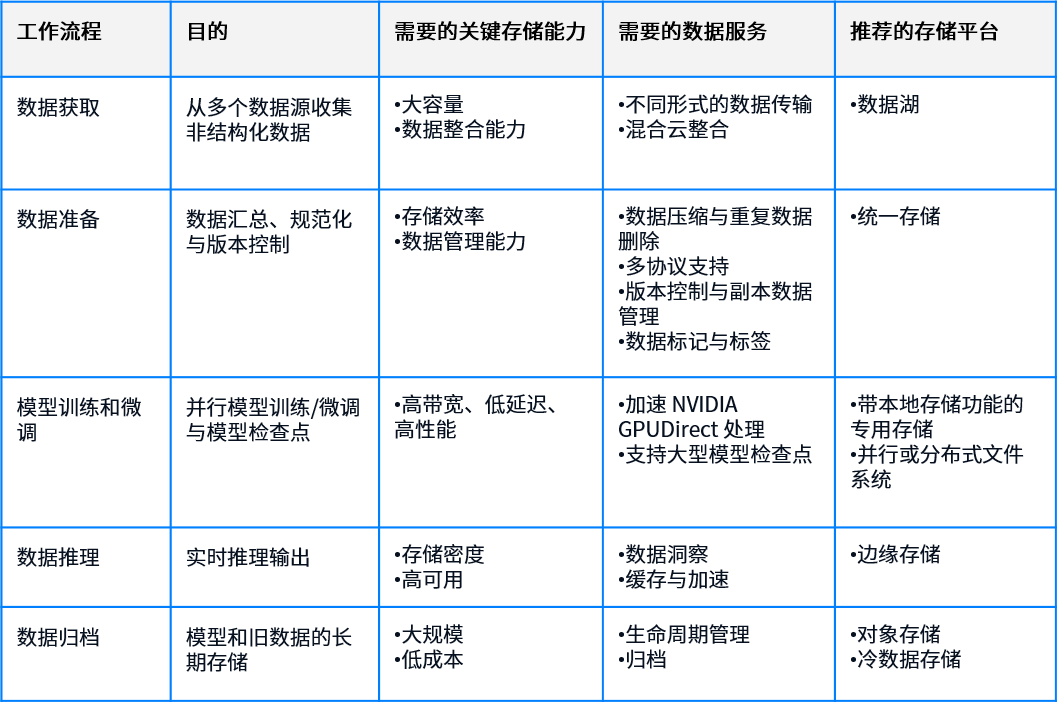
大规模 GenAI 部署将对非结构化数据的存储提出更高要求,包括大量的数据量增长、要求支持各种数据类型、需要高效的数据版本控制和生命周期管理。模型训练和微调属于资源密集型业务场景,对存储和相关基础设施的要求更特殊:网络和存储设施必须能够提供高吞吐量,尽量减少数据丢失,同时具有可组合性,以便满足 GenAI 工作负载不断变化的需求。此外,GenAI 数据平台必须能够实现 GenAI 工作负载在不同阶段的混合数据管理,以实现数据管道自动化。最后,GenAI 数据平台必须支持高于常规的数据安全标准,以保护敏感数据。
如上表所示,由于 GenAI 工作负载复杂多样,AI 应用场景可能没有“一刀切”的存储基础架构方法。I&O 领导者不应只关注用于训练 GenAI 模型的高性能存储,还应构建端到端的工作流策略,包括提供跨边缘、公有云和本地存储的数据管理能力。
下表展示了 GenAI 大规模部署需要的存储平台关键能力。

目前,GenAI 的早期采用者正在与大型公有云提供商合作,因为这些提供商可以快速落地各种规模的 GenAI 试点项目。大型提供商主要支持整个数据技术堆栈,提供基于可用 LLM 的 GenAI 开发服务。此外,一些大型供应商(如 AWS 和谷歌)正在投资针对数据和存储进行优化的专有芯片和互联,以满足 GenAI 应用日益增长的需求。但是,受到成本、安全性、隐私以及需要专用 LLM 等方面的制约,并不是所有企业都适合这种部署模式。
Gartner 建议
- 选择能够同时为高带宽/大量顺序工作负载和小文件/随机 I/O 工作负载提供高性能的供应商和产品,因为大多数传统解决方案无法兼顾这两类工作负载的性能支持。
- 使用共享存储来整合数据平台,避免 GenAI 数据管道在不同阶段之间移动,并提高存储效率。
- 对既有存储网络进行现代化改造,使用高性能架构消除性能瓶颈并最大限度地提高 GPU 利用率。
- 对不同的 AI 数据管道阶段和部署位置(边缘、核心数据中心和公有云)采用统一的数据管理方式,避免引入存储孤岛。
对此,SmartX 也为企业用户提供了基于超融合架构的 AI 基础设施解决方案,为 AI 工作负载按需提供 CPU 和 GPU 算力,统一支持虚拟化和容器化 AI 应用,实现工作负载的融合部署。该解决方案基于 SmartX 自主研发的分布式块存储与文件存储,可支持多种存储介质,为 AI 应用提供高性能、大容量、易扩容的存储服务。欲深入了解,请阅读:
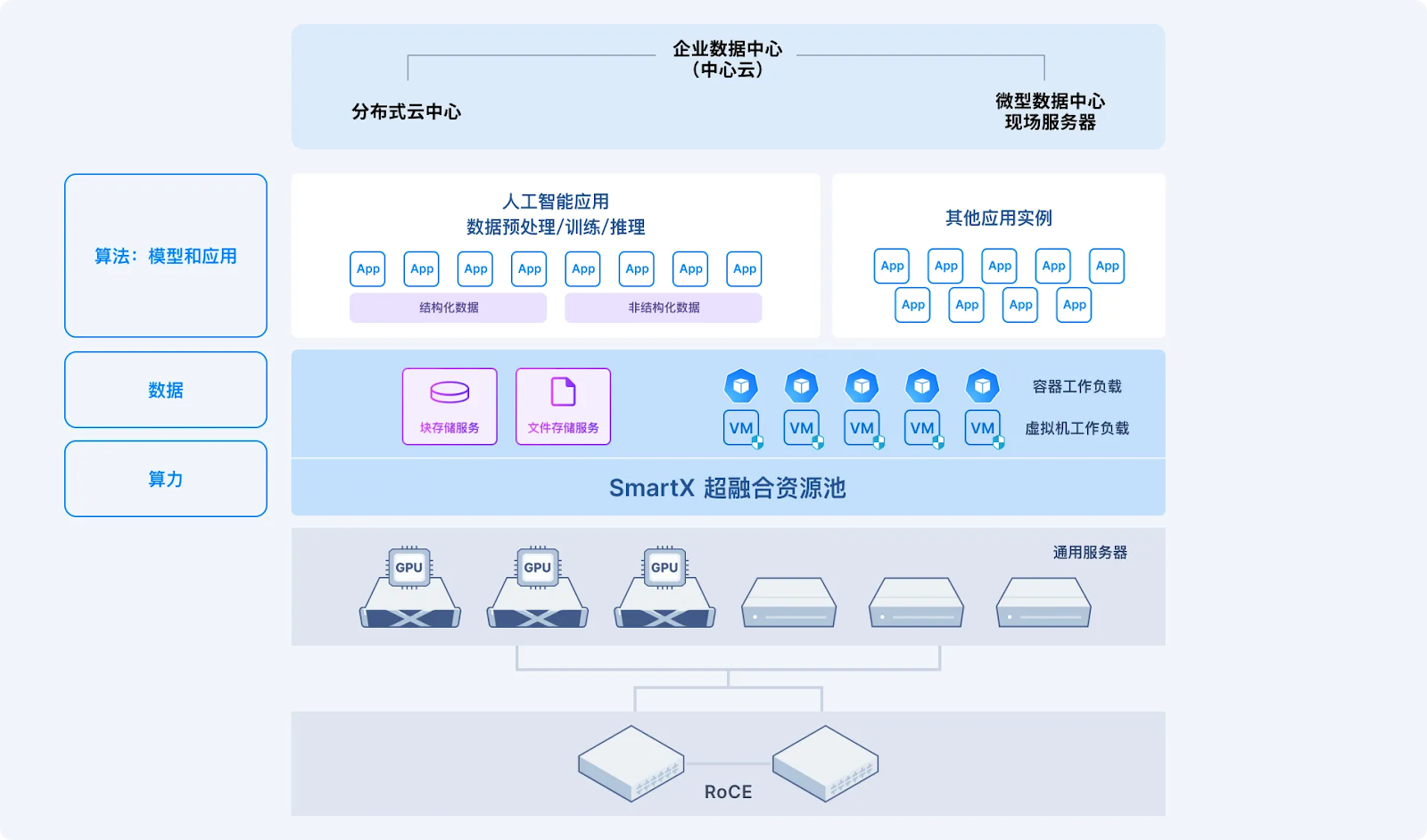
您还可点击链接下载《SmartX 分布式存储产品组合介绍》,了解 SmartX 分布式存储的更多功能特性和 AI 支持能。