AI 基础设施并不仅仅是“使用 GPU 的服务器”,根据 Gartner《Innovation Insight for GenAI Infrastructure》报告,完整的 AI 基础设施应包括 3 个层级:针对 AI 进行优化的物理基础设施、提供编排与治理能力的 AI 平台,以及最大化 AI 价值的“AI 即服务”(AI as a Service)和 Xops 流程。
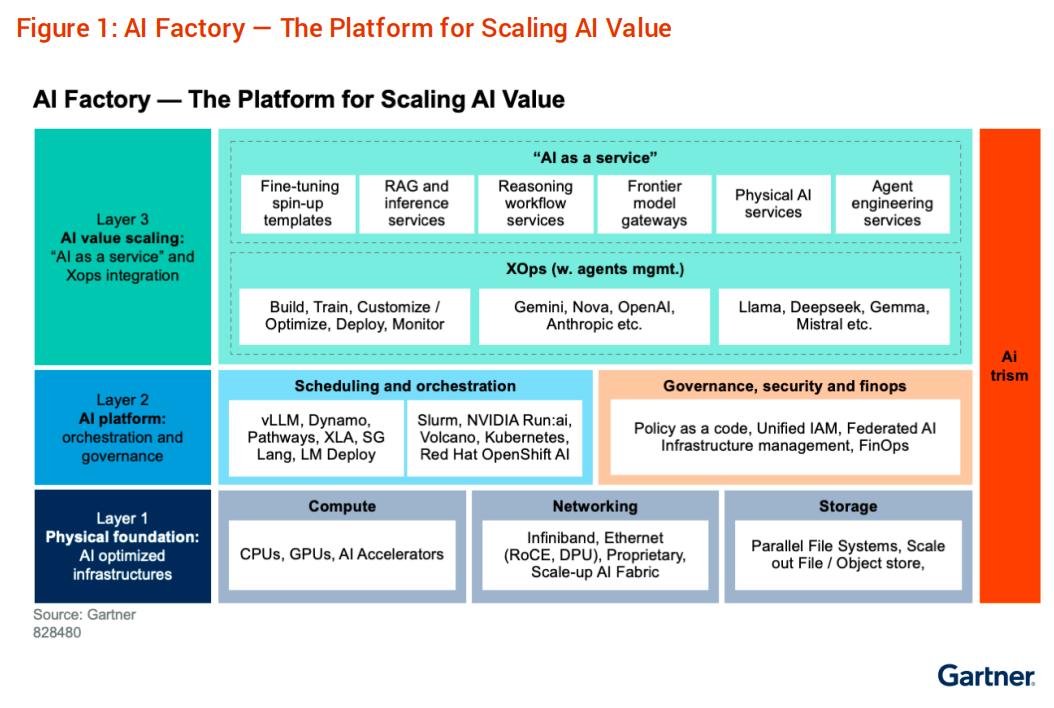
第一层:针对 AI 进行优化的物理基础设施
为构建完善的 AI 基础设施,企业必须从传统的 IT 基础设施建设思维转变为以 AI 为核心的整体规划,构建由多种面向 AI 优化的技术栈组成的基础设施体系,并在总体拥有成本(TCO)与系统性能之间达到最优平衡。AI 物理基础设施主要包括:
计算加速器
AI 基础设施不再追求单一的“最佳”芯片方案,企业应构建多元化的加速器组合(包括 CPU、GPU、TPU、FPGA 等),并根据不同业务场景的性能需求和成本约束,选择最适合的加速器类型,实现最优配置。
- 基础通用 GPU:适用于追求研发速度、产品迭代效率以及多类型工作负载的场景。成熟的软件生态不仅降低开发门槛,也有助于吸引顶尖技术人才。
- 新兴通用 GPU:更适用于大规模、单一模型的训练任务。其创新的内存架构有助于简化基础设施设计,并有效降低系统延迟。
- AI 加速器:适用于高吞吐、固定模式的推理任务(如推荐引擎),可大幅降低 TCO 和功耗。
高性能网络
网络架构的选择至关重要,会直接决定未来 AI 模型和应用的运行成本与性能表现。企业不仅需要关注网络带宽的大小,更需要在垂直整合网络的简化管理与开放标准网络的灵活扩展之间做出取舍。同时,需要针对不同的应用场景评估适合的网络架构——选择连接不同系统的横向扩展架构(Scale-out),或是连接系统内加速器的纵向扩展架构(Scale-up)。
1. 横向扩展架构
- 无损专有网络:如 InfiniBand,适用于追求极致性能的大规模训练集群,目标是尽可能缩短任务完成时间。其优势在于操作简化,具备低时延和高吞吐能力,但对生态体系依赖度较高。
- 开放标准以太网:如基于融合以太网的远程直接内存访问(RoCEv2),适合希望保持供应商多样性、并利用现有网络和人才的组织。企业初期需要承担更高的调优成本(尤其是引入 UEC 等新兴标准时),但长期来看,可获得更高的灵活性与成本掌控能力。>>了解更多:解决 SAN 交换机“卡脖子”并升级存储架构?一文解析 RoCE 与相关存储方案趋势
- 数据处理单元(DPU)增强型以太网:通过从 CPU 中卸载网络与安全任务,从而最大限度释放计算资源,使其专注于核心 AI 工作负载,在多租户场景中表现尤为突出。
2. 纵向扩展架构
- 高速专有互连:如 NVIDIA NVLink,适用于训练和推理超大规模的基础模型。该结构可使多个加速器像一个统一的处理器一样协同运行,并提供最大带宽。
- 开放标准互连:如 UALink,适用于追求灵活性、希望降低对单一计算加速器供应商依赖的组织,从而降低长期使用风险。
面向 AI 的存储基础设施
以容量为导向的传统存储架构,已无法满足生成式 AI 对高性能存储的要求。企业需要构建一个多层数据存储架构,通过尽可能提升数据吞吐能力,缓解计算资源(如 GPU)匮乏的问题,避免因存储瓶颈影响 AI 工作负载效率。
在这一背景下,企业不应只建设数据湖,而是要打造一个统一的数据服务工厂,将数据存储和传输融入 AI 工作流,并针对特定工作负载开展性能优化。具体建设思路可参考 Gartner 的生成式 AI 存储设施 3 大关键能力与部署方案。建议存储设施具备如下能力:
- 高吞吐量的并行文件系统:作为训练阶段的全闪存“热层”,提供极致的数据吞吐能力。通过消除存储瓶颈,使昂贵的 GPU 和 ASIC 集群保持数据满载状态。
- 全闪分布式文件系统/对象存储平台:作为核心数据湖,用于数据准备与混合 I/O 工作负载运行,旨在为海量小文件提供高性能处理能力。
- 专用 AI 数据集成平台:适用于 MLOps 环境,提供数据治理、版本管理与工作流自动化能力,确保训练过程的可重复性与合规性。
第二层:提供编排与治理能力的 AI 平台
在 AI 场景中,除了物理基础设施,企业还需要引入第二层基础设施——AI 平台层,将底层的原始计算资源转化为可供多租户使用的平台与编排栈。这意味着,企业需要从传统的孤立部署应用的方式,转向构建一个统一的操作系统支持“AI 工厂”运作,并将计算资源作为可共享、可管理的开放平台。AI 平台需要具备以下能力:
弹性资源编排
AI 平台需要将异构硬件资源转化为一个可互换、可共享的多租户资源池,以满足生成式 AI 高度波动的资源需求。企业应构建一个统一的 AI 工厂操作系统,使 AI 产品和 AI Agent 的研发、训练与部署能够在同一平台上实现动态、共享式的编排,最大限度提高 GPU 和 ASIC 的投资回报率(ROI)。
1. 基础控制平面
- 云原生编排:如 Kubernetes,可作为覆盖本地、云端和边缘环境的统一控制平面。提供标准化、可移植的 API,管理所有容器化的生成式 AI 工作负载,是承载 AI 平台上其他工具与能力的基础。>>了解更多:基于 Cluster API 的 Kubernetes 集群生命周期管理
2. 专门的工作负载调度和编排
- 高级 AI 编排器:如具有类似 NVIDIA Run:ai 功能的工具。构建于 Kubernetes 之上,实现对计算加速器资源的动态共享调度。通过队列管理与资源分块,可在同一集群中混合运行训练与推理任务,从而显著提高资源利用率。
- 高性能计算(HPC)调度器:如 SchedMD 的 Slurm,可集成部署在 Kubernetes 环境中,以支撑大规模、强耦合的基础模型训练所需的吞吐能力。可在任意基础设施上运行传统 HPC 工作负载。
3. 应用层运行时和引擎
- 高级推理引擎:如 vLLM、SGLang、NVIDIA Dynamo 和 Google Pathways。强制使用这些运行时,可显著降低生产推理的单 token 成本(cost-per-token)。这类引擎采用新型内存管理技术,可显著提升 GPU 吞吐能力,为高并发的 RAG 与对话式 AI 应用提供高性能支撑。>>了解更多:学习框架和推理引擎有什么区别?
平台治理、安全和财务运营
这一能力通过可透明、可审计、可计费的内部服务模式,使企业在风险把控、成本管理与性能优化之间实现最佳平衡。
1. 安全、治理和风险管理
- “策略即代码”:旨在为混合环境创建统一、强制、可审计的安全策略。无论容器运行在本地、云端或托管的 AI 集群,系统都能自动阻止不合规的工作负载运行,避免手动审查。
- 统一身份和访问管理:通过记录系统,确保每个操作都可追溯到特定主体(人或机器)。在排查跨混合环境的代理工作流或审计数据驻留时,这条不可篡改的“责任链”至关重要。
2. 平台工程
- 联合集群管理:其隐性目标是实现跨平台的策略性工作负载调度,所有操作都通过一个无缝衔接的工作流程完成。
- 整体可观测性和可追溯性:旨在保障整个分布式 AI 供应链的安全。企业应能够追溯有问题的 AI 输出——从云端托管的推理 API,到模型最后一次微调所在的本地集群,最终定位到训练所用的数据源。
3. 财务运营
AI 财务运营与成本治理不仅关注成本控制,更是对整个混合 AI 工厂的损益管理。平台需提供统一的成本视图,为业务部门生成一张综合账单,包含本地 GPU 使用的分摊成本和云端推理调用的按量计费成本,从而准确计算出 AI 项目的投资回报率。
第三层:最大化 AI 价值的“AI 即服务”和 XOps 流程
在推动 AI 转型进程中,企业还需要关注如何将 AI 平台升级为一个高效、可审计、财务透明的内部 AI 服务市场。因此,企业需要引入第三层基础设施——“AI 即服务”和 Xops 流程,帮助 AI 开发人员无缝创建符合企业规范的模板化 AI 推理架构与代理环境。>>了解更多:ModelOps/MLOps/LLMOps 有什么区别?
助力 AI 落地的 XOps 流程
通过简化基础设施,XOps 流程可为研发人员提供一个标准化、自服务的生产流水线,提高 AI 从创意到生产部署的全流程效率。XOps 策略必须与企业的 AI 基础设施建设相匹配,构建覆盖整个 AI 开发生命周期的多层技术体系。
- 自服务门户和工具:作为 AI 工厂的统一入口,为数据分析人员提供自助式的计算资源与工具访问能力。这不仅能提升生产力,也能显著降低运维管理负担。
- 自动化管道和工作流引擎:充当模型开发的“装配线”。通过自动化 MLOps 生命周期,确保治理一致性、可重复性并加速创新。
- 分布式 AI 运行时:作为核心扩展引擎,使单个训练任务能在庞大的加速器集群上分布式运行。
以“As-a-Service”为目标
为了提高资源利用率,企业必须构建一个联合控制平面——通过统一视图,引导团队在本地部署、开放权重模型与云专属前沿模型之间权衡利弊。
- 按需训练环境:利用平台蓝图,为开放权重模型提供自服务的本地训练环境。团队可在最大程度保障数据隐私与控制权的前提下,对敏感企业数据进行微调。
- 内部 RAG 与推理工作流:提供“一键式”模板,用于部署开放权重模型以支撑内部 RAG 或推理任务。适用于高吞吐、成本敏感且数据完全私有的场景。
更多 AI 知识科普、AI 大模型落地方案与 AI 基础设施建设实践,欢迎阅读往期博客:
AI 模型落地关键概念解读:推理引擎/ModelOps/MaaS/AI Agent…
AI实践分享|以MCP简化IT运维管理,生成定制化报表(附操作演示)
SmartX AI 基础设施新增昇腾 NPU 与 MindIE 支持能力:方案与评测
如何基于 SmartX 超融合满足企业 DeepSeek 快速落地验证需求?
欲了解更多 AI 基础设施的技术趋势、产品方案与测试验证,欢迎下载《构建企业 AI 基础设施:技术趋势、产品方案与测试验证》电子书!