企业在私有化环境部署 AI 大模型时,经常会对 AI 技术带来的新概念产生疑惑:
- “AI 基础设施”都包含哪些组件?除了 GPU,AI 大模型还需要哪些基础设施能力?
- 什么是“推理引擎”?和“AI 学习框架”是一个东西吗?
- ModelOps/MLOps/LLMOps有什么区别?
- MaaS 是什么?AI Agent 又是什么?
为了帮助企业快速落地 AI 大模型并实现可持续运营,以下我们将梳理 AI 大模型私有化部署架构,并针对架构中的关键组件进行解读。
下载《构建企业 AI 基础设施:技术趋势、产品方案与测试验证》电子书,了解更多 AI 大模型私有化部署技术解读、方案评估与性能评测!
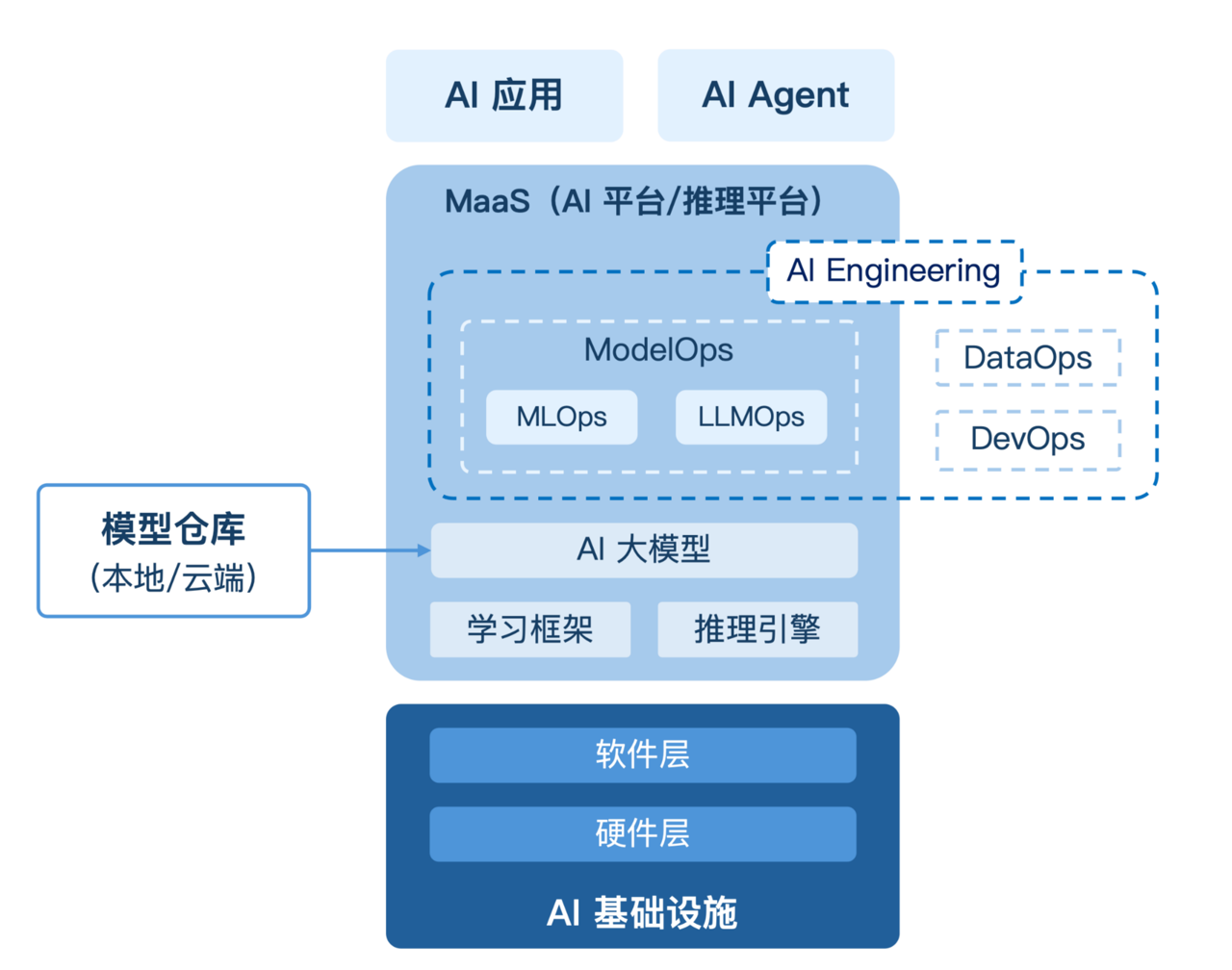
AI 基础设施
AI 基础设施包括硬件层和软件层两个维度,他们是支持人工智能系统部署和运行所需的 IT 基础设施服务,像“地基”一样为 AI 模型和应用的运行提供坚实支撑。
基础设施硬件
包括硬件服务器及必要组件,如计算硬件(GPU、CPU、FPGA 等)、存储硬件(如高速 SSD/HDD)、网络硬件(高速网卡、交换机与路由器等)。一些厂商推出了专门为 AI 大模型设计的一体机,提供预装好的 GPU 和 AI 模型,不过这些一体机动辄好几百万,对于投入有限或是前期小规模部署验证的企业来说并不十分合适。
基础设施软件
包括操作系统和优化硬件资源调度的计算层软件与存储层软件。
- 计算层:企业用户可以选择以虚拟机、Kubernetes 作为 AI 大模型的主要运行环境。虚拟机具备成熟的运维体系和更高的模型兼容性,因为当前部分模型的微调和推理阶段尚未提供完善的容器化封装,在依赖库、驱动和环境适配上更适合以虚拟机形式运行。而 Kubernetes 则更适用于已容器化的任务,能提供更好的弹性伸缩和故障恢复能力。因此,混合使用虚拟机与 Kubernetes 已成为目前企业支持多类型 AI 工作负载的主流方案。
- 存储层:由于 AI 工作流程的各个阶段对存储的需求都有所不同,建议企业选择软件定义的高性能分布式存储,同时考虑存储的多元化数据支持能力、灵活部署能力、数据管理能力、灵活扩展能力、性能、Kubernetes 支持能力、性价比等多个维度。
学习框架和推理引擎
除了 AI 基础设施,为了实现 AI 大模型的训练和推理,还需要引入学习框架和推理引擎。模型的核心任务是从大量数据中学习规律,完成特定预测或者生成任务,前者即“模型训练”,后者即“模型运行”。在模型训练时,通常由工程师准备训练用的数据(训练集和测试集),由学习框架调用数据以完成模型的训练。模型训练好后,工程师完成模型的分发并通过推理引擎将模型运行起来,用户通过 API 来调用这个模型,完成特定的任务。
举个例子
- 游戏开发商通过各种工具(学习框架)完成游戏(模型)的开发。
- 游戏开发商将开发好的游戏“烧录”到卡带或者在平台发布数字版游戏(训练好的模型)。
- 玩家使用兼容这个游戏的游戏主机(推理引擎)来玩游戏(使用模型)。
对于不同的模型,使用的学习框架和推理引擎是有所区别的。
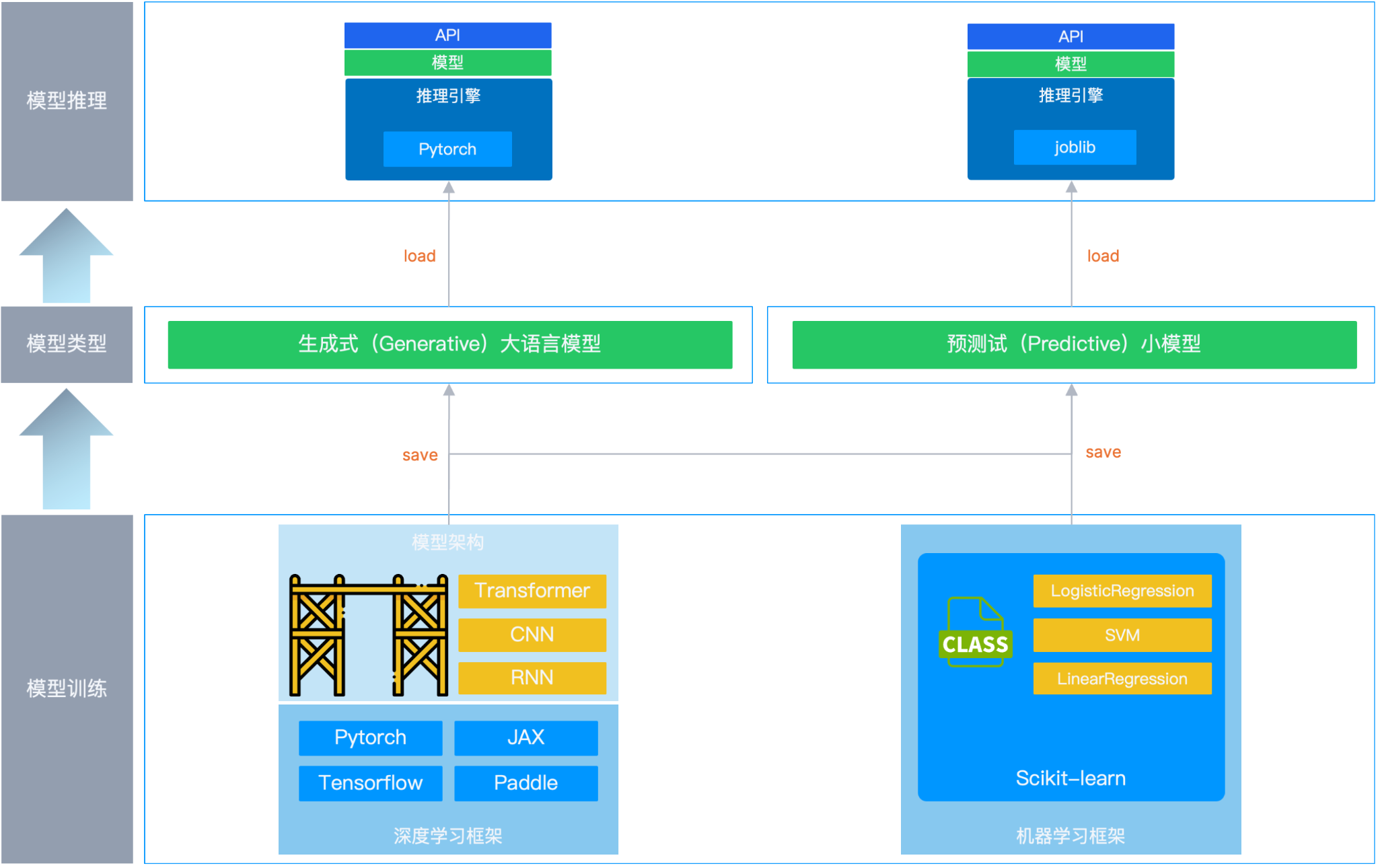
预测式(Predictive)小模型
这类模型参数较少、层数较浅,在解决如垃圾邮件检测的分类问题中,可使用诸如 Logistic Regression 这类的逻辑回归多元分类模型来实现预测任务。在训练时,通常借助 Python 中的 Scikit-learn(sklearn)机器学习框架来快速调用已经实现好的逻辑回归模型,通过 fit 方法完成训练。
- Scikit-learn:一个专门为机器学习设计的库,就像 os 或 math 一样,是 Python 生态中的标准工具之一。
- LogisticRegression:在 sklearn 中,它既可以说是一个“模型”,也可以称作“算法”,在代码层面表现为一个类(LogisticRegression)。
* 如:from sklearn.linear_model import LogisticRegression
模型训练好后一般被保存成 joblib、pkl 等格式,通过采用推理引擎加载运行。此时推理引擎主要负责读取并加载训练好的模型文件、提供模型预测 API 接口、调用模型对象 predict 方法进行预测,并将预测结果返回给用户。
生成式(Generative)大模型
这类模型参数较多、层数较深,具有更强的表达能力和更高的准确度。在解决文本生成、摘要的问题中可使用诸如 CNN、RNN 和 Transformer 这类架构来实现生成任务。在训练过程中,可以借助 Pytorch、Tensorflow、JAX 等深度学习框架基于不同的模型架构(CNN、RNN 和 Transformer)实现生成式模型。
- Pytorch:一个专门为深度学习设计的库,就像 os 或 math 一样,是 Python 生态中的标准工具之一。
- Transformer:与上面的 LogisticRegression 不同,它并不是一个已经实现好的模型 ,而是一个实现模型的框架,类似于脚手架,通过 Pytorch 中实现的“类”(import torch.nn as nn) 按照这个框架可以实现一个高性能的模型。
模型训练好后一般被保存成 safetensors、gguf 等格式,采用 vllm、sglang、llama.cpp 等推理引擎。这类推理引擎更为复杂,除了提供 API 接口并读取/加载模型,还会循环调用模型对象 forward() 方法逐步生成 Token、管理 KV-Cache 缓存,并将生成结果实时返回给用户。
可以通过如下图示再了解下整个过程:
模型仓库
在训练好模型后,还需要引入模型仓库(Model Registry)来实现模型的管理、获取与分发。模型仓库是一个用于集中存储、管理和分发 AI 模型的系统或目录结构,方便模型在团队内部或跨系统之间进行共享、版本控制和部署。
- 本地模型仓库:由开发人员在完成模型训练后自己创建和维护。
- 云端模型仓库:包括开源和企业级模型仓库平台,如 Hugging Face,允许用户间共享大模型并进行版本管理等操作。
以上三类技术是实现 AI 大模型私有化部署的最简单的架构——在构建好 AI 基础设施并配置好学习框架和推理引擎后,用户可以自行训练并验证模型,然后通过模型仓库发布模型或获取其他训练好的模型,实现模型的训练、部署与使用。
不过在实际应用过程中,尤其是企业级部署、交付、管理 AI 大模型时,经常会遇到模型文件管理复杂、模型交付慢、多种模型难以高效统一管理等问题。另外,直接从模型仓库获取的 AI 大模型,也需要根据实际业务场景和业务数据进行模型微调,以达到企业级使用效果。这些就需要引入 AI Engineering 工具来实现 AI 大模型从实验室搭建到企业级应用的“最后一公里”。
AI Engineering(AI 工程)
根据 Gartner《Hype Cycle for AI in Software Engineering, 2025》报告,AI Engineering 是企业大规模交付 AI 和 GenAI 解决方案的基础性工程,整合了 DataOps(数据可运营)、 ModelOps(模型可运营)和 DevOps(开发可运营)流水线*,帮助企业构建一个连贯的 AI 系统开发、部署和运营框架。
* DataOps:通过敏捷、统一的数据管理实践来提升企业数据流水线的传输、整合与自动化,旨在让企业更简单、快速、广泛地从数据中获取价值。
DevOps:通过整合软件开发与运营以加速软件交付,旨在提升业务价值、管理成本并降低风险。ModelOps 将在下方详细解读。
ModelOps
在以上 Gartner 的定义中,ModelOps 是 AI Engineering 的核心,专注于人工智能(AI)、决策模型、深度分析的端到端治理与生命周期管理。ModelOps 关注的模型既包括生成式人工智能(GenAI)模型,也包括基于机器学习(ML)和知识图谱的模型。
根据《Demystify the Ops Landscape to Scale AI Initiatives: A Gartner Trend Insight Report》,ModelOps 的核心工作包括模型的管理、部署、可解释性、回退/再训练/微调/升级、监控、整合、合规与审计、安全与私有化等方面(见下图)。通过 ModelOps,不同团队间可规范多种模型在不同环境(例如开发、测试和生产环境)中的构建、测试、部署、运行和监控方式,最终达到简化模型部署难度、提升推理性能与资源利用率、高效进行多模型管理的目标。
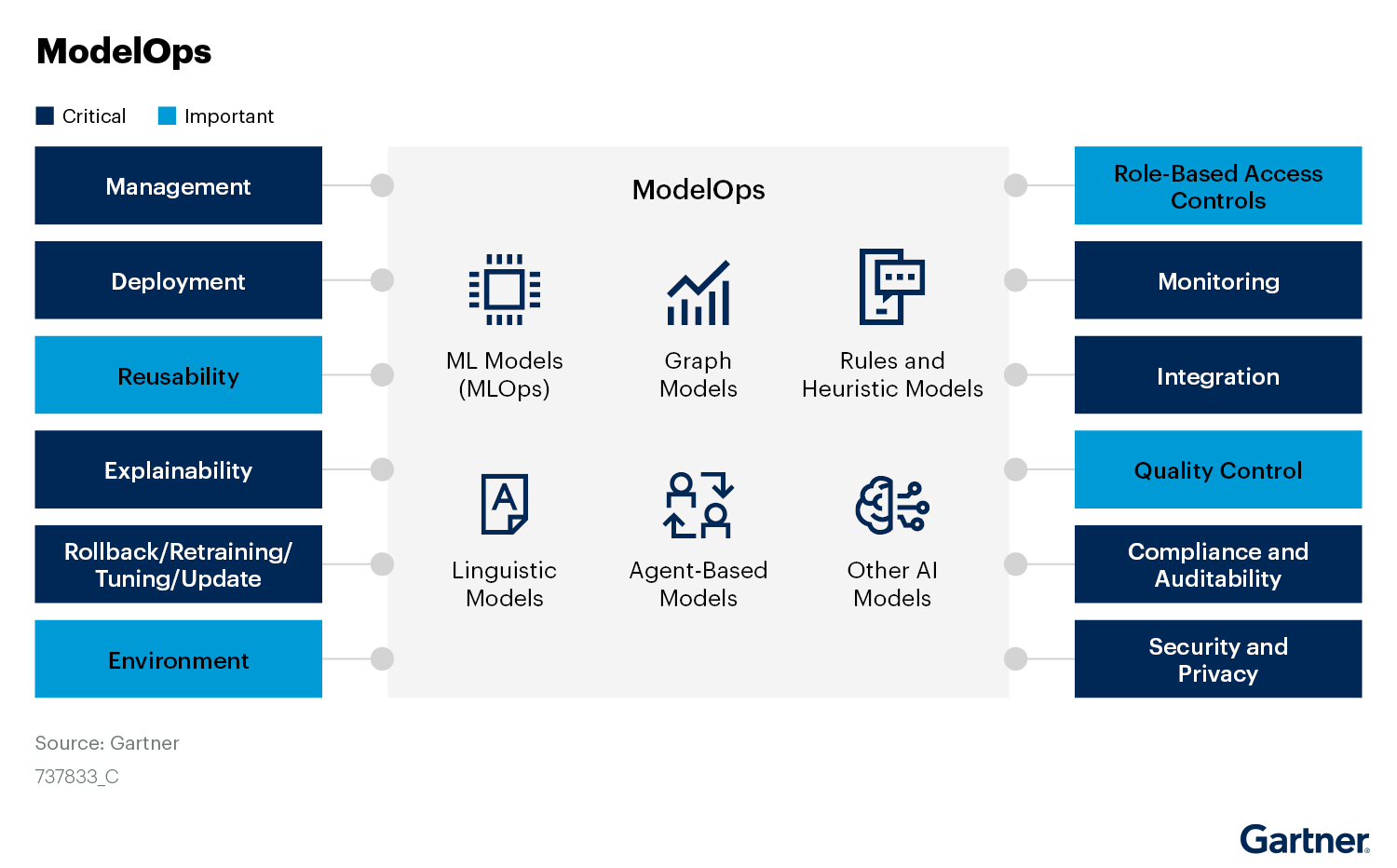
ModelOps vs MLOps vs LLMOps
MLOps(机器学习可运营)和 LLMOps(大语言模型可运营)是在 ModelOps 之下的概念—— ModelOps 不仅关注机器学习和大语言模型,还关注图模型、决策模型、深度分析等多种模型的运营管理。MLOps 旨在简化机器学习模型的端到端开发、测试、验证、部署和实例化过程。LLMOps 则是在 MLOps 框架下针对大语言模型的“定制化实践”,重点解决大语言模型相较其他机器学习模型的独特挑战(如模型体积优化、模型微调、提示工程、上下文管理等)。
MaaS(Model as a Service)
ModelOps 通常由企业 IT 团队自行负责,传统上,其环境搭建、模型开发/下载、模型部署、训练微调、资源监控与优化……所有环节均由运维人员手动操作完成,整个过程费时费力,模型交付慢,后期多模型管理复杂繁琐。
因此,不少云服务商为企业提供了 MaaS(模型即服务,一些厂商也将其产品称为“AI 平台”或“推理平台”),为企业用户提供“开箱即用”的大模型服务,简化模型部署、管理与微调,提升推理效率与资源利用率。具体的能力一般包括:
- 模型仓库:存放可调用的预训练模型(大语言模型、NLP、CV、语音等)。
- 算力资源管理:不同位置的异构算力资源统一管理。
- 推理服务:预集成运行模型的推理引擎和推理框架(如 vLLM、Llama.cpp、SGlang)。
- API / SDK 接口:提供 HTTP/gRPC 等调用方式。
- 模型管理:多模型统一运维管理。
- 可观测性:统计资源使用率,推理实例性能表现(TTFT、TPOT、ITL 等)。
- 计量与计费:统计调用次数、Token 使用情况等。
- 安全与权限控制:限制访问、保护数据隐私。
AI 应用和 AI Agent
在 AI 应用与 Agent 层面,除了与大模型对接的普通应用系统,企业也可以构建 AI Agent(人工智能代理)来提供各种服务。
AI Agent 是一种能够感知环境、做出决策、执行行动并根据反馈不断调整行为的 AI 系统。普通的应用系统虽然也可以通过调用大模型 API 的方式获取 AI 能力,但通常需要用户每次明确指令,上下文通常也依赖用户输入或临时变量。AI Agent 则更像一个能够“自主决策的大脑”,仅需用户提供目标,自己规划多个步骤调用模型与其他工具,也通常具有“长期记忆”(如知识库)。
更多 AI 大模型私有化部署技术解读、方案评估与性能评测,欢迎下载《构建企业 AI 基础设施:技术趋势、产品方案与测试验证》电子书!
推荐阅读:
AI实践分享|以MCP简化IT运维管理,生成定制化报表(附操作演示)
SmartX AI 基础设施新增昇腾 NPU 与 MindIE 支持能力:方案与评测