跳转到您所在的国家或地区
我们建议您访问当前所在地的网站,了解针对您所在的国家或地区提供的产品与服务。
我们根据 IP 地址判断大致位置。若您正通过代理服务器访问,则位置可能与实际不同。隐私政策
留在 HK & Macao (English) 站点
Built-in support for mainstream models including text generation, embedding, and reranking—covering a wide range of enterprise use cases.
Easily pull open-source models from Hugging Face or upload custom and proprietary models to meet specific business needs.
Use model catalogs to predefine inference engines, resource specs, and runtime configs—standardizing deployment and reducing DevOps overhead.

Unify and schedule GPUs from vendors like NVIDIA and AMD across physical servers, virtual machines, and Kubernetes clusters.
Enable multiple model instances to share a single GPU using intelligent partitioning and isolation—boosting utilization and overall throughput.
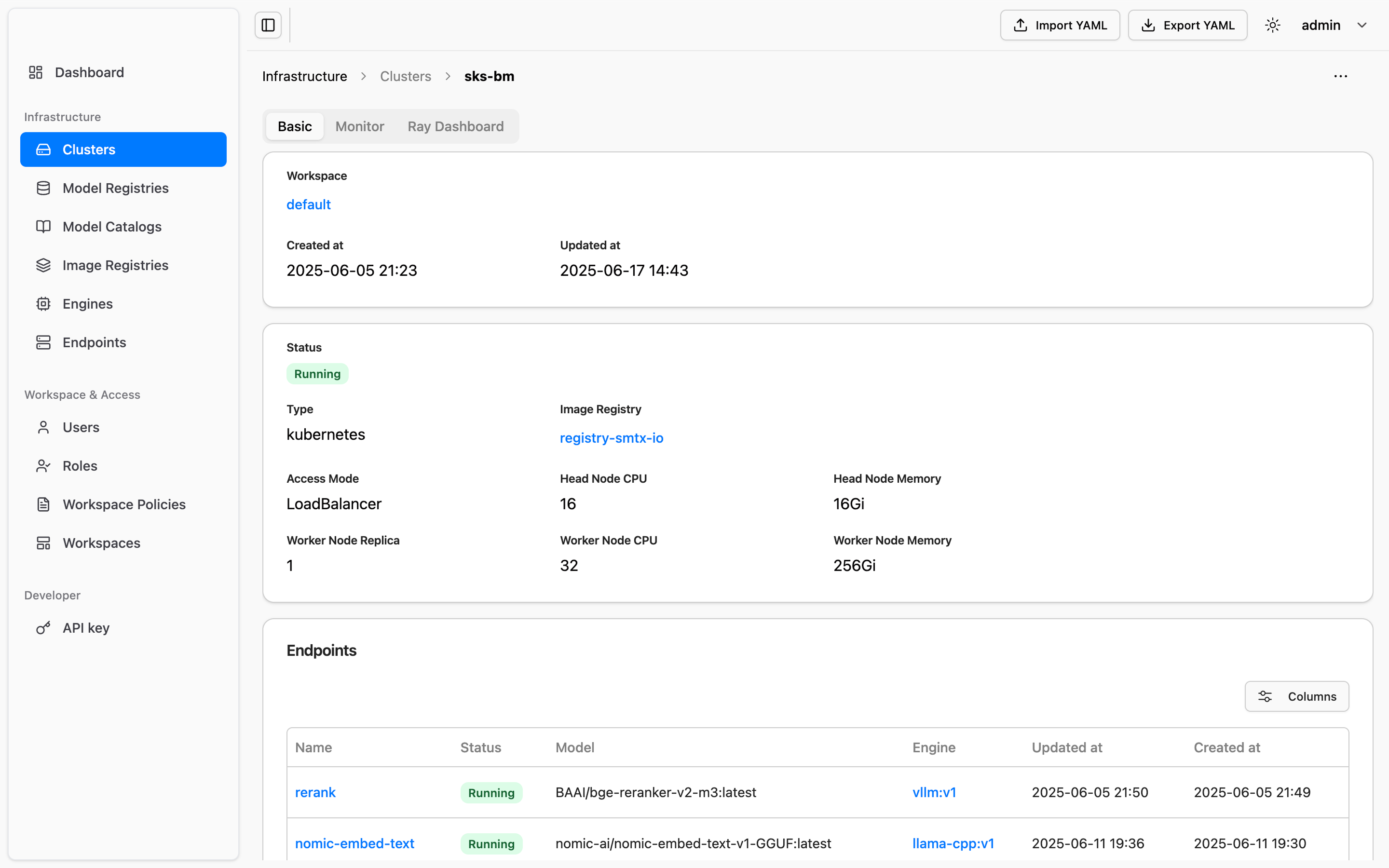
Leverage KVCache-aware load balancing to optimize request routing and hit rates—enhancing inference performance and responsiveness under high concurrency.
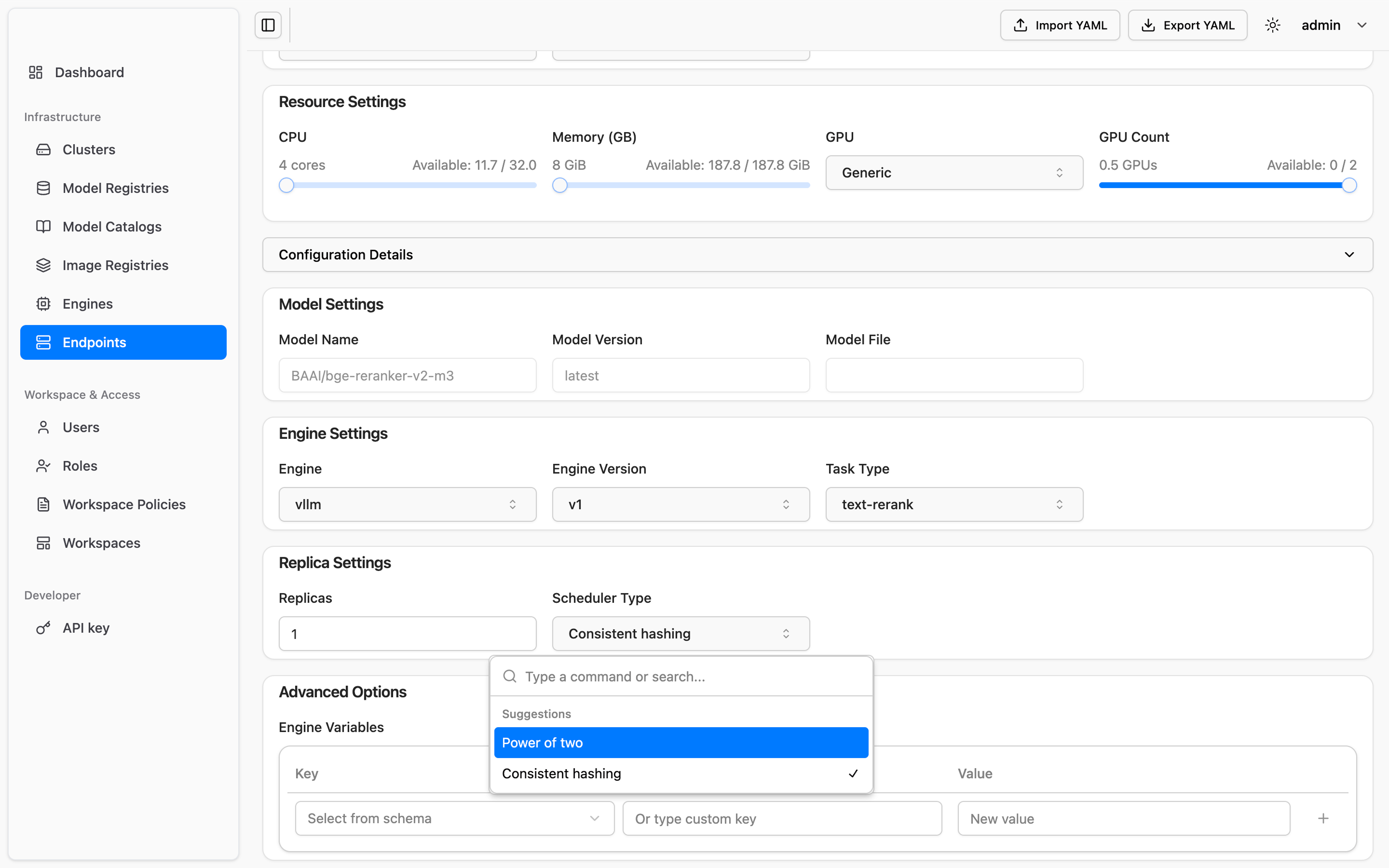
Each tenant has isolated resource and model spaces—ensuring data security and operational independence.
Role-based access control across model management, inference, and scheduling—enabling streamlined governance.
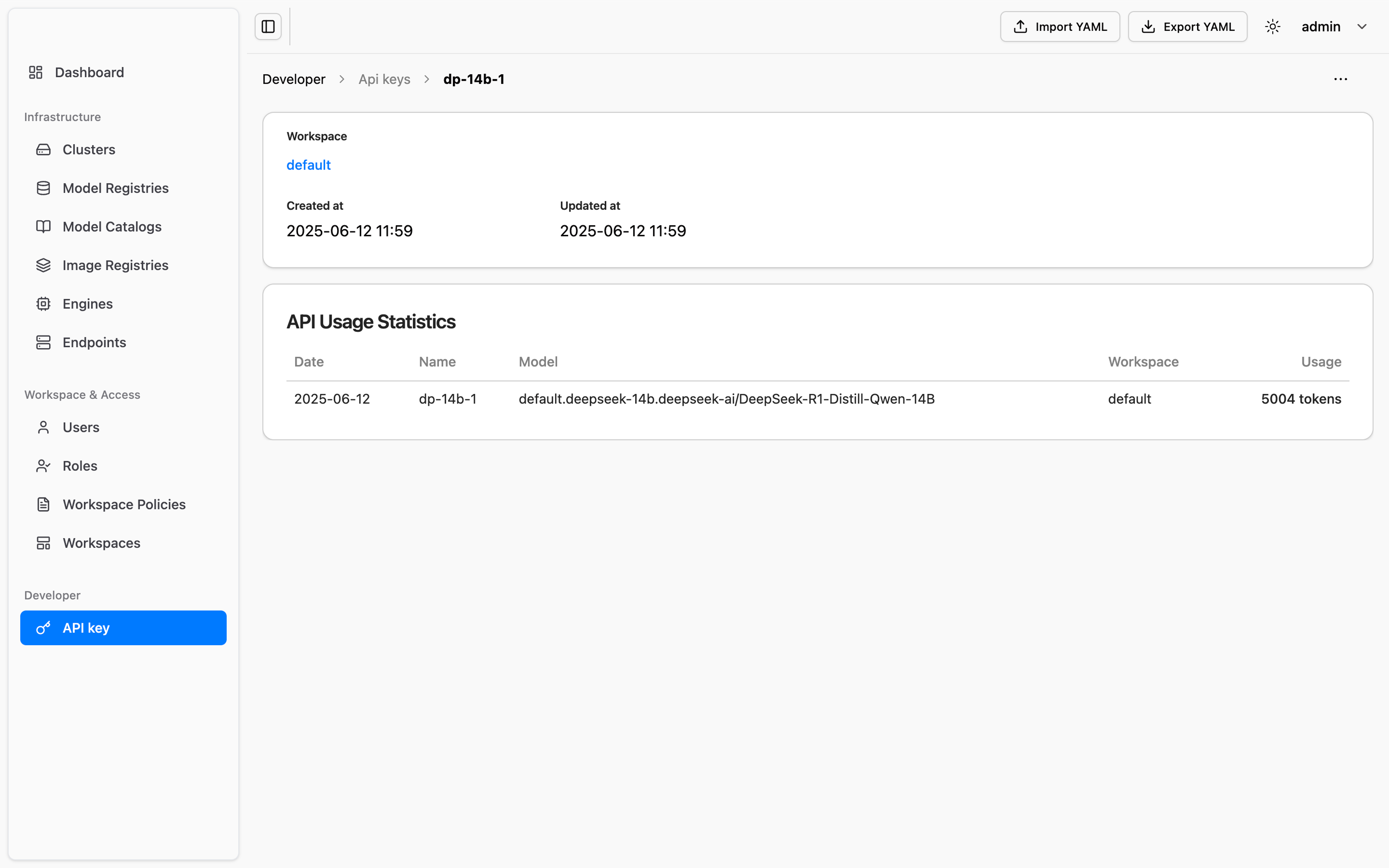
Configure and monitor token-based access for external calls—enabling rate limiting, cost control, and billing readiness.