我们在 DeepSeek 解决方案文章中提到,SmartX AI 基础设施支持虚拟化及容器环境下的两种 GPU 使用方式,即 GPU 直通与 vGPU,为多种大模型应用场景提供灵活、高性能的 GPU 资源。
为帮助用户进一步了解 SmartX 超融合 GPU 直通与 vGPU 功能的性能表现,近期我们基于两款 GPU 卡(NVIDIA T4 和 A30),测试了 SmartX 超融合在虚拟化和容器环境(采用 SMTX Kubernetes 服务)下基于多种 AI 测试工具的具体性能,并与物理机/裸金属环境的性能进行对比。
重要结论:
- 在虚拟化和容器(SKS 和 Docker)环境下,SmartX 超融合采用 GPU 直通与 vGPU 功能,均可为两款 GPU 卡提供良好的性能支持,在多个模型测试中获得接近物理机环境的性能(基本在 90%-110% 范围内浮动)。
- 物理机、超融合虚拟化、SKS、裸金属 Kubernetes 支持 GPU 的性能表现差异不明显,验证了 SmartX 超融合虚拟化和容器环境均可为 GPU 应用场景提供良好的性能支持。
欲了解更多 SmartX 超融合 GPU 支持特性,欢迎点击下方链接,获取《超融合技术原理与特性解析合集》三册电子书!
1 基于 NVIDIA T4 的性能测试
1.1 测试目标
- 测试 SmartX 超融合在虚拟化、容器环境下采用 GPU 直通和 vGPU 功能的性能表现(vGPU 采用不同的切分方式,验证 vGPU 算力的切分是否线性,以及多实例环境下的性能表现)。
- 对比物理机和裸金属环境下,SmartX 超融合在虚拟化、容器环境下 GPU 的等算力池化方案损耗情况。
- 综合 GPU 算力利用率和算力分配的灵活度,讨论基于 SmartX 超融合最佳的 GPU 算力使用方案。
1.2 测试环境
1.2.1 测试硬件
以物理 GPU 所在节点为例:
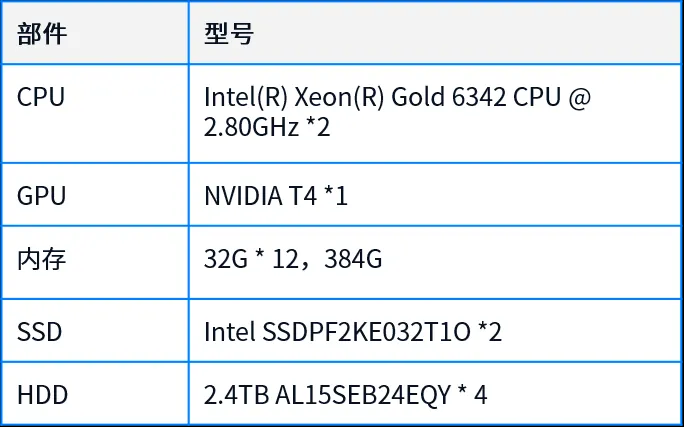
1.2.2 基础平台软件及版本
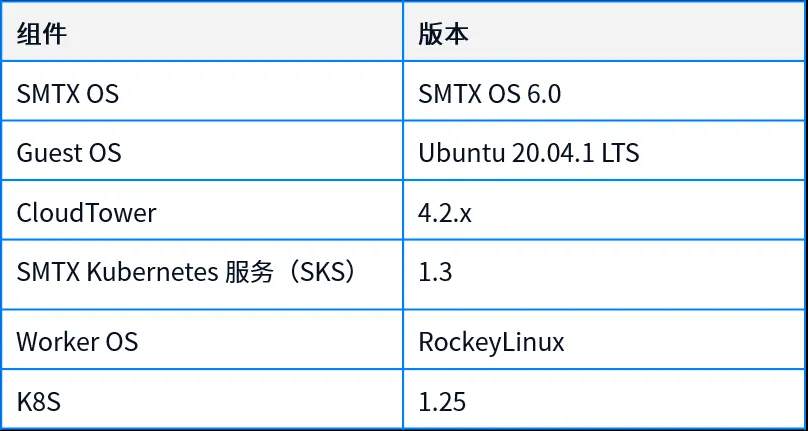
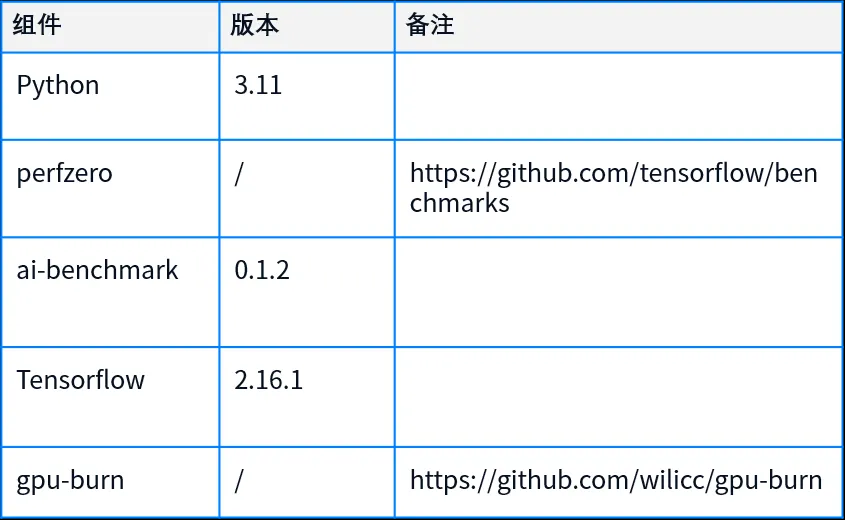
1.2.3 测试工具及版本
(1)TensorFlow Benchmark
TensorFlow Benchmark 是一个开源的基准测试框架,包含了 PerfZero 和 scripts/tf_cnn_benchmarks。本次测试主要采用 PerfZero,PerfZero 是 TensorFlow 基准测试框架中最先进且全面的子项目,提供吞吐量、延迟、内存使用等详细的性能指标,支持自定义测试场景和指标。本次测试主要关注 PerfZero Throughput(吞吐量)的输出结果,包括每秒处理的样本数量(exp_per_second),以及模型在每秒内平均能处理的样本数量(avg_exp_per_second)。这两个指标的单位均为 examples/sec,数据越大性能越好。其中,avg_exp_per_second 是在所有迭代完成后计算得出的平均值,能够反映模型的整体性能表现。而通过观察 exp_per_second 的变化,我们可以进一步分析模型性能在不同阶段的波动情况,从而为性能优化提供有力依据。
(2)AI Benchmark
AI Benchmark 是一个开源 Python 库,用于评估各种硬件平台(包括 CPU、GPU 和 TPU)的 AI 性能。AI Benchmark 的输出结果通常包含总评分(Overall Score)以及各个单项测试的得分。本次测试主要关注 train score(训练得分) 、Inference(推理得分)和 Device AI Score,其中后者是前两项得分的总和,旨在衡量设备在训练和推理两个关键环节上的综合能力。分数越高,设备的 AI 处理能力越强。
(3)GPU Burn
GPU Burn 是测试 GPU 稳定性和性能的压力测试工具,通过长时间让 GPU 运行密集计算任务,来测试显卡在高负载条件下的表现,从而评估显卡的散热能力、性能极限,以及在长时间高负荷下是否会出现问题(如崩溃、过热、降频等)。本次测试主要关注性能(FLOPS)的输出结果,GPU Burn 会输出浮点运算每秒(FLOPS)的值(单位:Gflop/s),表示 GPU 在测试期间执行的计算量,数值越大,代表 GPU 性能越好。
1.3 测试项目及步骤
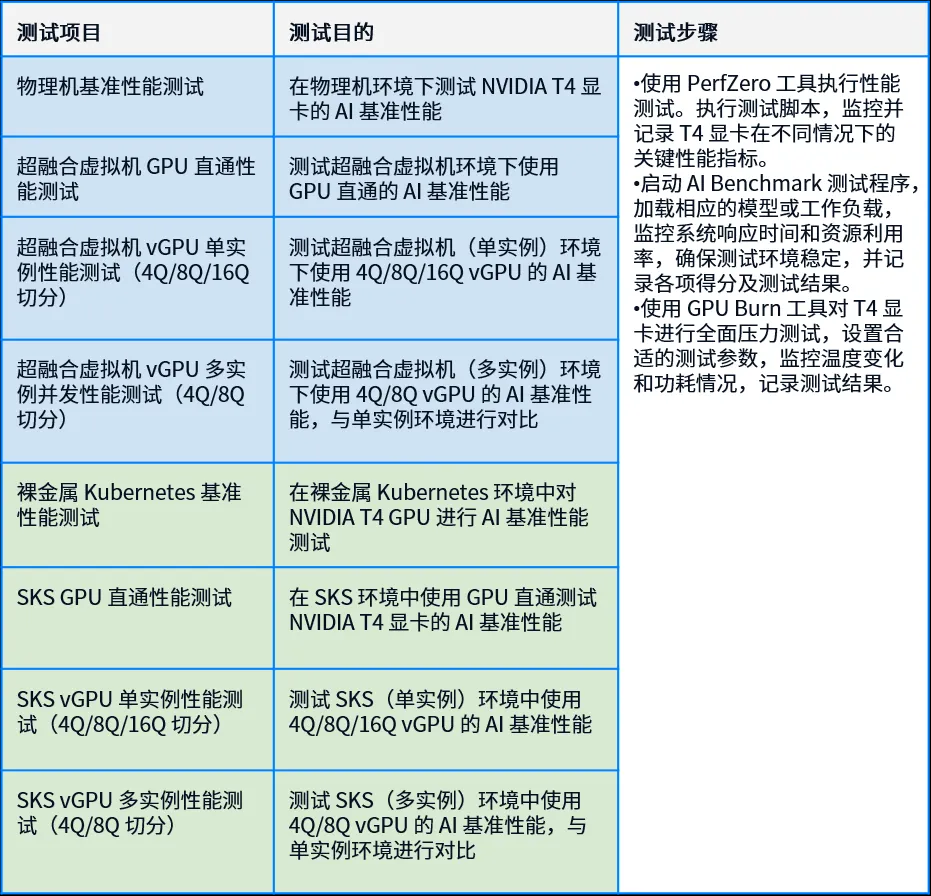
1.4 测试结果
1.4.1 实测性能数据
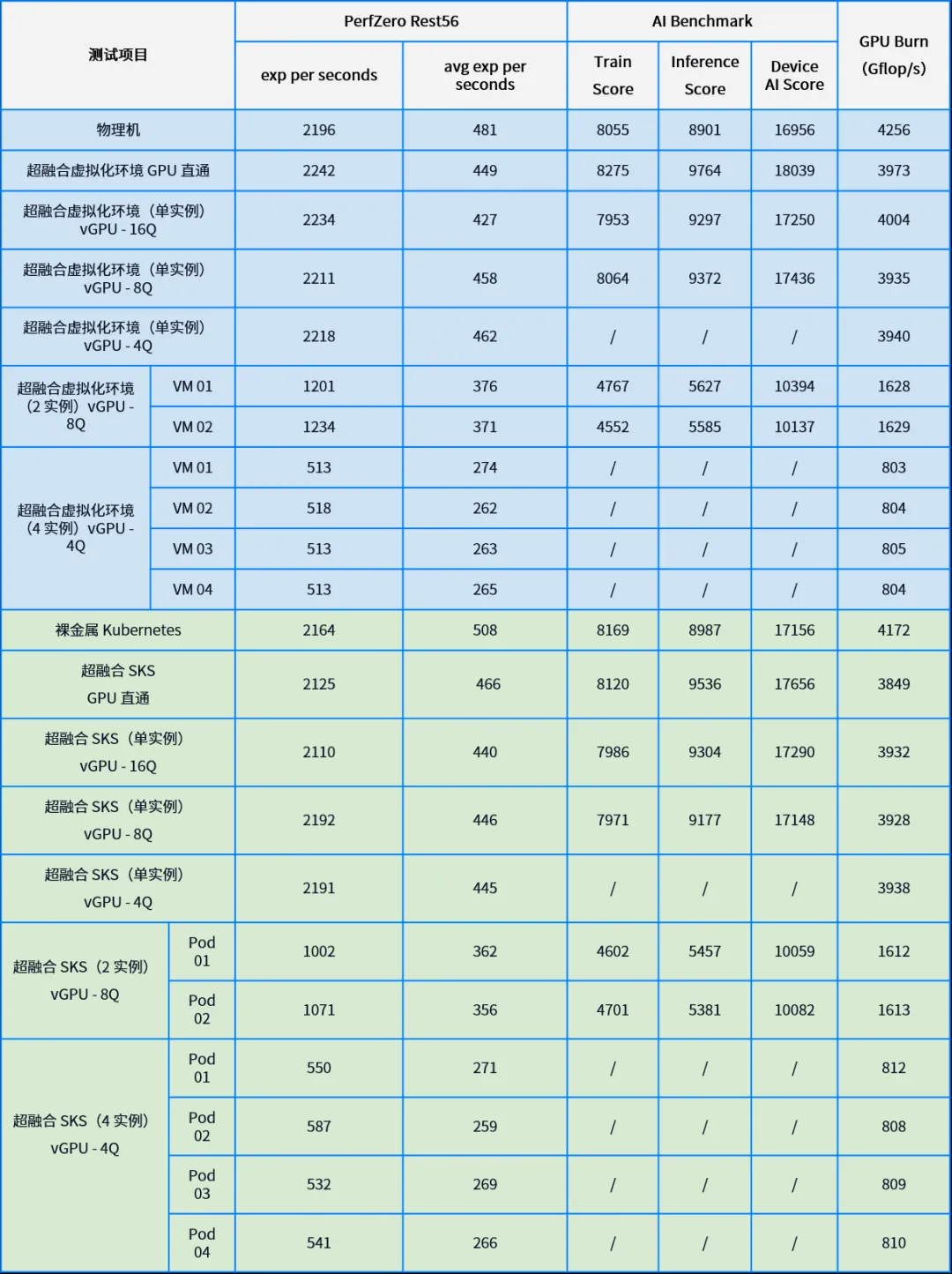
1.4.2 单实例性能折损数据
为了更准确地计算和分析不同超融合环境相对于裸金属环境的性能损耗,将每个单实例测试项下的数值与物理机环境下的数值进行对比,计算每个配置相对于物理机环境的性能百分比,并据此得出性能损耗。
- 对于每个单实例测试项目,使用以下公式来计算性能百分比:性能百分比=(特定配置下的值/物理机环境下的值) * 100%。
- 性能损耗可以通过以下公式计算:性能损耗=100%-性能百分比
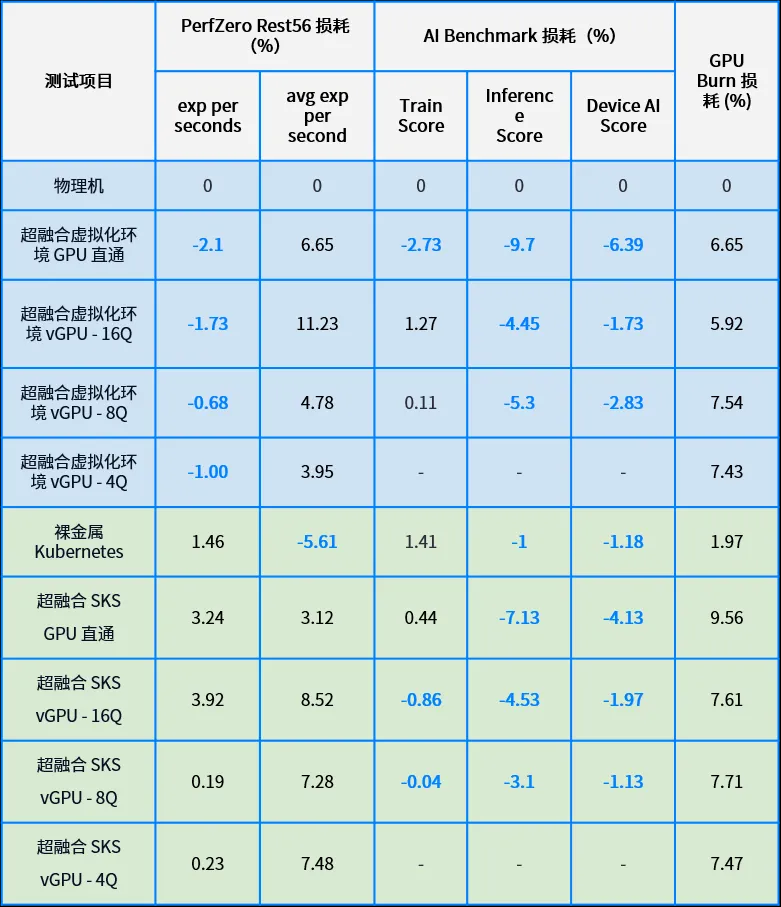
可以看到:
- 超融合 vGPU 能力表现:vGPU 的不同配置(4Q, 8Q, 16Q)在多数测试中能够提供接近裸金属水平的性能,基本在 90% 至 105% 的范围内波动,而不同 vGPU 配置之间的性能差异也较小。无论是在何种配置下,vGPU 都能有效地分配和利用资源,确保用户获得稳定的性能体验。
- 超融合 GPU 直通能力表现:VM GPU 直通功能在多项测试中表现优秀,尤其是在 AI Benchmark 和 PerfZero Rest56 模型测试中,超融合 GPU 直通性能与物理机环境基本持平,甚至有时还能超越。同样地,SKS GPU 直通性能也比较出色,尤其在 AI Benchmark 测试中的表现突出。
- 虚拟化环境 GPU 性能表现:在以上基准测试中,大多数虚拟化环境支持 GPU 所达到的性能与物理机环境性能相当或略优,基本保持在物理机环境性能的 90% 至 110% 之间。在 GPU Burn 的测试中,虽然虚拟化环境的性能普遍略低于物理机环境,但性能损失控制在 10% 以内。
- Kubernetes 环境 GPU 性能表现:在 Kubernetes 环境中,无论是裸金属还是 SKS,GPU 支持能力都得到了充分验证。裸金属 Kubernetes 和 SKS 在大部分测试中表现优异,特别是在 AI Benchmark 测试中达到了最佳性能,而在其他两项测试中则与物理机环境基本持平或略有差距。
- 性能一致性:总体而言,无论是虚拟化环境还是 Kubernetes 环境,SmartX 超融合 GPU 直通和 vGPU 功能在各种测试项目中展现出高度一致的性能表现,几乎所有关键指标均稳定在物理机环境的 90% 至 110% 区间内。
1.4.3 多实例并发测试数据
为了验证多实例并发场景下,vGPU 切分后各实例间资源分配是否均衡,以及多实例的并发性能与单实例性能有何区别,我们还测试了 8Q – 2 实例(2 个虚拟机/SKS 实例各占 8Q 资源)和 4Q – 4 实例(4 个虚拟机/SKS 实例各占 4Q 资源)场景下各实例的性能表现,并与 16Q 单实例场景性能进行对比。
- 实例间性能差异 = (实例 A – 实例 B )/ 实例 B
- 各实例占单实例环境性能比例 = 实例 N / 单实例环境性能(理论上,2 实例测试中各实例性能应为 16Q 单实例环境下性能的 50%,4 实例测试中各实例性能应为 16Q 单实例环境下性能的 25%)
- 并发性能总和/单实例环境性能 = (实例 A + 实例 B + … + 实例 N )/ 单实例环境性能
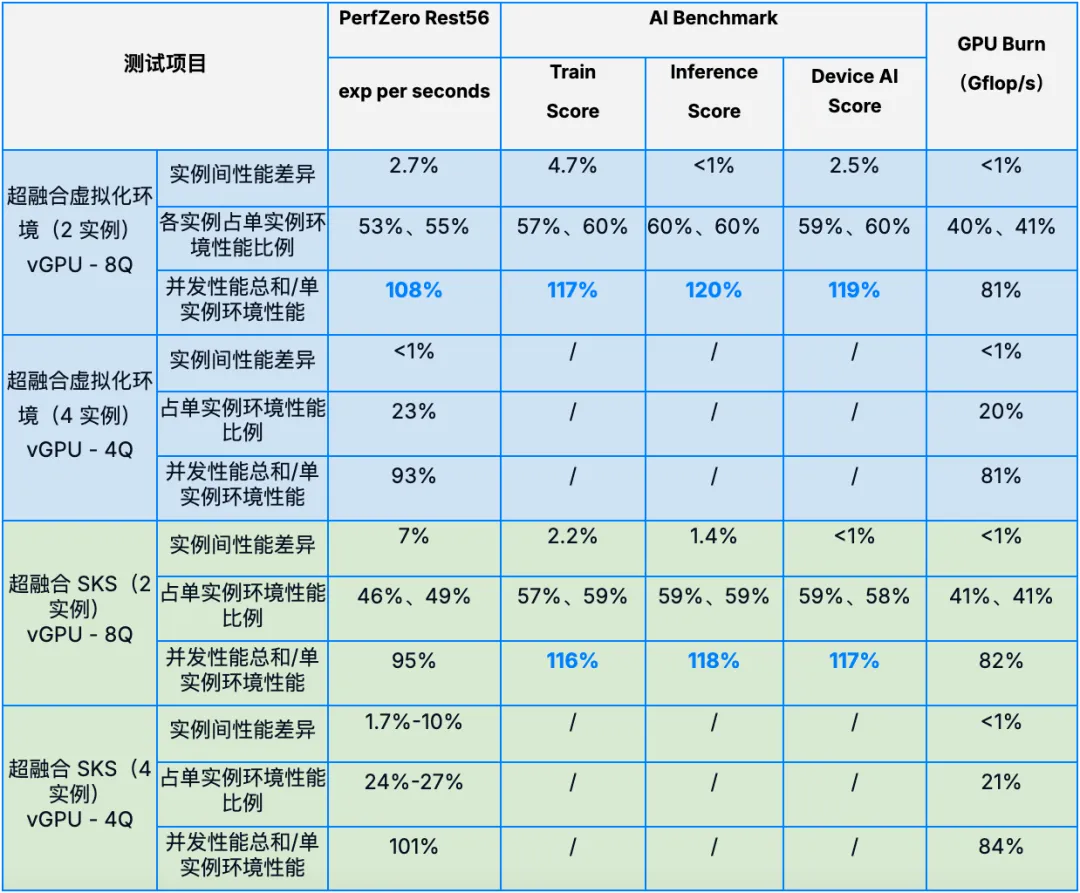
通过以上数据,可以看到:
- 实例间性能差异:在不同环境和不同切分配置下,多实例测试中各实例间性能差异均在 10% 以下,绝大部分集中在 1%-5%,实例间性能差异较小,说明多实例场景下各实例性能表现稳定均衡,资源分配比较平均。
- 多实例测试与单实例测试性能差异:在不同环境和切分配置下,多实例测试中各实例的性能表现与单实例环境的理论性能占比(50% 或 25%)基本吻合,部分测试中甚至超越了理论比例,表明各实例不仅能够有效利用 GPU 资源,而且在某些情况下还能实现更高效的资源利用。在并发性能方面,8Q 配置多实例在 PerfZero 和 AI Benchmark 并发测试中的表现要优于单实例环境;而在进行 GPU Burn 测试时,由于存在算力资源抢占的情况,并发性能之和仅达到单实例环境约 80%,说明不同的 vGPU 配置和不同的任务类型会对多实例性能产生一定影响。总体而言,无论是虚拟化还是容器环境,两种切分配置均表现出较高的 GPU 资源利用率。
1.5 重点测试结论
- 在大多数性能测试中,SmartX 超融合平台对 GPU 的多种使用模式性能表现与物理机环境基本相当,充分展示了 SmartX 原生虚拟化平台 ELF 和容器管理服务 SKS 的成熟度和可靠性。
- 使用 SmartX 超融合 vGPU 功能时,不同 vGPU 配置之间的性能差异较小,意味着各种资源划分方案都能有效地利用分配给它们的计算能力。多实例测试中,各实例间资源分配也比较均衡,在部分测试场景中多实例并发性能高于单实例环境,可提高 GPU 资源利用率。
- SKS(GPU 直通和 vGPU)和裸金属 Kubernetes 支持 GPU 的性能与虚拟化和物理机环境差异不大,验证了 SmartX 超融合虚拟化和容器环境均可为 GPU 应用场景提供良好的性能支持。
2 基于 NVIDIA A30 的性能测试
2.1 测试目标
- 测试 SmartX 超融合虚拟化(采用 GPU 直通)搭配 Docker 支持 NVIDIA A30 GPU 卡的性能表现。
- 对比裸金属环境下(物理机+Docker),超融合虚拟化+Docker 支持 GPU 的等算力池化方案损耗情况。
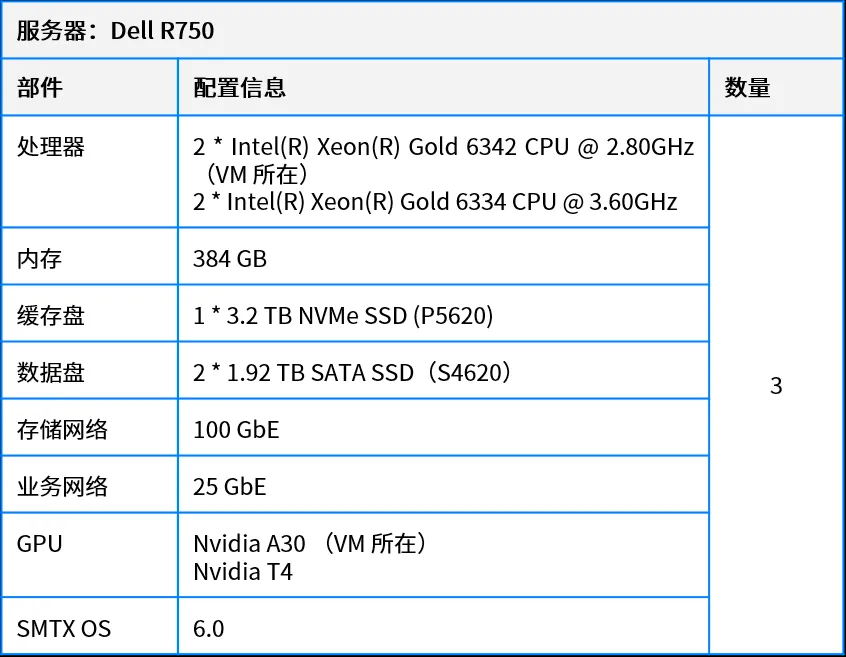
2.2 测试环境
2.2.1 物理机环境配置

2.2.2 虚拟化环境配置
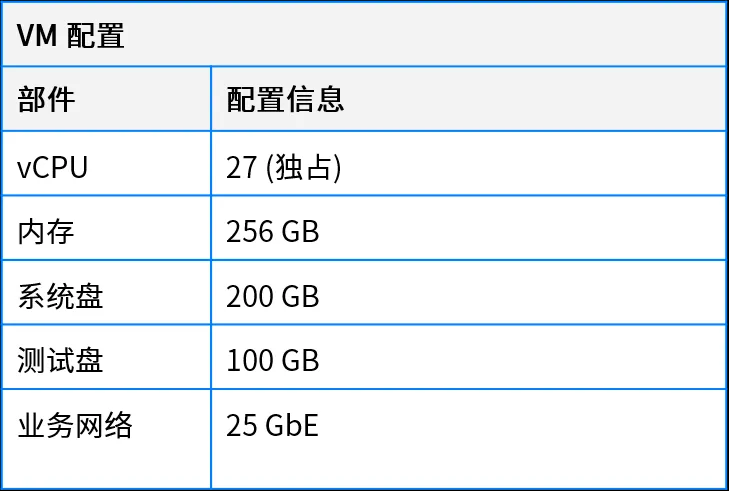
2.2.3 软件环境配置
- Guest OS: Centos 7.9
- Docker-CE: 26.1.4
- Nvidia Driver: 535.183.06
- Nvidia CUDA: 12.5
- PyTorch: 24.07
2.2.4 测试工具和模型
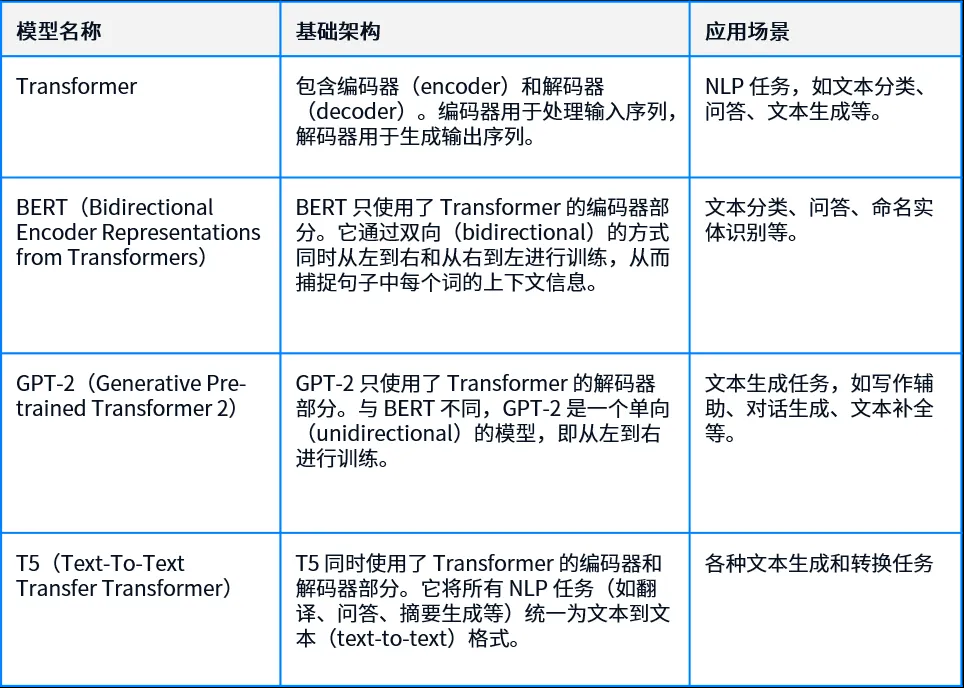
使用 transformers-benchmarks 测试物理机/超融合+Docker 支持 GPU 卡的基准性能及不同模型下的性能表现。Transformer 是一种用于自然语言处理(NLP)的深度学习模型,通过自注意力机制(self-attention)来处理序列数据。本次测试用到的 AI 模型包括 BERT、GTP-2 和 T5,与 Transformer 关系如下:
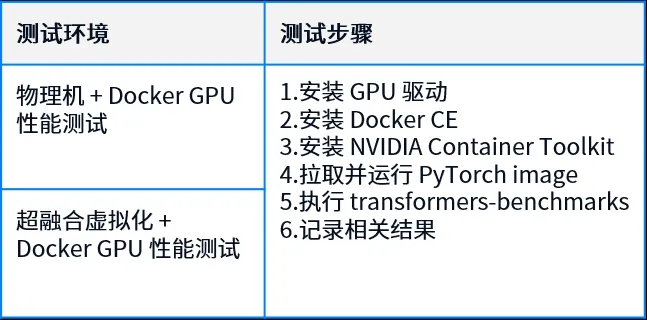
2.3 测试项目及步骤
通过给定不同的参数,测试不同环境最佳的 AI 计算性能,包括以下几个方面:
- 计算性能:测试 GPU 在 PyTorch 下的最大计算性能,统计单位为 TFLOPS(Tera Floating Point Operations Per Second),表示每秒能够执行的万亿次浮点运算,数值越大,代表性能越好。本次分别测试 16 位和 32 位浮点数下的性能。
- 显存性能:测试 GPU 在 PyTorch 下的最大显存性能,统计单位为浮点数的传输带宽(GB/s),数值越大,代表性能越好。
- BERT 模型测试:训练 BERT(Large)模型并测试不同参数下的性能表现,统计单位为 TFLOPS。
- GTP-2 模型测试:训练 GTP-2(Medium)模型并测试不同参数下的性能表现,统计单位为 TFLOPS。
- T5 模型测试:训练 T5(Large)模型并测试不同参数下的性能表现,分别统计编码(Encoder)和解码(Decoder)的性能,统计单位为 TFLOPS。 注:BERT、GTP-2、T5 为单个 Layer 的性能测试,既自注意力机制和前馈神经网络,通过前向传播和反向传播的性能测量,可以了解模型在不同序列长度和批量大小下的计算效率。
2.4 测试结果
计算公式:性能折损 =(物理机环境性能 – 超融合虚拟化环境性能)/ 超融合虚拟化环境性能
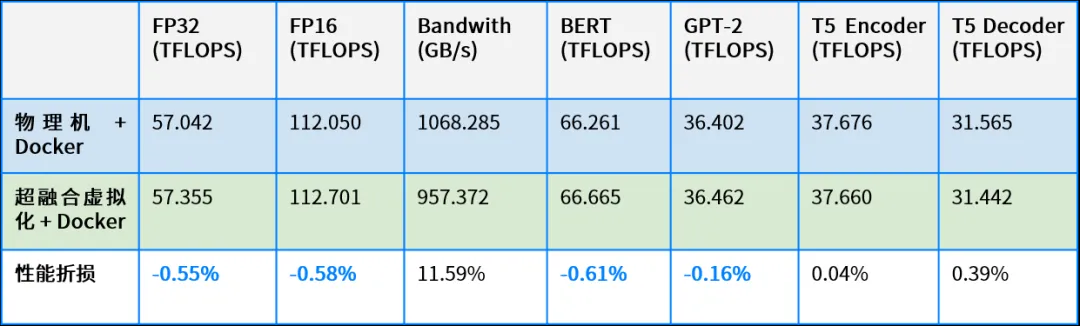
可以看到,SmartX 超融合虚拟化 + Docker 环境支持 GPU 的性能表现,在计算性能、BERT、GPT-2、T5 模型测试中与物理机 + Docker 环境表现基本持平,在显存性能测试中与物理机 + Docker 环境差距在 10% 左右。
2.5 重点测试结论
在基于多种模型的测试中,SmartX 超融合虚拟化 + Docker 环境支持 GPU 的性能表现与物理机 + Docker 环境性能差异不明显,验证了 SmartX 超融合虚拟化 GPU 直通功能的可靠性能。
总结
通过测试可以看到,在虚拟化和容器(SKS 和 Docker)环境下,SmartX 超融合采用 GPU 直通与 vGPU 功能均可良好支持多款 GPU 卡,并在多个场景中获得接近物理机和裸金属 Kubernetes 的性能,为企业用户多种 AI 应用场景提供高性能、一致性的 IT 基础架构支持。
欲了解更多 SmartX 超融合 GPU 支持特性, 欢迎点击下方链接,获取《超融合技术原理与特性解析合集》三册电子书!
推荐阅读: