得益于 DeepSeek 在技术开源、推理能力和成本方面的优势,众多企业已经开始加速验证 DeepSeek 在不同业务场景下的应用。尤其针对数据敏感的场景,企业需要 DeepSeek 私有化部署方案,在保证信息安全的同时获得满意的推理质量。但相比利用各种 DeepSeek 公有服务和 AI 应用平台,规划私有部署方案也为用户带来诸多疑问:
- 目前希望快速搭建一个稳定的验证环境,帮助业务团队尽快启动验证,为后期的落地和投入提供参考。如何在尽量减少投入的情况下,快速规划部署方案并完成验证环境的搭建,同时保证验证的可靠性? DeepSeek 提供多种模型和参数,企业内部的实际业务真的需要“满血”大模型吗?如果使用多个参数和精度适中的模型,可以使用同一套基础设施满足不同业务需求吗?
- DeepSeek 提供多种模型和参数,企业内部的实际业务真的需要“满血”大模型吗?如果使用多个参数和精度适中的模型,可以使用同一套基础设施满足不同业务需求吗?
- 动辄百万的 DeepSeek 一体机是否有必要投入?如果业务部门之间有数据权限的划分,是不是无法共用一个大模型?如何避免 DeepSeek 一体机单点故障带来的业务影响?
带着以上问题,SmartX 针对 DeepSeek 的私有化部署进行了方案设计和验证,并推出了 DeepSeek 场景解决方案——基于 SmartX AI 基础设施,用户可选择在超融合环境或 Kubernetes 裸金属环境部署并使用多种 DeepSeek 模型,仅需新购带 GPU 的节点,即可快速构建灵活、高性能的 DeepSeek 基础设施,加速推进业务团队的场景验证进程。
以下,我们将介绍基于 SmartX AI 基础设施的 DeepSeek 部署方案,解答企业 DeepSeek 私有化部署的相关疑惑,提供硬件配置建议,并分享“SmartX AI 基础设施 + DeepSeek”支持企业 AI 营销助手的实践经验与性能评测。
基于 SmartX AI 基础设施的 DeepSeek 解决方案
方案概览
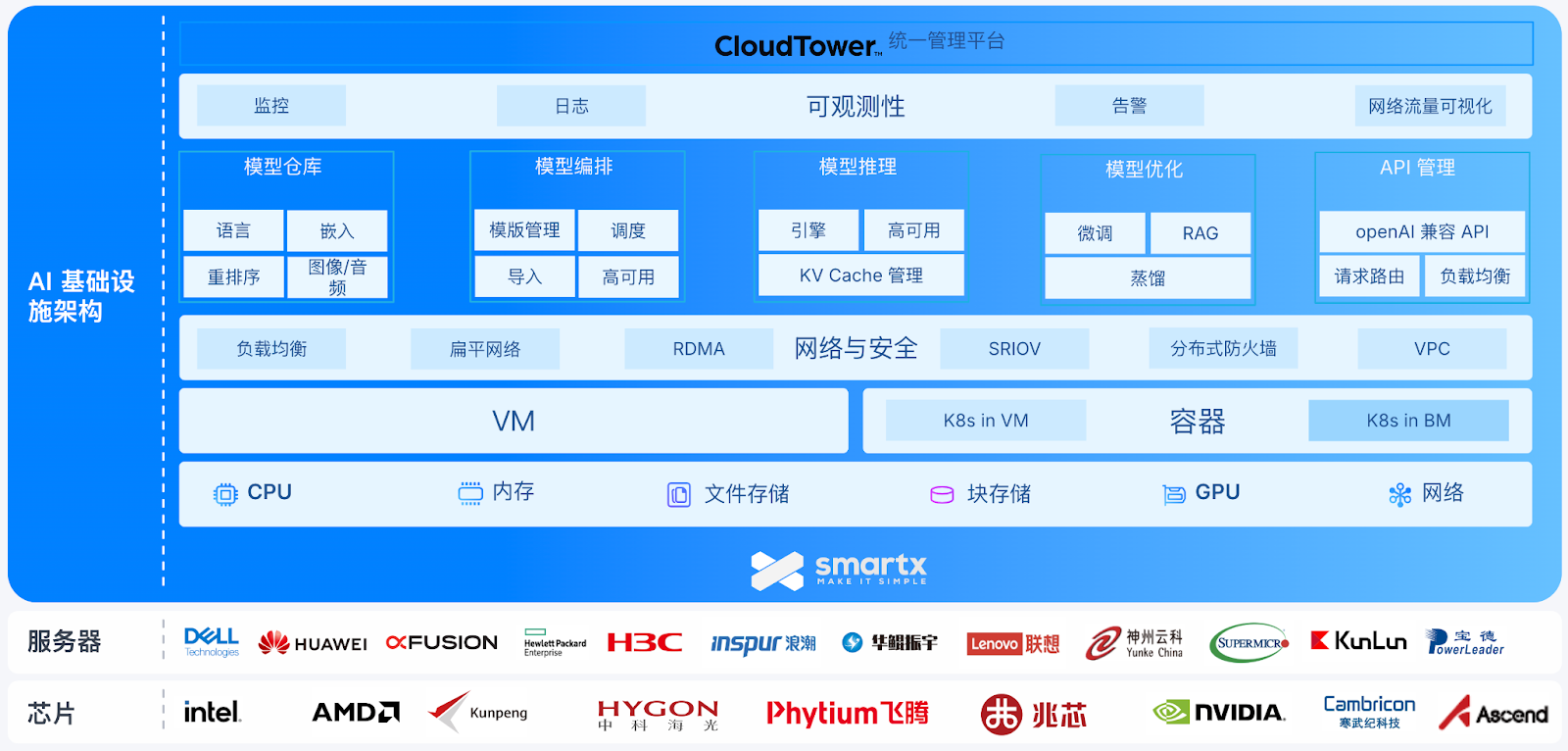
基于 AI 基础设施解决方案,SmartX 用户可在超融合(采用原生虚拟化 ELF)和 SMTX Kubernetes 服务(SKS)裸金属环境中实现 DeepSeek V3/R1(Distill-Qwen-7B 至 671B)模型的本地部署,并为 DeepSeek 应用提供计算、存储、网络、集群管理、容器管理等全栈基础设施支持,以一套技术栈同时为大模型和企业其他业务系统运行提供统一的基础设施资源,降低企业成本投入和部署运维难度。
方案特点
- 广泛的硬件兼容性:全面适配 Intel 和多种信创 CPU 以及 NVIDIA、寒武纪、昇腾 GPU,支持国产主流 x86 与 ARM 架构服务器,为用户提供灵活的硬件选择。
- 全栈的软件能力:一套技术栈提供完整的 DeepSeek 基础设施资源。
- 算力融合:支持 NVIDIA GPU 直通和 vGPU 以及寒武纪、昇腾 GPU 直通功能,提供可灵活调度 CPU 与 GPU 资源的综合计算平台。
- 存储融合:基于自主研发的分布式存储,为 AI 应用的数据处理和分析提供高性能、高可靠的存储服务。例如,SMTX 文件存储为模型仓库、推理引擎、向量数据库提供文件存储服务,ZBS 为 AI 应用如 Dify 组件(Redis/PG)提供高性能、高可靠的块存储服务。
- 工作负载融合:基于 SKS 实现虚拟化和容器工作负载的统一支持与管理,支持基于虚拟机和裸金属的 Kubernetes 部署方式,满足 AI 应用在性能与资源方面的多种需求。SmartX 软件定义的网络与安全软件 Everoute 可实现虚拟化与容器应用网络互联互通,并提供分布式防火墙、负载均衡和 VPC 功能,进一步提升网络安全与资源隔离。
- 模型融合:提供 AI 训练推理平台(预计 Q2 上线),支持主流模型的私有化构建、部署,实现全生命周期管理:
- 模型托管:涵盖大语言模型(通用 & 推理)、Embedding、Rerank 等。
- 模型编排:兼容主流推理引擎,如 vLLM、SGLang、Llama.cpp 等。
- 模型优化:支持微调(Fine-tuning)和 RAG(检索增强生成)。
- API 管理:提供统一的 API 访问与管理能力。
- 统一的管理平台:支持在 CloudTower 统一管理多个站点上的虚拟化、容器运行环境及其所需的计算和存储资源,降低运维管理负担。
- 快速部署:SKS 内置 NVIDIA GPU Operator,可自动部署 CUDA 驱动、Container Toolkit 并配置容器运行时,大幅提升部署效率,省去繁琐的手动操作。
不同的硬件配置
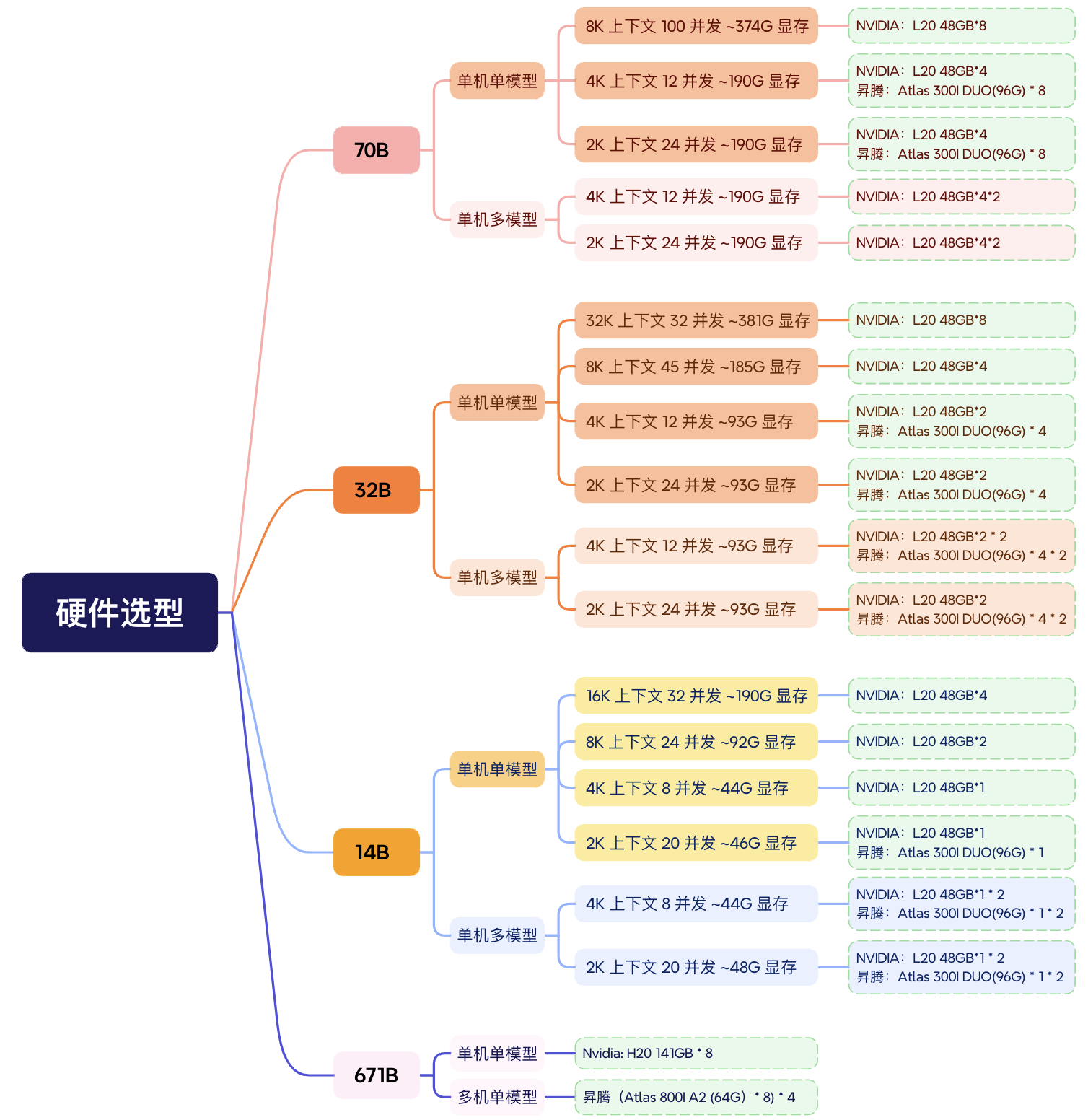
在 GPU 的选择上,用户可根据模型参数量、场景、上下文大小、并发数等参数来选择相应的 GPU 资源,具体可以参考下图:
部署方案一:基于超融合(虚拟化)环境
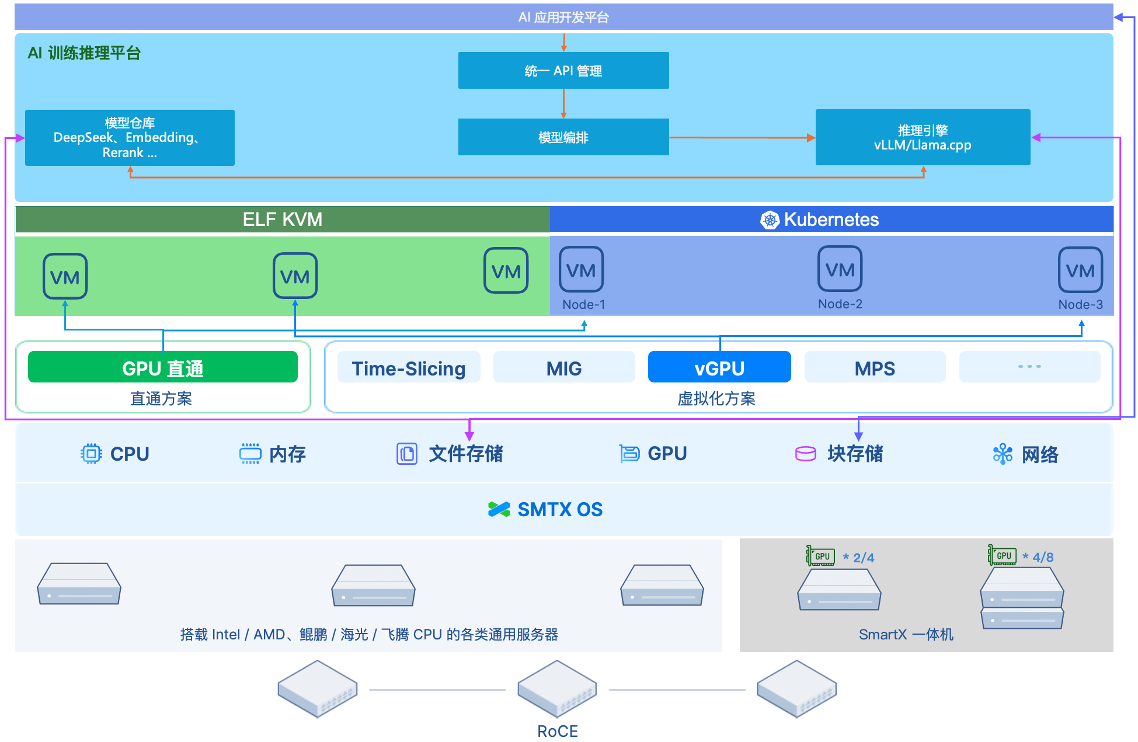
该方案中,用户仅需在已有超融合集群中增加一台主机用于模型部署,SmartX 超融合可为虚拟机和容器 AI 负载提供统一的资源和管理支持,并通过 GPU 共享方案支持多个独立模型的部署,满足不同场景的使用需求。
方案优势
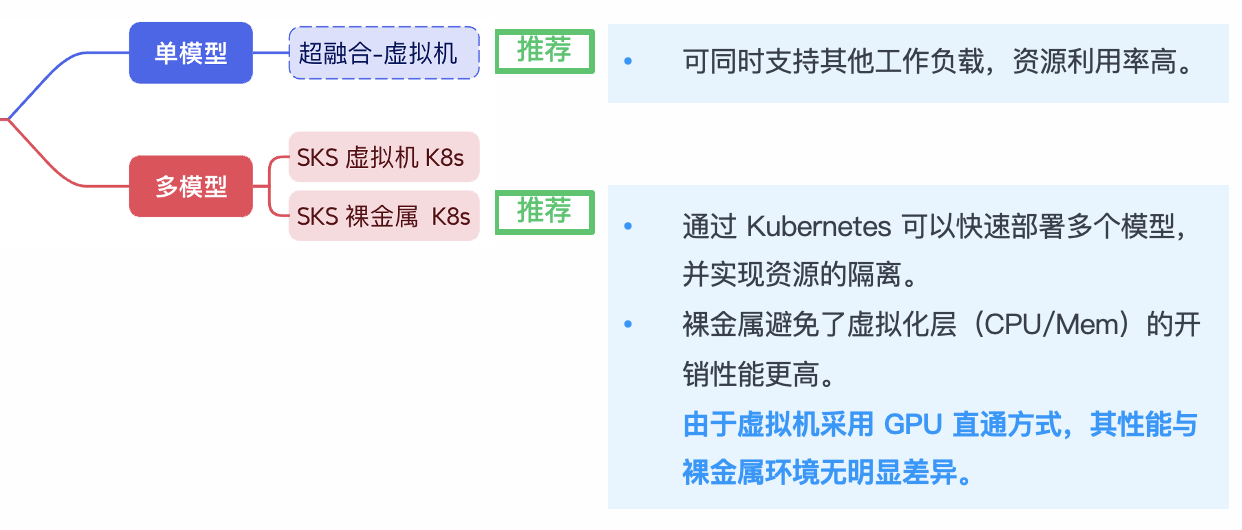
- 架构灵活:支持基于虚拟机和容器两种部署模式,支持部署多种模型,并可按需扩容。
- 可靠可用:具备多种企业级高可用特性,分布式架构避免单点故障风险,支持部署两个以上同等规模的模型,实现模型高可用。
- 资源分配均衡:ELF 虚拟化的 DRS 功能可动态调度虚拟机和容器节点,使集群资源使用更均衡。
- 拓展场景:基于 SmartX 超融合对 RoCE 和 SR-IOV 的技术支持,用户可探索分布式推理,部署更大规模模型。
部署方案二:基于 SKS 裸金属环境

该方案中,用户可利用 SKS 对虚拟机 Kubernetes 集群和物理机 Kubernetes 集群统一支持的能力,在已有的 SKS 集群中增加一台主机用于模型部署,物理机作为 Kubernetes Worker 节点加入到 SKS 集群中,并与虚拟机 Kubernetes 集群进行统一管理。这种方案可支持更为广泛的 DeepSeek 模型参数,包括 671B。
方案优势
- 双重环境支持:模型编排、仓库和 AI 应用等不依赖 GPU 资源的组件,可以部署在虚拟机中的 Kubernetes Worker 节点上,提升资源利用率。
- 性能强劲:减少了虚拟化层(CPU/Mem)的开销,相比虚拟化 Kubernetes 集群可提升 10%–20% 的性能,满足复杂模型运行场景的高性能需求。
- 硬件要求低:硬盘及网卡配置没有最低数量限制。
- 故障影响范围小:物理机节点仅运行 AI 相关业务,故障场景不会影响其他组件的正常运行。
方案建议
用户可以在根据模型规模进行 GPU 选型后(参考上图),进行软件方案的选型(参考下图):
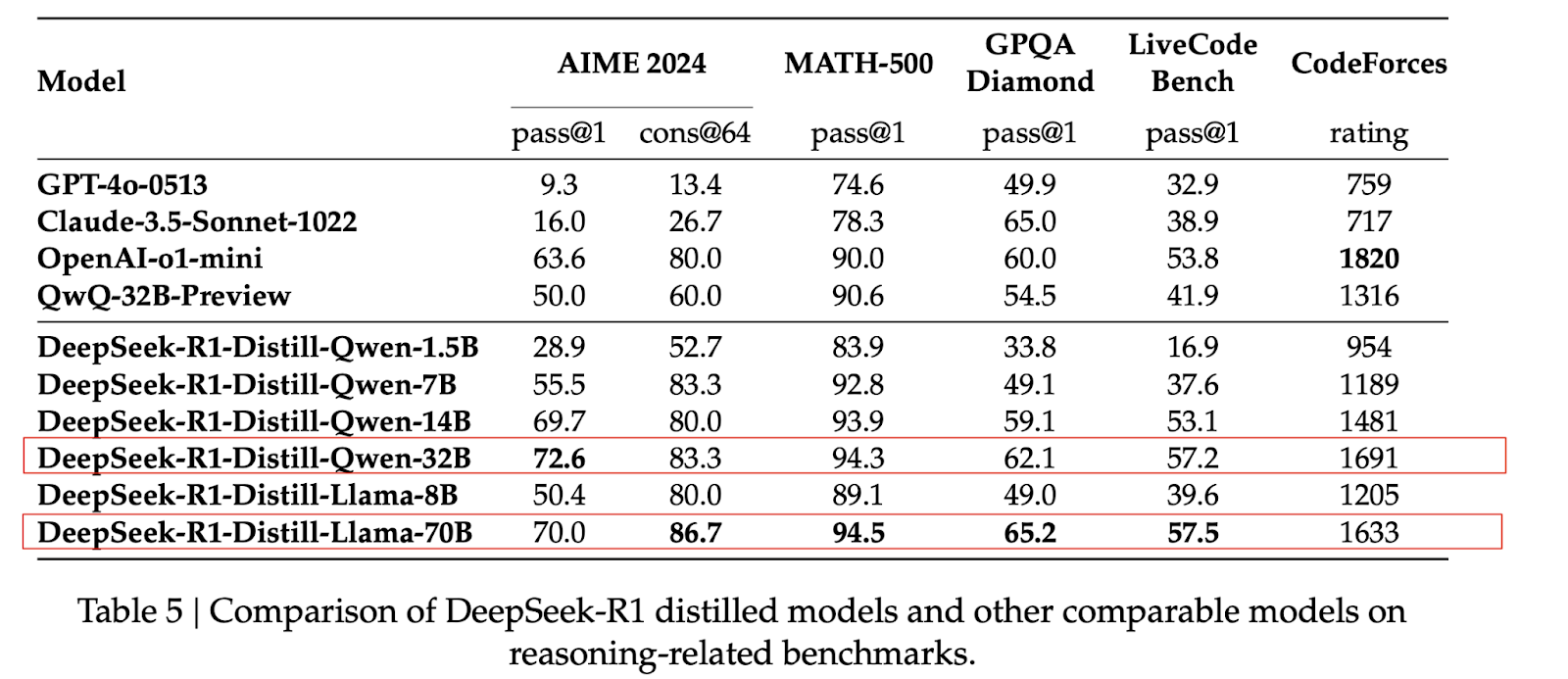
建议用户初期先进行小规模投资,快速搭建环境进行验证。待验证模型推理准确度符合业务要求后,再根据实际需求逐步投入资源,以确保投入的高效性和可行性。另外,不必过度追求部署“满血”R1 671B 的模型——不仅需要较高的投入(且投资回报率不一定高),在很多场景中 70B 甚至 32B 都可以满足需求(32B 在中文处理上甚至要比 70B 的效果好,具体可参考下图)。
场景验证:以 SmartX AI 基础设施支持 AI 营销助手
在企业开展市场营销活动时,通过在线上平台引入 AI 智能体,可以打造全天在线的客服助手,并通过构建企业知识库,提升 AI 客户回复的质量和针对性,为用户提供更有价值的信息,降低市场营销服务成本。我们基于 SmartX AI 基础设施(超融合环境)部署了 DeepSeek-R1-Distill-Qwen-14B 和 32B 模型,并使用开源 AI 应用平台 Dify 构建整套业务工作流,整套架构如下图所示。
方案验证
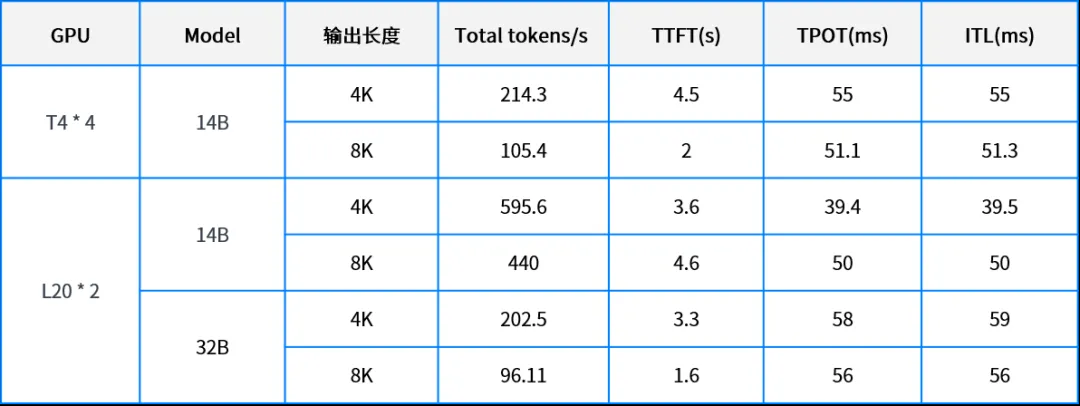
为进一步验证方案效果,我们分别使用 NVIDIA T4 和 L20 GPU 测试了 DeepSeek-R1-Distill-Qwen-14B(BF16)与 DeepSeek-R1-Distill-Qwen-32B(BF16)模型基于 SmartX AI 基础设施的性能表现,并验证了两款模型在 AI 客服场景的回复准确率、token 消耗、回复时间等表现。
测试环境
测试环境部署三节点 SmartX 超融合集群,通过虚拟机运行 DeepSeek 模型,虚拟机配置为 32vcpu、64G 内存。分别配置 4 块 NVIDIA T4 和 2 块 NVIDIA L20 支持 14B 和 32B 模型,以 GPU 直通的方式提供 GPU 资源,使用 vllm 推理引擎运行大模型。
测试结果
性能对比:
测试输入长度为 1K,以下测试结果供用户参考。
场景验证:
基于 SmartX AI 基础设施部署 DeepSeek-R1-Distill-Qwen-14B/32B 模型构建 AI 客服助手,并模拟用户提问场景进行测试,具体表现如下:
- 14B 模型:使用需求拆分的工作流进行优化后,90% 的输出内容符合预期,token 消耗平均值为 2669,平均回复时间为 26.3s。
- 32B 模型:使用需求拆分的工作流进行优化后,95% 的输出内容符合预期,token 消耗平均值为 2611,平均回复时间为 27.1s。
可以看到,32B 模型在输出质量上有所提升,但平均回复时间与 14B 模型持平。整体而言,以 SmartX AI 基础设施部署 Dify 支持 DeepSeek-R1-32B 模型,结合人工优化,可以满足 AI 客服场景的基本使用需求。后续,可通过知识库、工作流等方面的优化,进一步提升回复效率和质量。

与公有云方案对比
此外,我们还基于该场景,与公有云(Coze)环境部署 DeepSeek R1 满血版的性能和服务效果进行了对比测试。其中,私有化部署配置与方案验证中一致。
测试结果
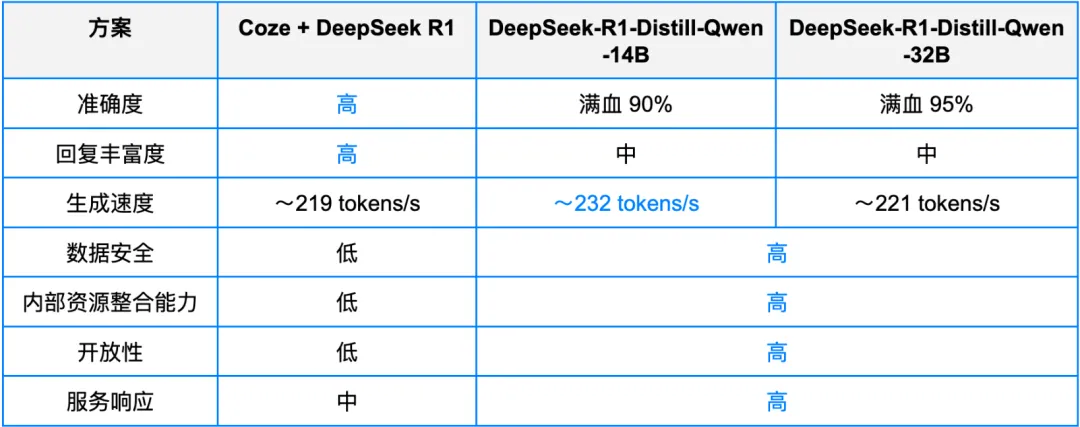
可以看到,私有云部署方案在回复准确度方面可以达到公有云 + DeepSeek 满血模型的 90-95%,生成速度持平(甚至更高),私有化部署方案可以满足用户的基本使用需求。
方案收益
- 提升客服效率:AI 客服提供 7×24 小时在线服务,提升客户满意度并减轻人工客服负担。
- 提高响应效率:AI 从知识库中快速、准确地提供答案,增强服务效率与一致性。
- 优化资源查找:AI 智能分类与索引网站资源,提升用户查找效率和资源利用率。
欲了解更多 SmartX 超融合 GPU 直通与 vGPU 功能特性,欢迎点击下方链接,获取《超融合技术原理与特性解析合集》三册电子书!
推荐阅读: