重点内容
- 榫卯超融合 6.3 引入 IO_uring 内核异步 I/O 框架、Intel DSA 硬件加速、多链路互联、存储多实例等技术,从系统内核、硬件加速、存储网络聚合、存储扩展四大维度重构高性能底座,让 “高性能与低成本兼得”。
- x86/海光/鲲鹏三大 CPU 架构平台性能均显著提升,充分满足高性能业务运行与核心业务信创转型需求。实测数据表明,x86 平台性能突破 1100 万 IOPS 和 130 GiB 带宽,平均延迟低于 100us;信创平台性能也达到 400 万 IOPS 和 40 GiB 带宽。
- 基于存储的性能优化,榫卯超融合 6.3 可帮助企业高效应对信创数据库场景挑战:鲲鹏平台+达梦数据库,实测性能业内领先。
随着数字化转型的逐渐深入,核心数据库、信创业务系统、实时交易、视频分发、金融行情等关键负载,对 IT 基础设施的要求已经从 “能用、稳定”,升级为 “兼顾高性能与成本优化”。但在传统架构中,高性能与低成本始终无法兼得:
- 为满足高并发、高吞吐、低延迟的业务诉求,企业往往依赖高端硬件堆叠、冗余资源预留,导致 TCO 居高不下,硬件利用率难以提升。
- 若单纯追求降本而压缩硬件投入,又极易引发 I/O 瓶颈、并发不足等问题,让企业陷入 “想提效不敢加成本、想降本又怕性能崩盘” 的两难困境。
榫卯超融合 6.3 从系统内核、硬件加速、存储网络聚合、存储扩展四大维度全面重构性能底座,通过四大核心高性能特性,让 “高性能与低成本兼得”:
- IO_uring 内核异步 I/O 通路:采用新一代 Linux 内核异步 I/O 框架,减少系统调用与数据拷贝,用更少 CPU 资源跑出更高 I/O 性能,高并发场景延迟明显降低。
- Intel DSA 硬件数据流加速:依托新一代处理器内置 DSA 引擎,硬件级卸载内存复制、数据搬运等操作,提升带宽、降低 CPU 占用,将更多算力留给业务。
- 多链路互联(用户态 bonding):节点间建立多条 TCP/RDMA 逻辑链路,业务层智能分流,充分利用多网卡带宽,告别单链路瓶颈。
- 存储多实例弹性扩展:支持多物理盘池独立运行,物理盘可按需扩容,大幅提升集群吞吐与 I/O 并发能力,适配高密度负载。
性能实测:Intel 平台满足极致性能业务需求,信创平台性能“创新高”
随着信创全面深化、企业 IT 多芯化架构并行,超融合方案能否在 x86、海光、鲲鹏等不同 CPU 架构下都提供稳定、可预期的高性能输出,已经成为企业选型的核心标尺。
传统超融合架构往往存在“x86 平台性能拉满、信创平台性能打折”的痛点,让企业在信创迁移过程中,不仅要面对架构适配的复杂度,更要承担核心业务性能下降、体验打折的风险,最终陷入“为了合规牺牲性能”的难题。
榫卯超融合 6.3 从底层架构出发,针对 Intel、海光、鲲鹏三大主流 CPU 架构完成全栈深度优化,真正实现“一套系统,全架构适配,一致高性能体验”,满足极致低延迟业务需求并打消企业信创迁移的性能顾虑。
测试环境
为了客观验证榫卯超融合 6.3 在不同 CPU 架构下的性能上限,我们构建了统一的三节点物理集群测试环境。在保持集群规模一致的前提下,针对 Intel x86、海光 Hygon、鲲鹏 Kunpeng 三种主流平台分别部署测试环境。
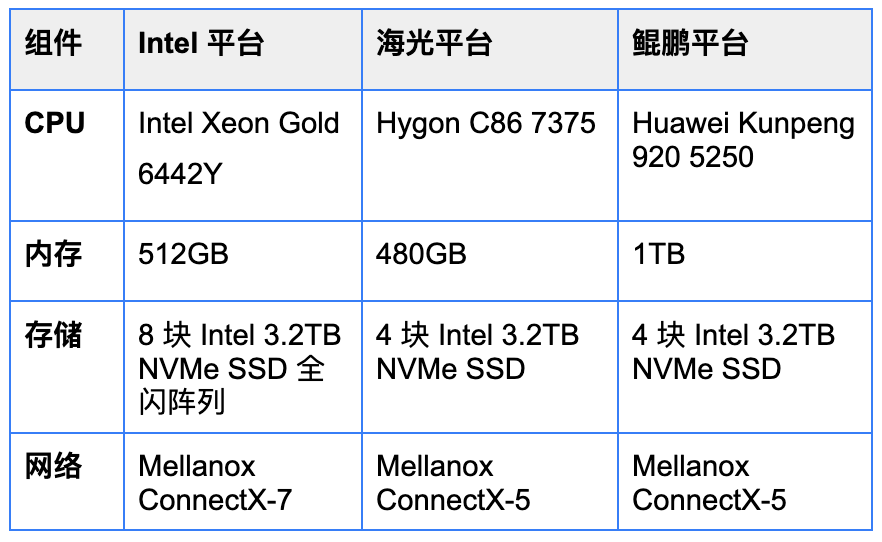
以上环境均开启了榫卯超融合的 Boost 模式与 RDMA 高速传输能力,采用 3P6V(3 节点 6 虚拟机)高并发模型进行测试,以下核心性能数据均基于此标准环境产出。
性能实测
4K 随机读写
4K 随机读写是衡量超融合存储性能、支撑核心数据库(MySQL/Oracle 等)高并发业务的核心指标。并发数和队列深度为(1*1),三大架构实测表现如下:
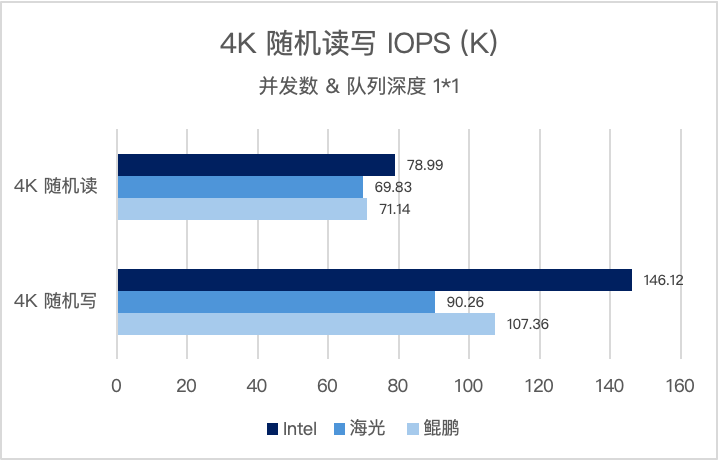
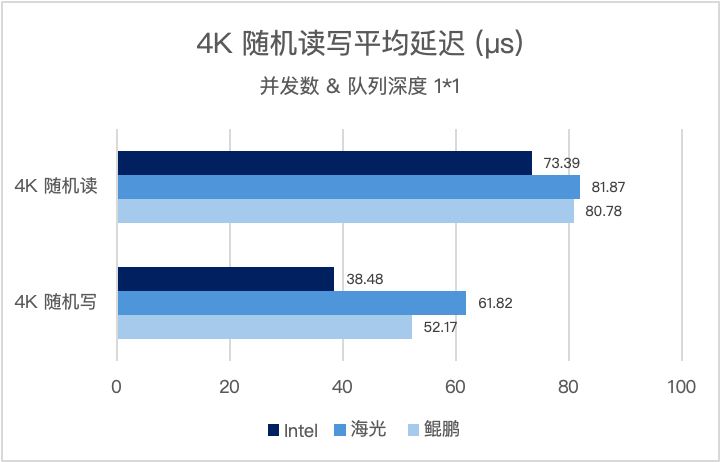
并发数和队列深度为(8*64),三大架构实测表现如下:
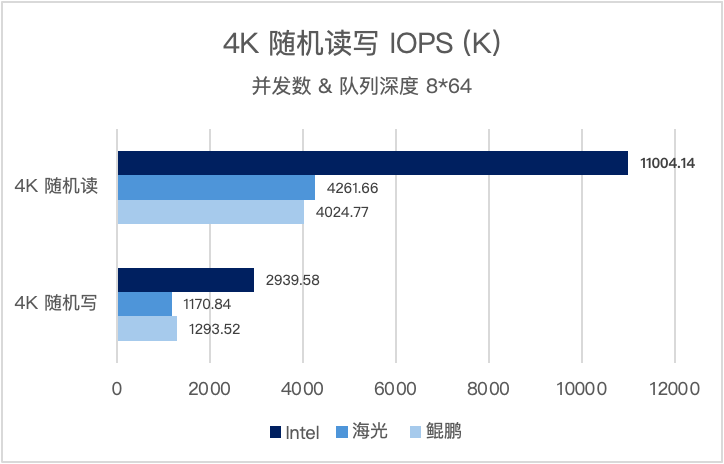
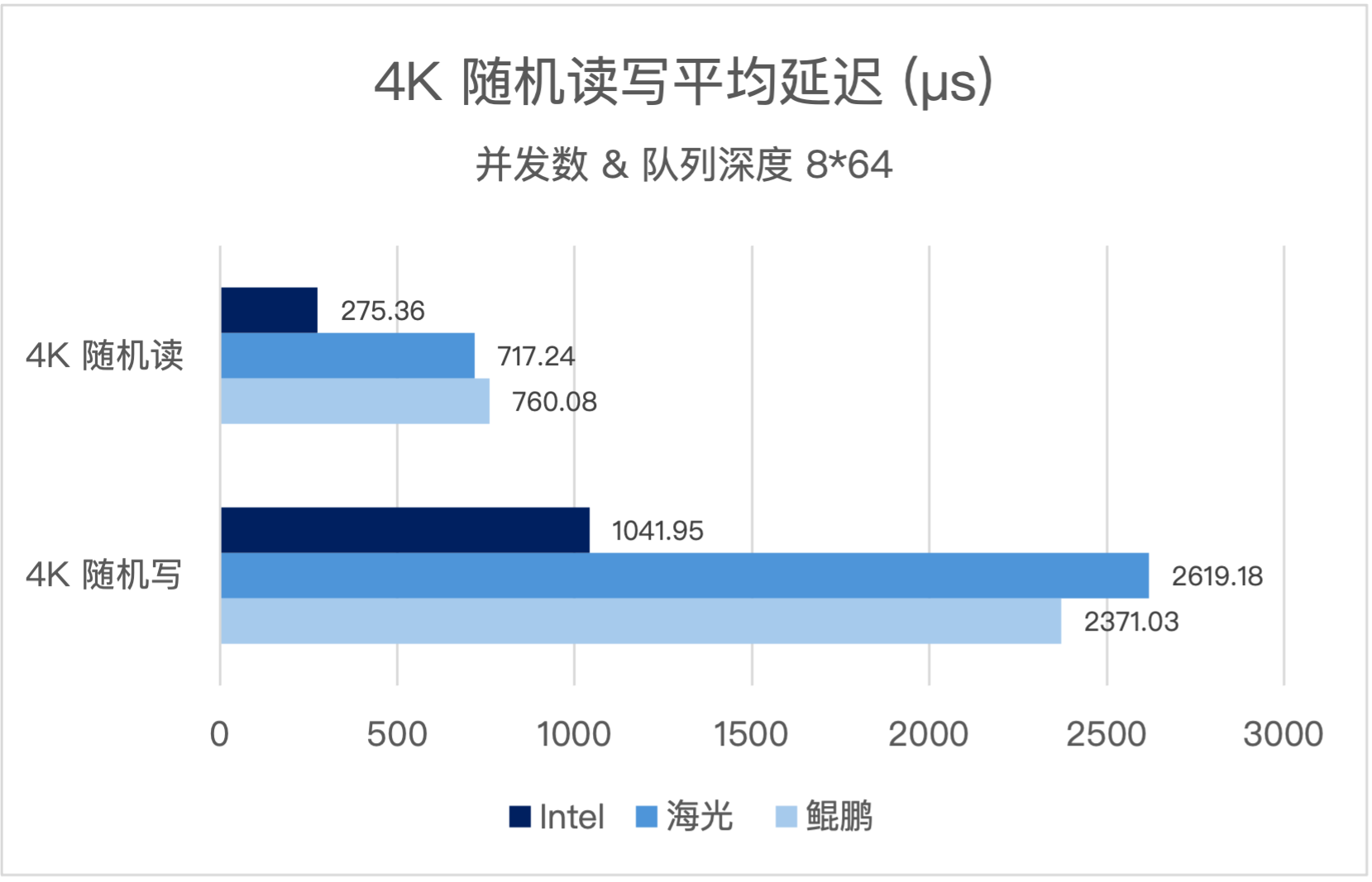 测试结果表明,三种 CPU 架构平台均实现了显著的性能提升,性能表现符合各自硬件算力基线,企业可根据业务需求灵活选择硬件平台,无需担心性能波动:
测试结果表明,三种 CPU 架构平台均实现了显著的性能提升,性能表现符合各自硬件算力基线,企业可根据业务需求灵活选择硬件平台,无需担心性能波动:- x86 环境:在 8*64 的高并发 4K 随机读场景下,实现了超 1100 万 IOPS 的极致性能;在 1*1 的理想情况下,极致的平均延迟低于 100us,可充分满足金融、制造等行业核心系统的高并发、低延迟需求。
- 信创环境:在 8*64 的高并发 4K 随机读写场景下,海光、鲲鹏平台均实现超 400 万随机读 IOPS 的性能基线,随机写性能也能稳定在百万级别;在 1*1 的理想情况下,极致的平均延迟低于 100us,打破 “信创平台性能显著下滑” 的行业误区。
256K 顺序读写性能
256K 顺序读写是衡量超融合存储带宽能力,支撑大数据分析、备份恢复等大流量业务的核心指标。并发数和队列深度为(1*1),三大架构实测表现如下:
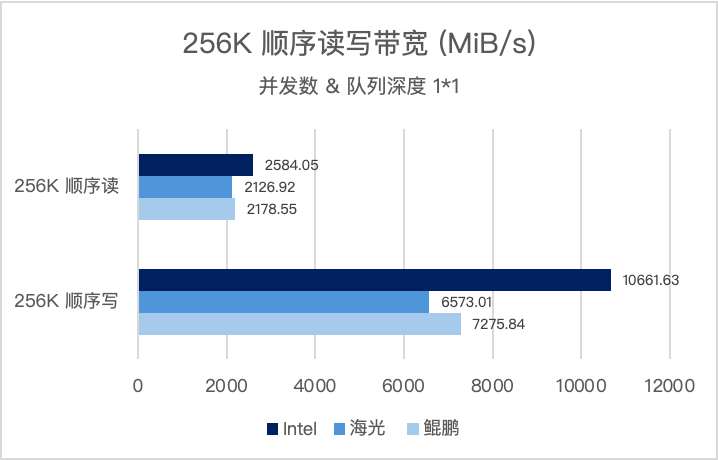
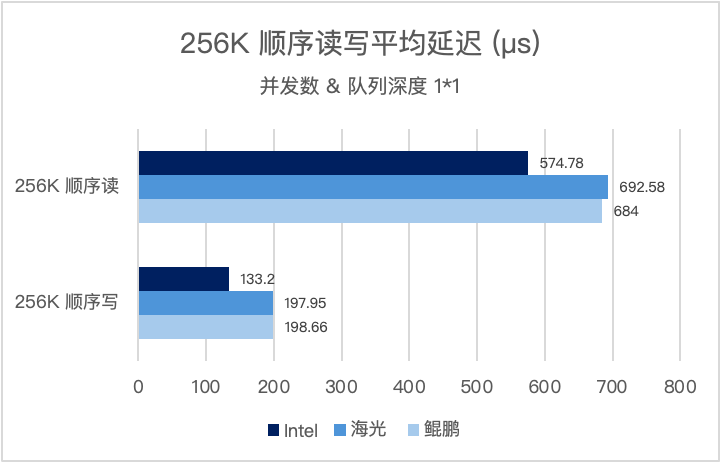
并发数和队列深度为(8*32),三大架构实测表现如下:
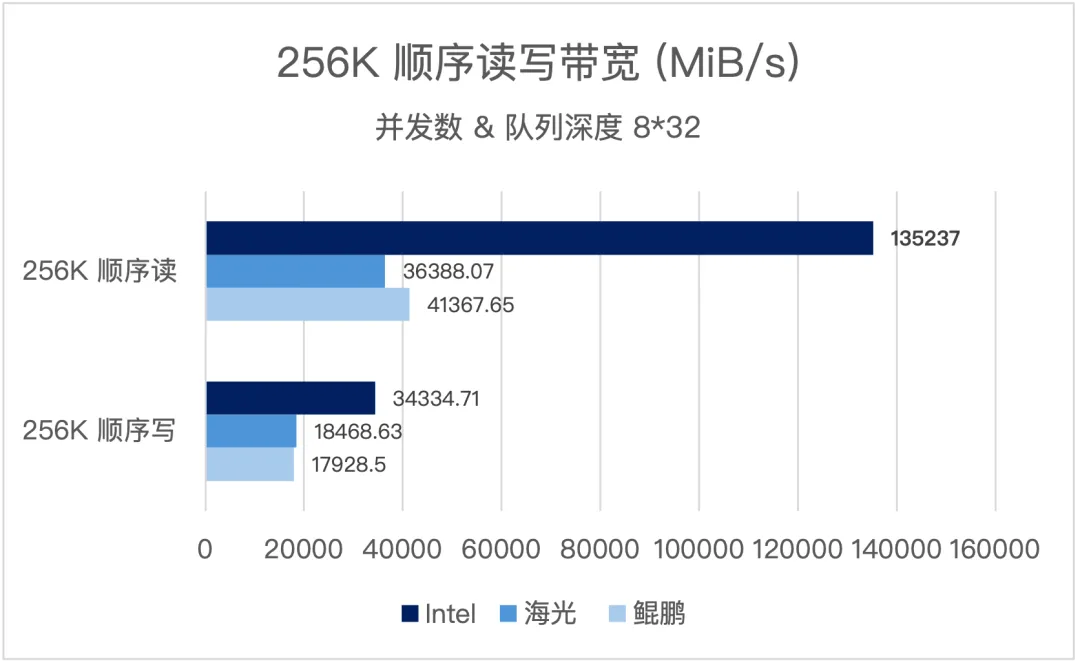
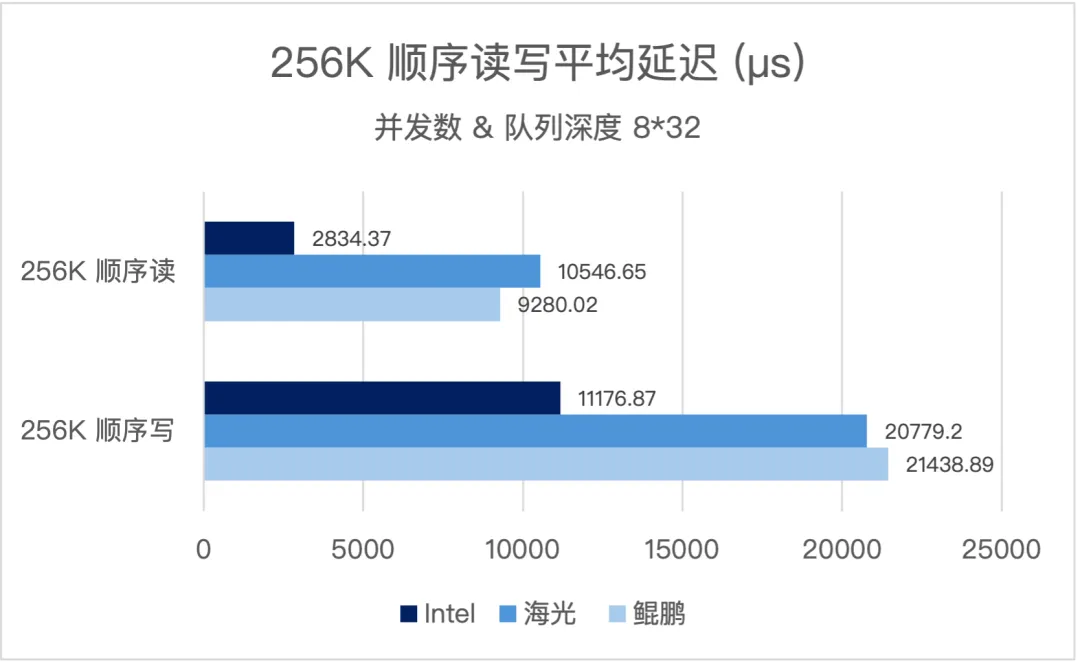 三大架构在顺序读写场景下均提供了高吞吐、低延迟的性能表现,能够覆盖企业从核心交易到大数据分析的全业务场景性能需求:
三大架构在顺序读写场景下均提供了高吞吐、低延迟的性能表现,能够覆盖企业从核心交易到大数据分析的全业务场景性能需求:
- x86 环境:顺序读带宽突破 135000 MiB/s(约 135GiB/s),顺序写带宽超 34GiB/s,可轻松应对大数据、AI 训练等大带宽业务场景。
- 信创环境:海光、鲲鹏平台顺序读带宽均达到 36-41 GiB/s 级别,顺序写带宽超 18 GiB/s,满足信创环境下大数据分析、备份等业务的带宽需求。
- 一致高性能体验:三大 CPU 架构下性能均表现出色,企业无需为不同平台单独调优,真正实现 “一套系统,全架构适配”。
- 信创迁移无忧:海光、鲲鹏架构均实现超 400 万 4K 随机读 IOPS,打破 “信创 = 性能打折” 的行业偏见,帮助企业实现核心业务的平滑迁移。
- TCO 持续优化:充分释放不同架构的硬件潜能,提升硬件利用率,避免为了性能盲目采购高端硬件,降低长期 IT 成本。
- 全栈生态兼容:完美适配三大 CPU 架构的硬件、操作系统、数据库、中间件生态,满足信创合规要求,支撑企业多元化 IT 架构建设。
核心技术揭秘:四大维度优化,拉满超融合存储性能
全架构高性能的背后,并非简单的硬件堆叠与参数调优,而是榫卯超融合 6.3 从系统内核、硬件加速、存储网络聚合、存储扩展四个维度,对超融合架构进行的深度增强。
IO_uring 内核异步 I/O 通路:重构存储 I/O 效率,用更少的 CPU 跑出更高性能
传统 Linux 存储 I/O 模型,就像 “每次取快递都要亲自跑一趟驿站”:应用每发起一次 I/O 请求,都要触发系统调用、上下文切换,高并发场景下不仅 CPU 被大量占用,还会出现明显的延迟抖动,成为性能瓶颈。
榫卯超融合 6.3 引入新一代 IO_uring 异步 I/O 框架,从内核层优化 I/O 路径:
- 共享队列机制:用户态与内核态直接共享 I/O 命令队列,有效减少系统调用次数,告别频繁 “跑腿”。
- 零拷贝优化:数据无需在内核与应用之间反复搬运,直接在共享内存中完成传输,延迟显著降低。
- 异步批处理:支持批量提交与批量完成 I/O 请求,高并发场景下 CPU 占用大幅下降。
- 稳定低延迟:在数据库、虚拟机等高 I/O 负载下,实现更高 IOPS、更平稳的延迟表现。
打个比方,IO_uring 把 “逐次跑腿取快递” 变成了 “驿站批量送上门”,用更少的 CPU 资源,跑出了更高、更稳的存储性能。
Intel DSA 硬件数据流加速:让专业硬件干专业事,释放 CPU 算力
CPU 的核心价值是跑业务,而不应该把大量算力浪费在数据拷贝、数据搬迁、数据压缩等这类 “体力活” 上。榫卯超融合 6.3 采用新一代 Intel CPU 内置的 DSA(Data Stream Accelerator)硬件加速引擎,实现了算力的精准释放:
- 硬件级卸载:将内存拷贝、数据移动、整理等通用操作,从 CPU 通用计算中剥离,交给专用硬件处理。
- 释放业务算力:相同存储负载下,存储服务的 CPU 占用显著降低,更多算力留给核心业务。
- 带宽大幅提升:数据搬运速度由硬件加速,大 I/O、高吞吐场景下性能收益极强。
- 与 IO_uring 协同增效:异步 I/O 框架 + 硬件加速引擎,形成 “双引擎” 性能底座,1+1>2。
让专业硬件干专业的 “体力活”,CPU 可以专注于核心业务,性能自然拉满。
多链路互联:打破单链路瓶颈,发挥网卡全部带宽
传统超融合的节点间通信,就像“一条单车道高速”:即便做了网卡 Bonding,也只能用单链路带宽,多网卡的冗余能力无法转化为实际带宽,高并发场景下容易出现链路瓶颈。榫卯超融合 6.3 采用用户态多链路互联技术,彻底打破带宽天花板:
- 节点间建立多条 TCP/RDMA 并行逻辑链路,把 “单车道” 变成 “多车道并行高速”。
- 业务层智能分流、动态负载均衡,充分利用每一张网卡的带宽。
- 多网卡带宽真正叠加,不再受单链路限制,集群整体吞吐线性提升。
- 搭配 RDMA 高速网络,同时实现高带宽与低延迟。
基于此,网络不再是性能瓶颈,多网卡的潜能被充分发挥。
存储多实例:弹性扩展并发,告别单进程性能天花板
当集群规模扩大、虚拟机数量增多,传统超融合的“单存储进程”架构,就像“一个窗口办所有业务”,很容易出现队列阻塞,成为性能天花板,无法支撑高密度、高并发负载。
榫卯超融合 6.3 推出存储多实例(多物理盘池)架构,从架构层面解决并发瓶颈:
- 单个节点可运行多个独立存储实例,把“一个窗口” 变成 “多个窗口并行服务”。
- 协议处理、磁盘 I/O、网络转发等核心能力,可按需横向扩展。
- I/O 流分散并行处理,避免单队列阻塞,高负载下性能线性提升。
- 在 3P6V 等高并发测试模型中,多实例架构带来了较好的性能收益。
存储多实例让超融合的并发能力,不再受限于单进程,真正实现了“越扩容、越强劲”。
从 IO_uring 重构内核 I/O 路径,到 DSA 硬件加速释放算力;从多链路互联打破带宽瓶颈,到 多实例架构扩展并发能力,榫卯超融合 6.3 用一套完整的底层技术组合,真正实现了不堆硬件、不浪费资源、全架构优化、性能稳定可预期,这也是其能在 Intel、海光、鲲鹏不同架构平台下跑出顶级性能的核心原因。
场景性能实测:信创数据库高性能改造
对于企业而言,数据库是业务运转的“心脏”,信创改造则是当下数字化转型的“必答题”。对于信创替代中的国产数据库迁移,极致性能、稳定可靠、成本可控,已成为企业最核心的诉求。榫卯超融合 6.3 通过全栈性能优化和架构级适配,打造了一套“性能不打折、迁移无风险、TCO 更低”的数据库承载方案,实现信创数据库的高性能改造。
信创场景实测:国产平台 + 国产数据库,性能不打折
场景挑战
如何在信创平台上保障核心数据库的高性能及平稳运行,是信创改造的核心挑战,具体包括:
- 信创平台性能短板:海光/鲲鹏架构 CPU 的生态与性能略显不足,传统超融合如果适配不好,会出现数据库迁移后性能大幅下滑的情况,无法支撑业务运行。
- 迁移风险高:信创迁移过程中,架构适配、性能调优复杂度高,容易出现兼容性问题,影响业务连续性。
- 生态适配复杂:国产数据库、中间件、操作系统的组合多样,超融合需要完成全栈适配,才能保障业务稳定运行。
解决方案
针对信创场景,榫卯超融合 6.3 完成了从硬件到软件的全栈深度适配,为国产数据库打造可平滑迁移、高性能的解决方案:
- 全 CPU 架构深度优化:针对海光、鲲鹏等国产 CPU 架构,完成全链路调优,充分释放国产硬件的算力潜能。
- 国产数据库专属适配:适配达梦、人大金仓、南大通用、OceanBase 等主流国产数据库,针对数据库特性实现性能优化,迁移后性能得到保障。
- 信创生态全兼容:适配国产操作系统、中间件、数据库,满足信创等保要求,同时保障业务高性能运行。
性能实测:鲲鹏平台 + 达梦数据库,性能业内领先
测试环境
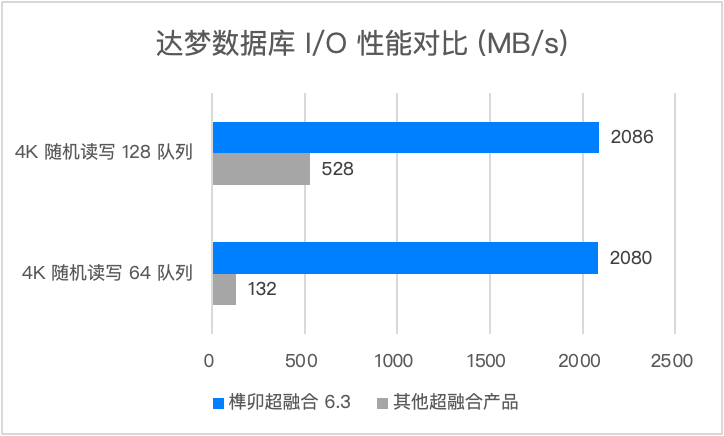
达梦数据库 I/O 性能对比(基于达梦官方提供的测试工具)
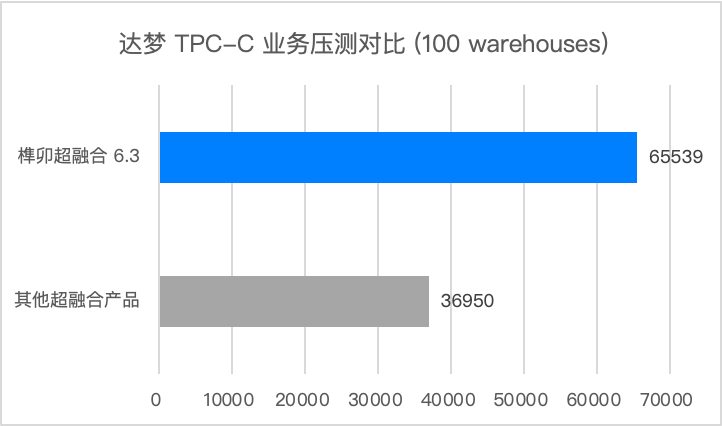
达梦 TPC-C 业务压测对比
总结
榫卯超融合 6.3 通过全栈性能革新,从硬件架构、系统内核、网络优化、存储扩展等不同维度,构建起一套完整的高性能支撑体系。通过对 x86、海光、鲲鹏多平台架构的深度适配,实现了跨平台一致高性能体验,打消信创迁移的性能顾虑;依托 IO_uring 异步 IO、DSA 硬件加速、多链路互联、存储多实例核心技术,从底层突破性能瓶颈,让算力、带宽、并发能力得到最大化释放。
面向数据库等关键业务场景,榫卯超融合 6.3 实现了高并发、低延迟的性能表现,既能支撑数据库高强度交易负载,也能满足金融级微秒级低延迟要求,在信创场景中实现性能业内领先,帮助企业实现真正的降本增效。
推荐阅读:
SmartX vs. VMware:分布式存储关键能力与性能对比
国产数据库性能评测与调优合集:基于 SmartX 超融合信创平台与分布式存储产品
性能翻倍!SmartX 超融合与 vSAN 8 在数据库场景下的性能对比
SMTX ZBS+OceanBase 性能测试,揭秘国产分布式存储+分布式数据库真实表现!