作者:SmartX 研发团队 余彦臻
很多企业都在构建私有知识库,辅助 AI 大模型提供企业级服务。不过想要训练 AI 完美理解企业内部知识并输出符合预期的内容,可能需要反复地调优测试。近期,SmartX 研发团队从企业内部培训场景出发,让 AI 大模型基于内部知识库进行“考试”,并通过多种调优方式提升模型考试成绩。在实验过程中,我们没有使用 Dify 等封装后的工具,而是基于最基础的 LLM API 调用方式进行实现,希望可以让读者更好地观察其中的细节。以下,我们将分享上述实践,并展示企业知识库构建与调优过程中可能遇到的种种挑战与应对策略。
下载《构建企业 AI 基础设施:技术趋势、产品方案与测试验证》电子书,了解更多企业 AI 大模型与基础设施建设方案、实践与评测!
经验一:构建企业自己的 Benchmark
在搭建知识库或进行模型测试前,我们认为先建立一个自己的 Benchmark 非常重要。虽然大模型在发布的时候都会提供一些基准的 Benchmark,但这些 Benchmark 只能让我们宏观地看到模型大致是什么水平,而模型在企业自己的应用场景中具体表现如何,哪些调优是有效果的,或者是否会因为提示词、知识库质量等细节问题导致模型达不到预期,这些都需要企业自己建立一个 Benchmark 来进行衡量。因此,我们选择了企业内部培训这一适合构建 Benchmark 的场景,来开展本次实践。
首先,我们让 AI 在没有任何文档输入的情况下直接做一下培训试卷。这里我们使用 AI 把试卷处理成 JSON 格式的结构化数据,包括试题问题、选项、正确答案和赋分,然后用代码写一个打分程序,最后让不同的 LLM 直接做试卷并观察他们的得分。比如我们这套试卷一共 55 道题、满分 108 分,DeepSeek V3 作答得分是 69,那这个模型的 Benchmark 就是 69/108 = 63.9%。
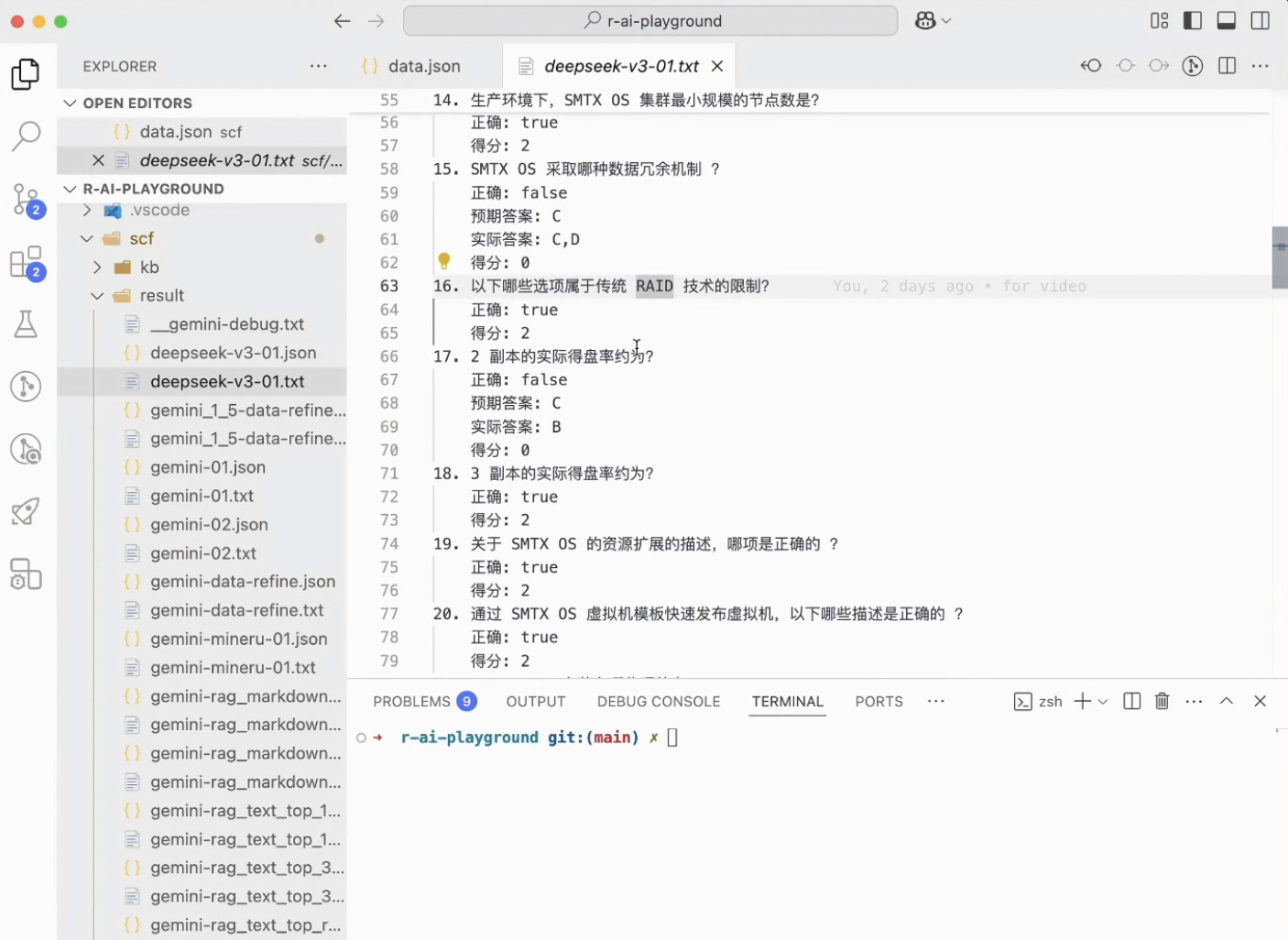
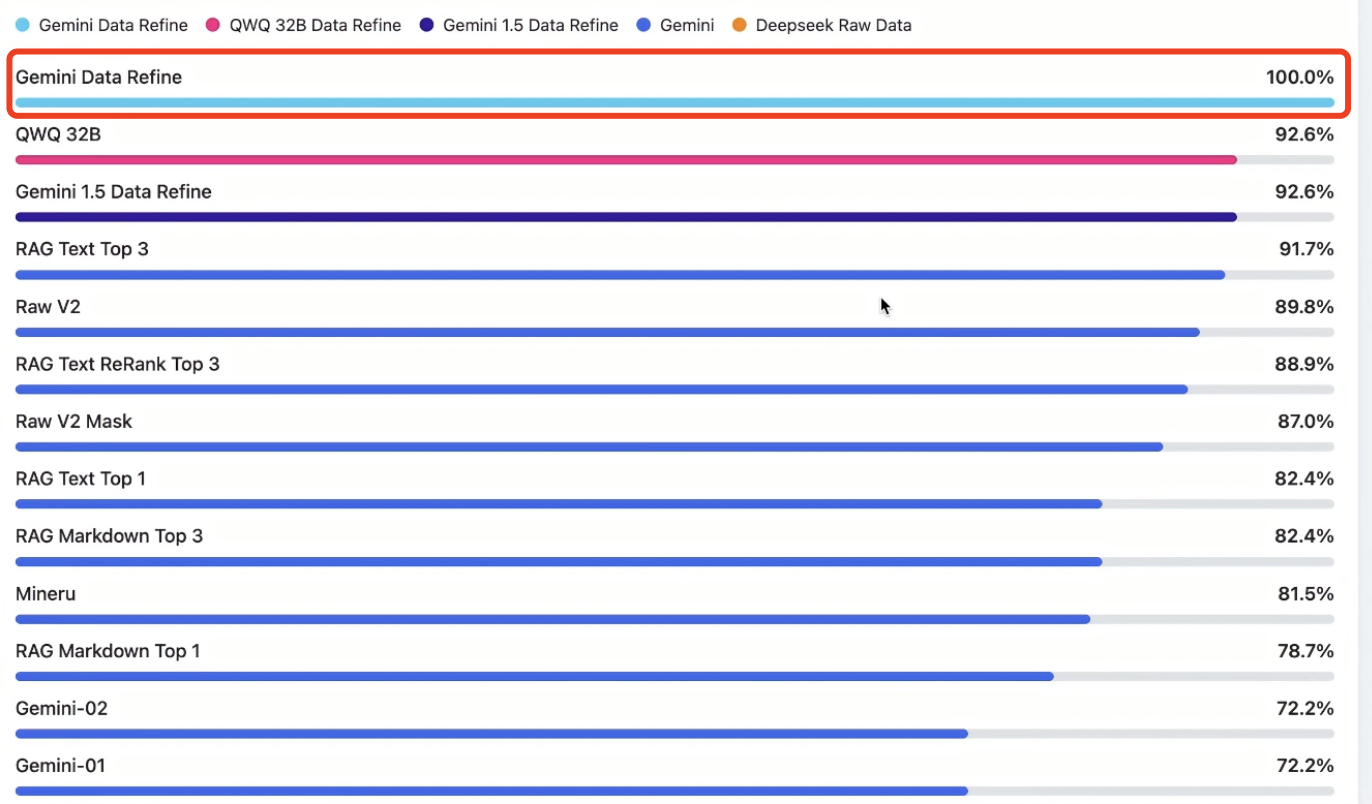
有了 Benchmark 框架,我们就可以快速测试不同的模型和提示词,并对比他们的表现。我们首先对比了大家比较熟悉的 DeepSeek V3 和 Gemini 2.0,后者是目前第一梯队的闭源模型。后续的测试和优化将主要基于 Gemini 2.0 进行,这里与 DeepSeek V3 对比是为了让读者对 Gemini 2.0 的性能有初步的感受。可以看到,在裸考的情况下,Gemini 2.0 可以达到 78/108 = 72.2% 的表现,整体性能略强于 DeepSeek V3。这里我们对 Gemini 连续进行了两轮测试,观察模型的稳定性。实际上,一个更严肃的 Benchmark 应该是持续跑更多轮次,观察平均水平。在此次实验中我们对这一操作做了简化,后续测试仅执行一个轮次,因此存在一定的概率偏差。

经验二:不要急于导入/调优知识库,应先确认数据准确性
我们观察到,裸考的 AI 面对涉及企业私有信息的题目基本上都答不出来,所以接下来我们就要构建企业知识库,帮助 AI 提高考试分数。
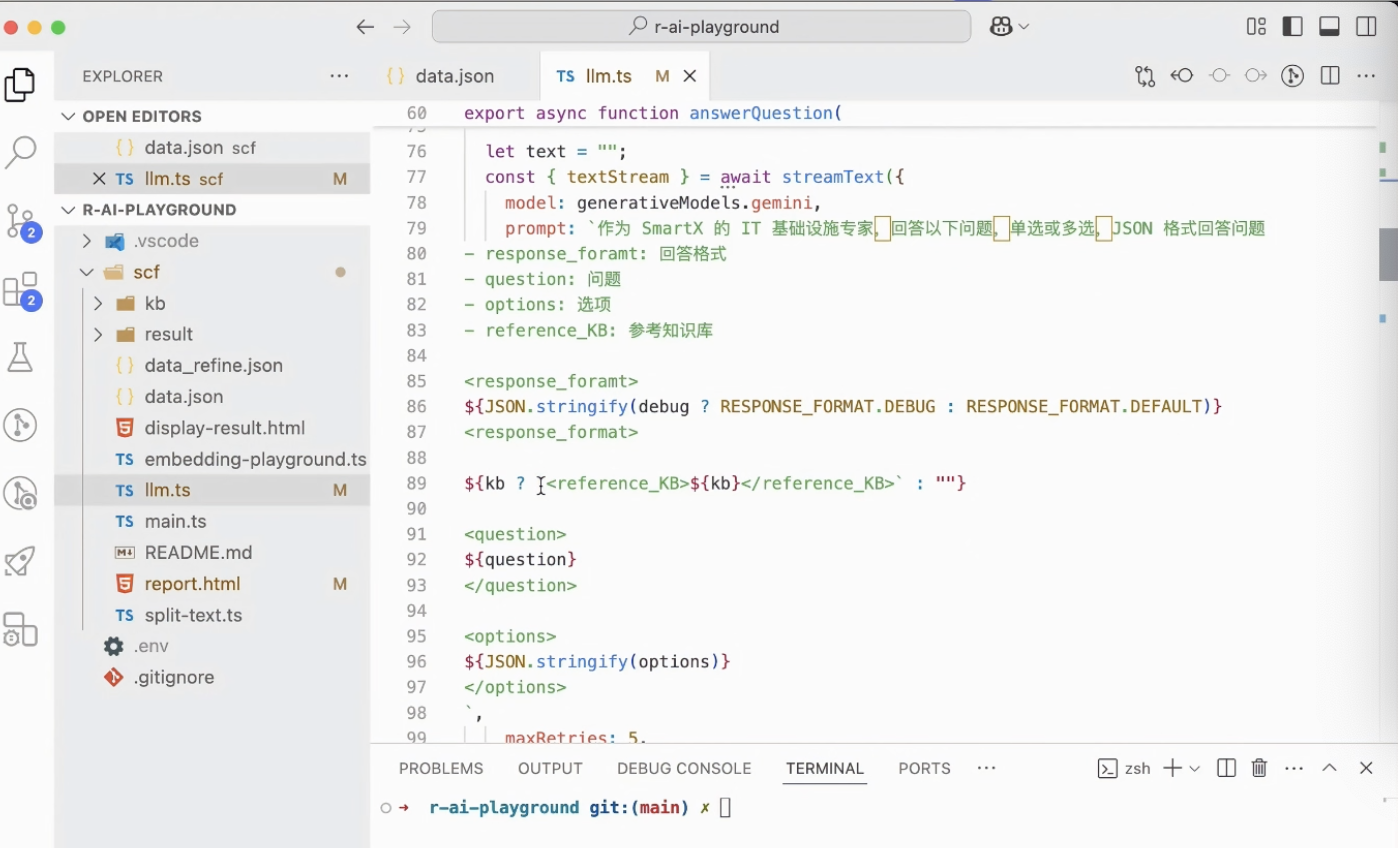
首先,我们模拟员工的学习过程,导入培训时使用的 40 页文档。我们先使用 MinerU 工具将 PDF 转换成 Markdown 格式。这里对于结构较乱、图片较多的 PDF,可能需要更好的数据清洗工具,但对于我们的培训文档,MinerU 的解析效果已经足够好。然后我们将第一版知识库提供给 Gemini 2.0,提示词如下所示。这里有个小技巧:我们在提示 LLM 四个区块的内容时,可以用了一个类似于 XML 的 tag 来分割,因为 LLM 在训练的过程中接触的训练数据就是用类似 XML 的方式来分割的,LLM 可能对此更熟悉一点,更重要的是我们在维护提示词时也更容易理解。
在将每一道题发给 LLM 的时候,我们都会把 PDF 对应的 Markdown 作为文本注入到提示词中,在这个版本下,我们的提示词长度较长。
在这个基础上,我们让 Gemini 重新进行一次考试,结果分数从 78 提升到 88。其实这个是不太符合预期的,因为我们提供了 40 多页的信息,但是最终只提高 10 分。在人工确认 AI 作答情况后,我们发现,这个 PDF 里确实缺少一些题目的答案,导致 AI 作答不出来。在进行内部沟通后,才确认第一版的 PDF 其实是一个过时的版本,最新版本是一个 70 页的 PDF。其实这里已经体现了 Benchmark 的重要性——如果没有一个完整的 Benchmark,这种很基础的数据疏漏可能都难以发现。
在更新了知识库后,我们再次让 Gemini 进行考试,最终得到了 97 分的结果(97/108=89.8%),相对来说比较符合直觉。不过我们还是回顾下 AI 的作答,发现这个成绩其实有点虚高——70 页的 PDF 文档中包含一些提供了答案的练习题,与考试题目非常接近。所以,我们对数据进行了修正,删掉了练习题,得到了一个 Musk 版本的知识库文档,让 Gemini 第四次进行作答。结果也是比较符合直觉的——考试结果下降到了 94/108=87%。

这一过程也给了我们一个很重要的经验教训:在导入数据库或进行调优前,一定要先确认好知识库数据的准确性,保证后续的测试结果是可靠的。
经验三:使用 RAG 优化知识库导入,小心 Embedding“陷阱”
虽然目前这个成绩还不错,但知识库的提供方式还是有优化空间的——在 AI 每一次回答问题时,我们都把整个知识库全量导入给 AI,让 AI 每次都在大海捞针般寻找答案。这也是全量导入的缺点:
- 不能扩展:通过计算发现,70 页的知识库 Markdown 文档占了 5 万多个 token,对于大部分模型 12.8 万的上下文空间来说已经占了近一半,如果后续知识库继续扩展,token 可能已经超过上下文空间,不能在一次对话中全部提供。
- 贵:使用公有 LLM 的 API 会按照 token 来计费,频繁导入大量知识库文本将产生高昂的成本。
因此,我们引入 RAG(检索增强生成)技术,先从整个知识库中搜取与当前对话相关的内容,然后再导入给 AI。RAG 的原理是将整个知识库文档切分为多个“碎片”,根据对话选择相关性最高的几个片段进行组合,然后将缩短后的上下文提供给 AI。不过 RAG 在“切分”和“对话选择”上也有许多不同的方法,在我们的实验中,我们首先对比了两种切分(Text/Markdown)和两种对话选择(选择 Top1/3 相关片段)方法,观察他们对考试结果带来的影响。
切分方式
- Text:将文档当成普通文本来切,这里我们选择每 3000 字符切一次,但完全基于长度的切分不会考虑具体的内容,会将两个有相关性的内容分隔开。
- Markdown:基于 Markdown 格式的切分,可以理解 Markdown 的语义,因此切割更精确一些,可以避免把一些段落分隔开(例如,不会把子标题和下面的内容分隔开)。

匹配的数据量
- Top 1:取匹配度最高的一个数据块提供给 AI。
- Top 3:取匹配度最高的三个数据块提供给 AI。
在实际测试中,相同切分方式下,Top 3 的得分总是高于 Top 1 的。例如 Text 切分下 RAG Top 3 结果是 91.7%,Top 1 是 82.4%。这是因为 Top 3 策略下提供的数据量更多,AI 表现也更好。

(红框为 Text 切分,绿框为 Markdown 切分)
不过这里我们观察到两个问题:首先是为什么 Top 1 和 Top 3 的结果差异这么明显,其次是为什么对 Markdown 语义理解更好的切分方式反而不如基于 Text 的切分方式。对于第一个问题,考虑到我们此次切分的碎片其实是比较大的,而且答案对应的信息在原文中并不分散,且篇幅较短,正好被切分为两个碎片的概率很小,在这种情况下 Top 1 和 Top 3 的结果差异如此明显,说明选择 Top 1 时相关性第一的碎片有时并不包含题目的答案,选择 Top 3 时,才将答案包含在内。而 Markdown 碎片的平均长度更短,不论选择 Top 1 还是 Top 3,其信息总量都不如 Text 碎片。如果相关性的判断确实存在问题,那么信息量的差距就会更加明显。
而相关性判断不准确的“元凶”就是 RAG 中的必备环节: Embedding。简单来说,Embedding 会把一段文本算成一个向量(一组数字),在匹配相关性时会比较两个向量间的相似度(距离的远近)。Embedding 的原理非常清晰,但在实践中很可能没有大家想象的健壮。尤其是在我们的实验场景中,每个碎片长度长,信息含量大,且都是 IT 领域的知识,碎片之间的相似性本就很高。另一方面,当我们用“问题”去匹配“答案”的语义相似度时,不同的语气、表达方式也对相似度有影响,结果远不如比较两个词语的相似度来的简单。
我们在这里也针对 Embedding 进行了一个实验,用一道易错题“获得哪种授权后 SmartX 可以永久使用?”的向量与所有答案碎片的向量进行计算,比较相似度。
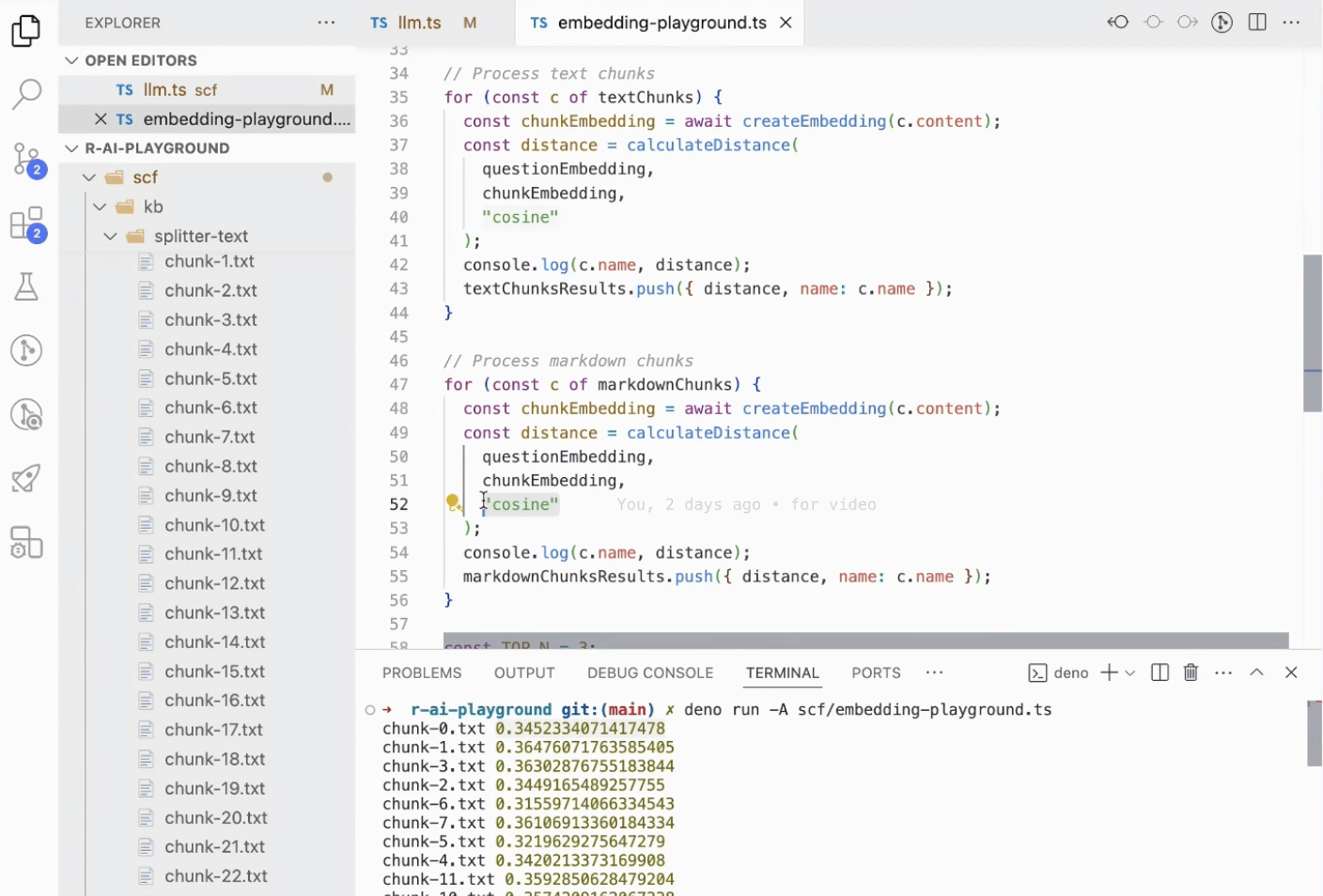
其中,采用 Text 切分,匹配度前三的文本都是在介绍 Kubernetes 的内容,与题目没有一点相关性。采用 Markdown 切分,虽然 Top 3 碎片的内容依旧没有命中答案,但匹配结果看起来更可靠一点,分别是关于产品介绍章节的描述、关于 Kubernetes 的介绍,以及收费介绍,至少有两个文本提到了相关内容。不过这个可能也跟 Markdown 切分(40+ 碎片)比 Text 切分(20+ 碎片)更细致有关系,但如果 Markdown 包含的信息变多,很可能也退化为与 text 切分类似的结果。
总的来说,切片太大相似度不可靠,切片太小信息量不足,这也就导致 RAG 与全量注入提示词的方案相比,性能是有所下降的。
经验四:采用 Re-ranking 应对 Embedding 短板,效果不明显
随后,我们又尝试了一种 RAG 的改进措施——Re-ranking。Re-ranking 的思路是在原本的相似度匹配阶段选择一个更大的范围——例如 Top 10 的碎片——再将 10 个碎片交给专门用于排序的 LLM(Re-ranking 模型),按内容与问题的关联性重排,以此填补 Embedding 的短板。不过现在专门做 Re-ranking 的模型不是很多,此次实践中,我们通过一组提示词(如下图所示),让 Gemini 2.0 伪装成了一个 Re-ranking 的模型进行排序(考虑到 Re-ranking 专用模型一般是参数量较小的模型,因此可以理解为我们模拟的 Re-ranking 模型实际性能很可能不弱于专用模型)。

不过,在实际考试中,进行 Re-ranking 优化的 AI 得分(96/108=88.9%)并没有超越原有 RAG 得分(91.7%),可见在我们的场景中,Re-ranking 对 LLM 考试结果的提升不明显。

经验五:没有达到满分,并不一定说明 LLM 没有达到预期
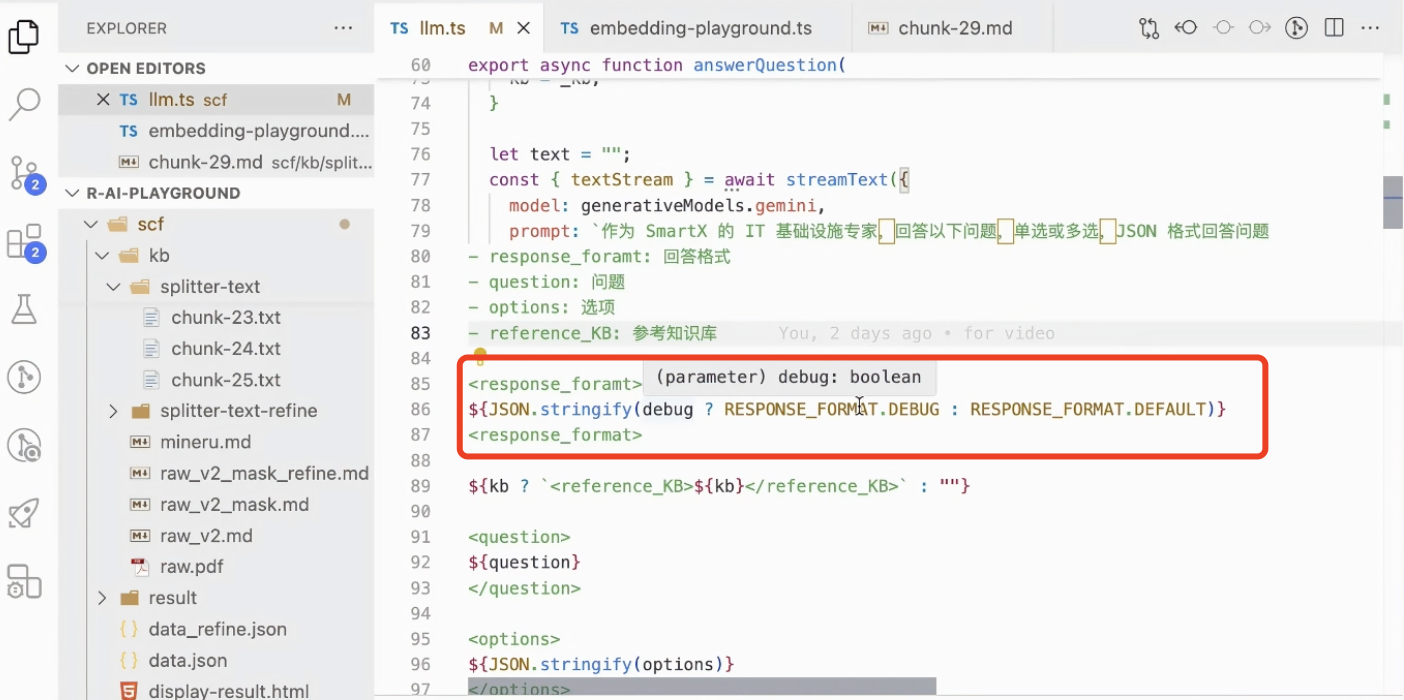
为了找到 LLM 答错的根本原因,我们开始尝试 debug LLM。我们在 LLM 中实现 debug 的方式比较简单,当开启 debug 模式时,我们会在提示词中告知 LLM,除了返回选项,也要对选择的原因作出说明。这样我们就可以在错题中审查 LLM 做错的具体原因。
随后,我们在 RAG 选择 Text – Top 3 的模式下,开启 debug 模式,再次进行测试。在一一审查时我们发现 ,AI 没有回答正确,并不是 AI 不够聪明,而是他比我们想的更严谨。比如,对于一道判断题“Everoute 对虚拟机进行隔离后,虚拟机上原有的应用不能被继续访问”,预期的正确答案是“对”,但 LLM 判断为“错”;在阐述为什么选“错”时,LLM 认为知识库中提到,虽然 Everoute 对虚拟机进行隔离时会切断虚拟机与其周边的通讯,但用户可以通过“诊断隔离白名单”的功能,允许隔离虚拟机和特定的虚拟机(如跳板虚拟机)进行单点通信,所以并非完全不能访问原有应用。这道判断题更严谨的表述应该是:“Everoute 对虚拟机进行隔离后,在不启用诊断隔离白名单的情况下,虚拟机上原有的应用不能被继续访问”。
其他的错题也是如此。这种情况下,我们认为 AI 的表现其实已经达到了我们期望的“学习并准确作答”的要求,没有达到满分可能是因为知识库/试题表述不够严谨。在对知识库和考题进行了微调,让知识库和考题的描述更加严谨后,我们再让 AI 进行考试(Text – Top 3 + debug 模式),这次就顺利达到了满分。由此可见,在 Benchmark 不及预期时,有时重新审视数据,比盲目的改变方法更为有效。此外,在过程中我们观察到的 Embedding 表现较弱的问题仍然存在,只是我们较大的碎片长度规避了这一问题,当知识库数据量变大时,这一环节的问题很可能被进一步放大。
在拥有易用的 Benchmark 框架之后,再测试新的模型也变得非常简单。例如我们又测试了 Gemini 1.5 和千问 QWQ 32B 的模型,两者的结果都是 92.6%,这也与他们性能和成本都低于 Gemini 2.0 是相对应的。当我们想降低模型成本时,就可以继续沿用上述的分析方法,找到在低成本模型上提高分数的方法,完成模型降级。再次强调,自建 Benchmark 是高效、精确完成这一迭代过程的关键。
SmartX 研发与产品团队将在近期陆续分享更多企业 AI 私有化部署、调优与评测实践,欢迎感兴趣的读者持续关注。您还可点击链接获取《构建企业 AI 基础设施:技术趋势、产品方案与测试验证》电子书,了解更多 AI 私有化部署技术知识!
推荐阅读: