作者:深耕行业的 SmartX 金融团队
背景
ZBS 是由 Z Block Storage 缩写而来,Z 代表 The Last Word,有最后/最终之意。ZBS 是 SmartX 自主设计、研发并且成功商业化的一款分布式块存储产品。一直以来,ZBS 作为 SmartX 超融合软件(SMTX OS)的重要组成部分,为上层虚拟化提供高性能、高可用和高可靠的数据持久化存储支撑。
在日常与金融客户交流过程中,客户对 ZBS 架构原理都表现出了不同程度的兴趣和疑惑,这也是本文编写的初衷,希望通过这样的一篇文章,可以给读者一个全面的视角来了解 ZBS。
缘起
SmartX 公司创立之初(2013 年),定位是为企业云构建易用、可靠、按需扩展的数据中心基础架构。在分布式存储(公司第一款产品 HCI 存储底座)早期技术路线选择上,其实也调研过开源类产品,例如 Sheepdog 和 Ceph 等。使用开源产品的好处是启动快(产品可以快速商业化),如同盖房子,站在 10 楼向上盖速度很快,但随着房子越来越高,问题会越来越多:整体结构和地基是否可以适应不断变化的需求;是否可以灵活按需优化迭代;对于像 Ceph 类代码量偏重且复杂的开源产品,遇到核心问题,是否可以及时解决;以及开源产品的 License 等等。综合评估下,SmartX 决定走自主研发的技术路线,从图纸设计到基建再到交付房子,这条路虽慢,但符合初创团队的产品基因:做难做的事,做有价值的事。
做完第一个选择后,马上就要思考第二个问题:分布式存储的架构应该如何选择?在当时,可供选择和参考的架构大致有两类:
- DHT – Distributed Hash Table(Ceph 即典型的 DHT 代表)
- 集中管理元数据(以 GFS – Google File System 为代表)
基于算法去实现大规模数据集的分布式管理,看似是完美的、智能的,但在面对企业常态化的集群横向扩容和硬件故障所带来的拓扑变化,会影响到算法,进而导致数据位置的变化,产生不必要的数据流动,同时也会失去对副本位置的控制权,对存储性能的优化也会变得复杂。这并不是 SmartX 希望看到的样子。
GFS 在 Google 内部已经有大规模使用(2003 年论文发表时,最大集群节点已超千台),其后来者 HDFS 在大数据场景中的成功应用,可以证明 GFS 的框架设计理念是可靠的,是具有高度容错的分布式存储系统框架。以下对 GFS 简要介绍:
- 运行在普通 PC 服务器,可按需水平扩展,并处理超大规模数据集。
- 存储大文件(GB 级)场景,I/O 特点是文件一次写、多次读,修改操作以追加为主。
- 对顺序写和顺序读模型比较友好,随机读写时架构设计并不能保证性能。
- 采用和应用程序 API 协同设计的方法(简化接入实现)。
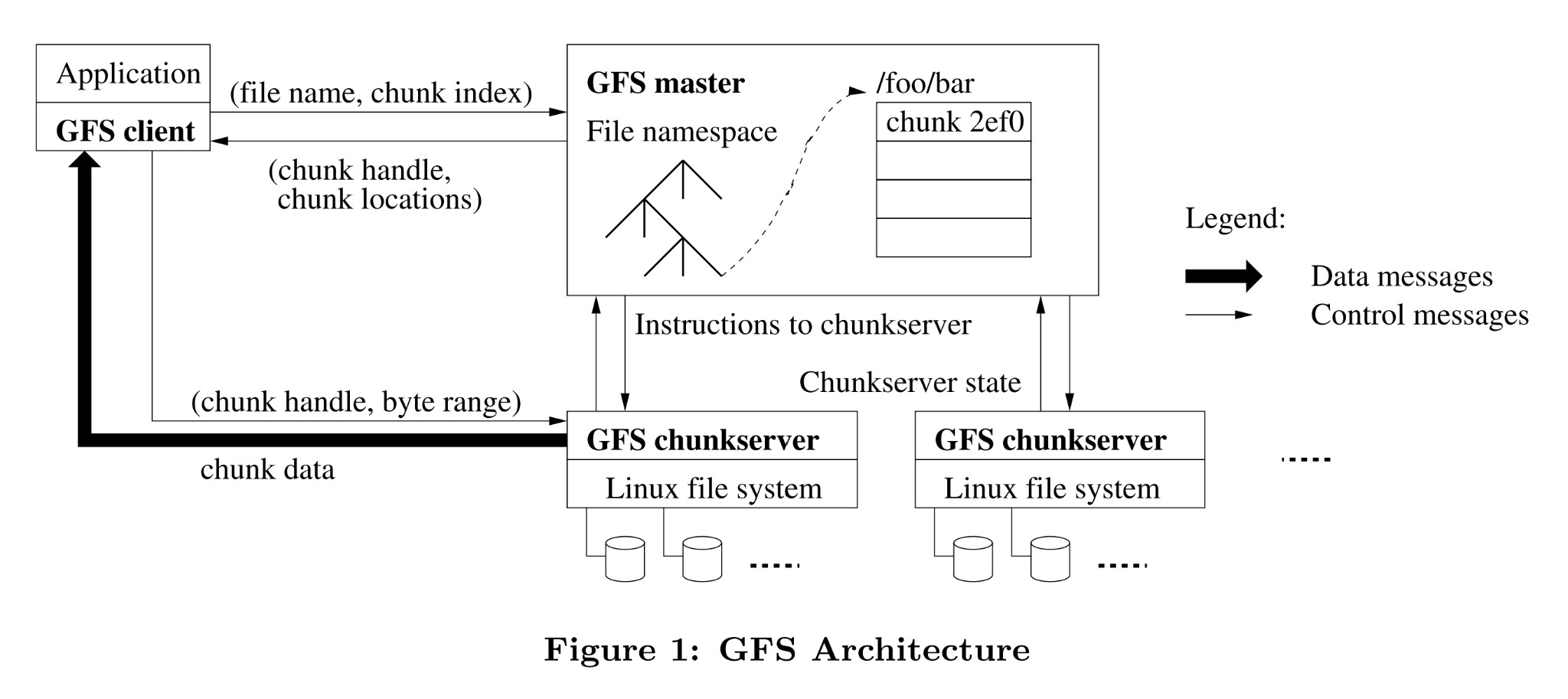
图 1 – GFS 架构 1
图 1 来自 GFS 论文中的架构设计,可以看出,GFS 采用 Single Master 的设计思想(容错是需要独立设计实现),架构由一个 Master 加多个 ChunkServer 组成,文件被切分成多个 Chunk 块,采用副本技术实现数据可靠性。架构将控制信息与数据分离,减少 Master 工作负载,并通过控制 Chunk Size(64 MB),从而减少通信开销以及元数据的容量开销。如果读者想更加深入了解 GFS,可以阅读文末第一篇参考文章。
可以看出,通过合理设计,Master 集中管理元数据,并不会成为瓶颈。结合 SmartX 自身的需求,即精细化管控数据,来实现极致的性能优化和灵活的数据运维能力,我们最终确定参考和借鉴 GFS 的设计理念(技术路线),去实现一款自主研发、适应于私有云/虚拟化的企业级分布式存储产品。
确定了技术路线,下面我们通过不同的维度来一起看看,ZBS 的架构是如何设计的,在哪些地方与 GFS 相似,哪些地方不同,SmartX 又是如何思考的。
对产品设想
虽然参考 GFS 的框架,但应用场景不同(GFS 是面向大数据,对数据一致性的要求是宽松的,而 ZBS 的定位是面向云计算/虚拟化,要求强一致性)、目标不同(GFS 带宽优先,而 ZBS 对存储的 IOPS/BW/Latency 都非常看重),所以对产品细节的考虑及实现方式需要有自己的方法论。以下是我们对产品的一些主要定位:
- 相比使用专有黑盒硬件,需运行在标准的 PC 服务器,使用标准通用硬件。
- 可小规模起步(3 节点),按需水平扩展。
- 假设失效是常态,架构需具备良好的容错和自动恢复能力。
- 处理大规模数据集,单集群可处理 PB 级数据。
- 存储软件需要将硬件的性能充分发挥出来(硬件升级换代或扩容)。
- 灵活的存储协议接入方式和扩展能力。
存储架构
构建一个企业级分布式存储系统对于任何一个团队来讲,都是一件极具挑战性的工作。不仅需要大量的理论基础,还需要有良好的工程能力支撑。
从广泛意义上讲,分布式存储中通常需要解决三个问题,分别是元数据服务、数据存储引擎以及一致性协议。图 2 为 ZBS 系统架构,其组件将逐一展开介绍。
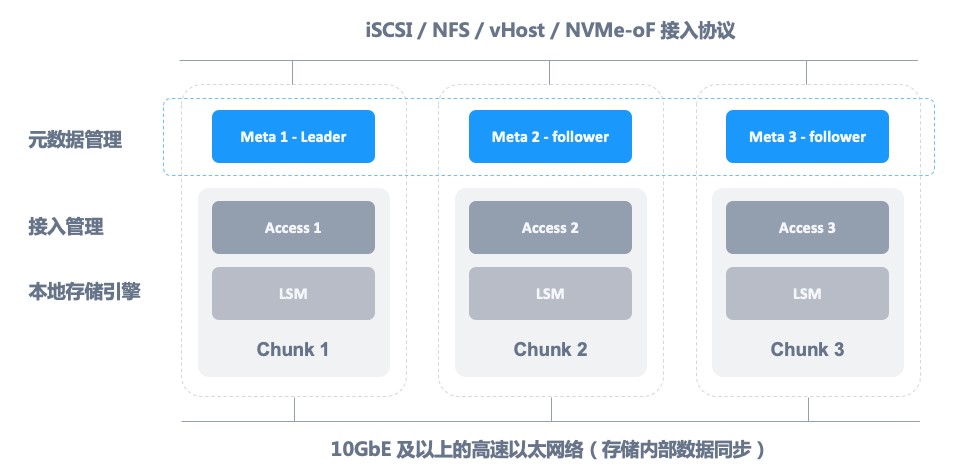
图 2 – ZBS 系统架构
Meta 是整个分布式集群的大脑,其功能包括:集群成员管理、存储对象管理、数据寻址、副本分配、访问权限、数据一致性、负载均衡、心跳、垃圾回收等。
存储引擎 Chunk 负责管理数据在每一个独立节点内的存储能力,以及本地磁盘管理、磁盘故障和亚健康处理等。每一个存储引擎之间是独立的,在这些独立的存储引擎之间,需要运行一个一致性协议,来保证对于数据的访问可以满足 ZBS 期望的一致性状态。
接入管理是对外提供存储功能服务的能力,提供可靠的、高性能的接入服务,从图 2 中可以看到,ZBS 提供了丰富的接入协议,来满足不同场景下的接入通道,在后面的系列文章中也会详细介绍各种接入协议的设计实现。
有了以上这些组件,就掌握了一个分布式存储的核心,不同的分布式存储系统之间的区别,基本上也都来自于这些组件的不同选择。
Meta 元数据服务
所谓元数据就是“数据的数据”,如果元数据丢失了,或者元数据服务无法正常工作,那么整个集群的数据都将无法被访问。同时,元数据服务的响应性能,也决定了整个存储集群的性能表现,所以 ZBS 的设计聚焦在以下三个能力:
- 可靠性 – 在单 Master 架构中,元数据必须保存多份,同时元数据服务需要提供容错和快速切换的能力,采用分布式数据库来持久化和同步元数据的方案,明显会给整个架构增加复杂性。最终 ZBS 选择采用单机 KV DB 来实现 Meta 本地元数据持久化,利用 Log Replication 机制实现元数据在多节点间的数据同步,当 Meta Lead 失效,Follower 节点通过选主快速接管元数据服务。
- 高性能 – 最小化元数据服务在存储 I/O 路径中的参与度。ZBS 将控制平面与数据平台进行分离,使大部分 I/O 请求不需要访问元数据服务,当需要修改元数据时,比如数据分配,元数据操作的响应时间必须足够快。ZBS 定义数据块 Extent 为 256 MiB,在 2 PiB 集群存储容量规模下,元数据能全部加载到内存中操作,提高查询效率。
- 轻量级 – 为了让架构简单,ZBS 并没有拆分成管理节点和数据节点(与 GFS 不同之处),而是通过合理的资源优化,将元数据服务与数据服务混合部署在同一个节点,三节点即可部署交付,而无需独立部署管理节点。
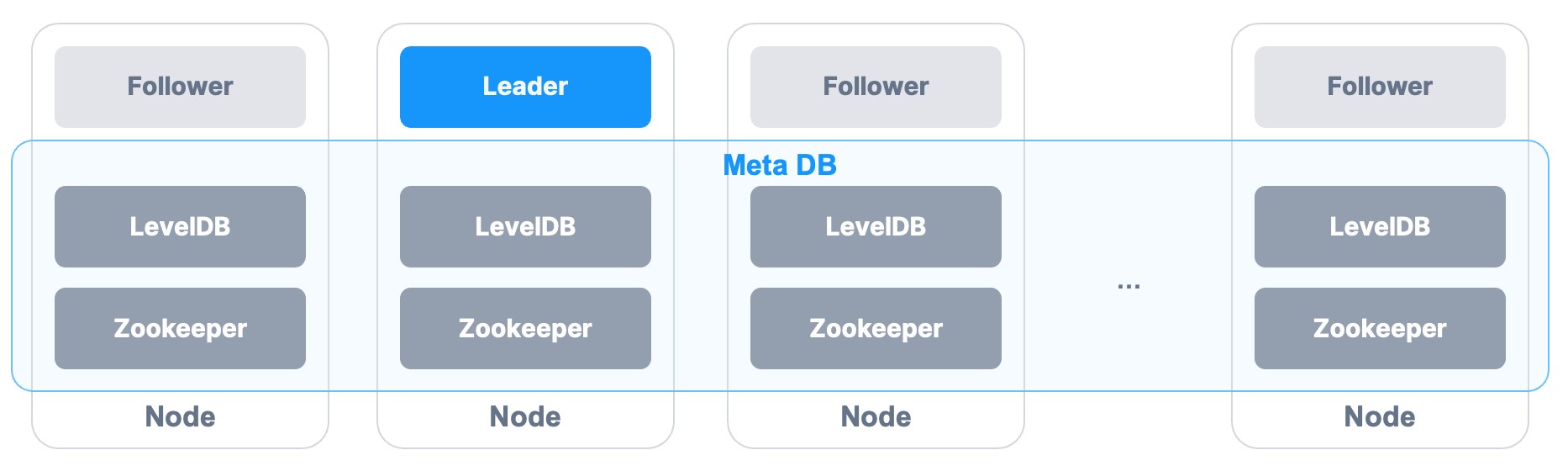
图 3 – Meta 元数据
存储引擎
与元数据服务相似,存储引擎的设计,同样需要关注可靠性、一致性、性能以及易于运维等几个方面的能力。
- 可靠性 – 数据的可靠和一致性是最核心的能力,没有任何妥协的空间。ZBS 采用副本的数据保护技术,通过副本(Extent)版本号实现数据一致性的检查,数据副本数低于预期时,将自动触发数据重构。对于脏数据,由 Meta 定期完成 GC(垃圾回收)。
- 性能 – ZBS 设计提供两种存储形态「全闪和混闪」来适应不同场景下的性能需求。随着新型硬件的速度越来越快(NVME、DCPMM、25 GbE……),性能的瓶颈会从硬件转移到软件,尤其对于存储引擎,性能至关重要。ZBS 在软件层面追求极致优化(程序锁、上下文切换等),来提高效率。
- 裸设备管理 – ZBS 并没有使用现成的文件系统作为存储引擎,而是结合自身对性能的需求,在裸设备上实现数据分配、空间管理、I/O 等逻辑。这样做的好处是可以避免文件系统带来的性能 Overhead 以及 Journal 写放大。
- 运维 – 易于使用、易于升级,可以让客户日常运维更加简便;易于排错、发现问题,可以使工程师快速定位并修复。使用 Kernel Space,优势是性能更好,但同时也存在很多严重的问题,如 Debug 和升级麻烦,Kernel 模块故障域变大,很可能污染 Kernel。最终,ZBS 采用 User Space 实现存储引擎(软件升级方便,进程问题并不会影响 Kernel)。

图 4 – 存储引擎
数据路径
通过图 5 可以了解到 ZBS 接入数据完整 I/O 过程。
- Client 发起 I/O 请求,不同的接入协议(iSCSI、NFS、vhost、NVMe-oF)会使用不同的交互方式,这里并不展开,Access 接收 I/O 请求。
- 超融合架构计算与存储融合,在节点状态正常下,I/O 请求发送给本地 Access。
- 存算分离架构,I/O 接入的 Access,在首次连接由 Meta 进行分配。
- Access 向 Meta 请求授权,通过 Lease 实现对 Extent(数据块)操作权限,同时缓存 Extent 的位置信息。
- Access 向多个 Extent 所在位置发起强一致性的 I/O 操作。
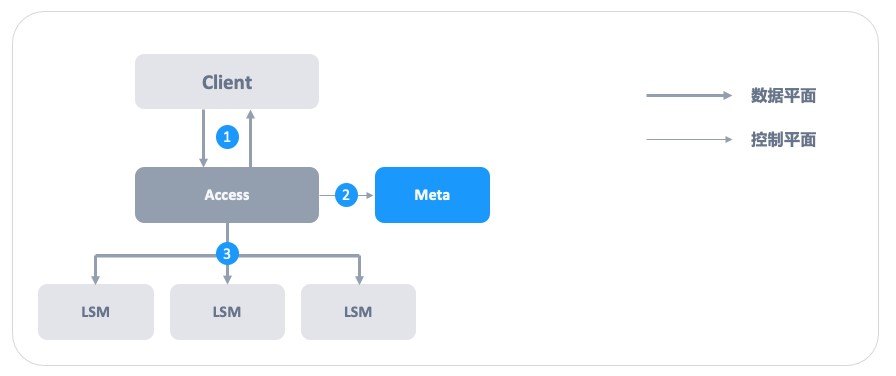
图 5 – Access 接入
对比 ZBS 和 GFS
相信读者对 ZBS 的设计思想已经有了一定的了解,虽然 ZBS 设计参考 GFS 实现,但应用场景决定了最终实现的区别。我们通过下面的表格展示两种存储在架构设计实现上的相同与不同。
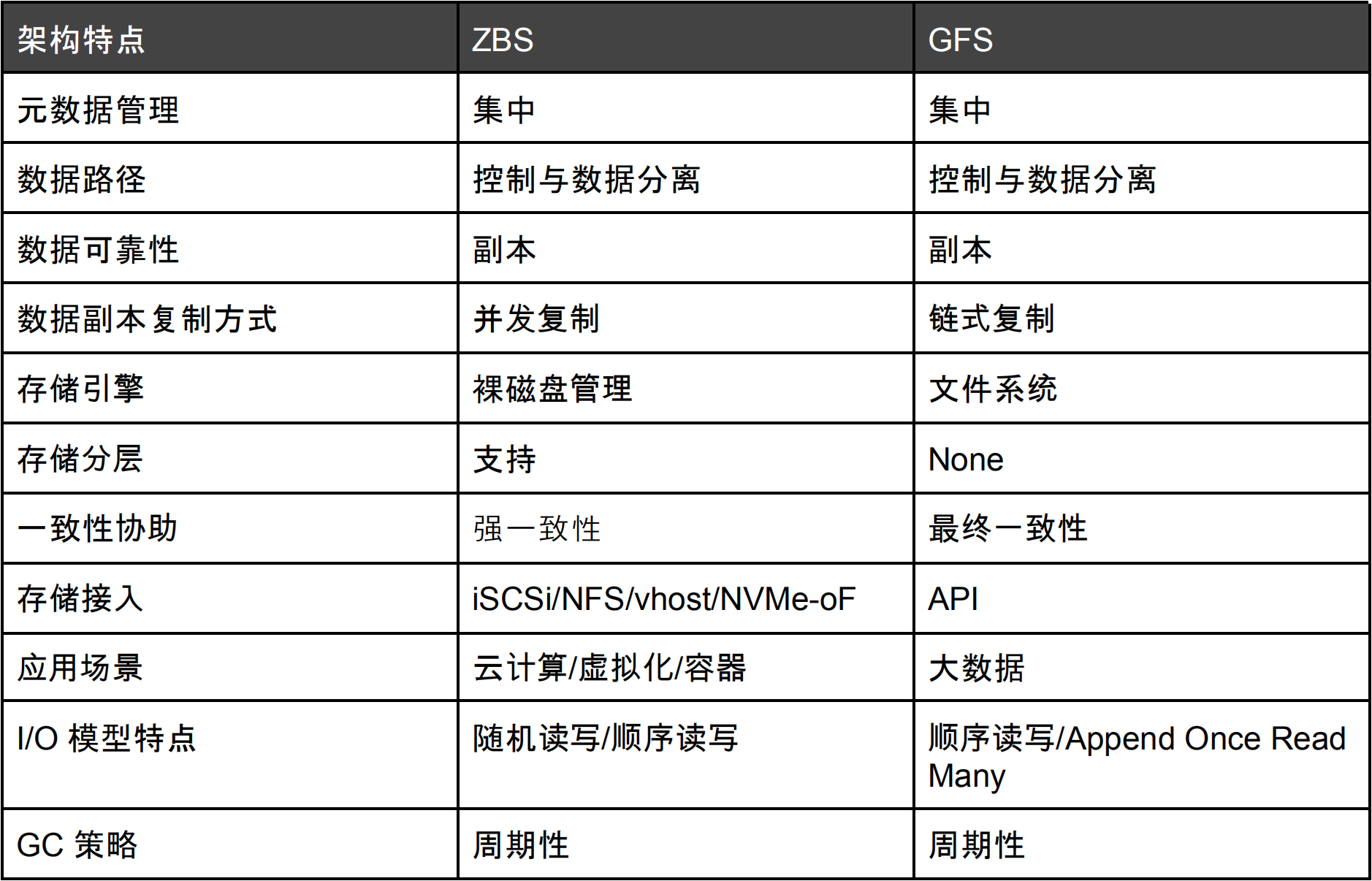
表 1 – ZBS 与 GFS 架构对比
性能表现
经过多年的产品迭代优化,图 6 展示了最新版本下,ZBS 在不同存储介质类型、网络环境以及叠加不同软件功能条件下,发挥的存储性能表现(基于 3 节点 HCI 集群)。

图 6 – ZBS 存储性能
展望
ZBS 通过大量的客户部署案例,积累了丰富的经验,同时随着近些年新技术的不断涌现,SmartX 将结合自身的理解,在后续软件迭代中持续优化 ZBS,充分发挥新型存储介质的性能,例如存储引擎 I/O 利用用户态驱动 Bypass Kernel、Meta 分布式来支持更多新的特性。
参考文章:
- The Google File System. https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/gfs-sosp2003.pdf
- SmartX 分布式块存储 – 元数据篇
https://zhuanlan.zhihu.com/p/36138609 - SmartX 分布式块存储 – 存储引擎篇
https://zhuanlan.zhihu.com/p/44250377 - Boost 模式:SPDK vHost-user 实现 KVM Virtio 存储加速
https://mp.weixin.qq.com/s/NQpXZ59gIrHqPmkPVpHw8g - RDMA:基于 RoCE v2 加速存储数据同步
https://zhuanlan.zhihu.com/p/257228128