Summary
1. VMware vSphere supports 4 snapshot formats, which are VMFSsparse, SEsparse, vSANSparse and vVols/native snapshots.
2. In terms of VMFSsparse, SEsparse and vSANSparse snapshots, I/O performance depends on various factors, such as I/O type (read vs. write), physical location of data, snapshot level, redo-log size, and type of base VMDK.
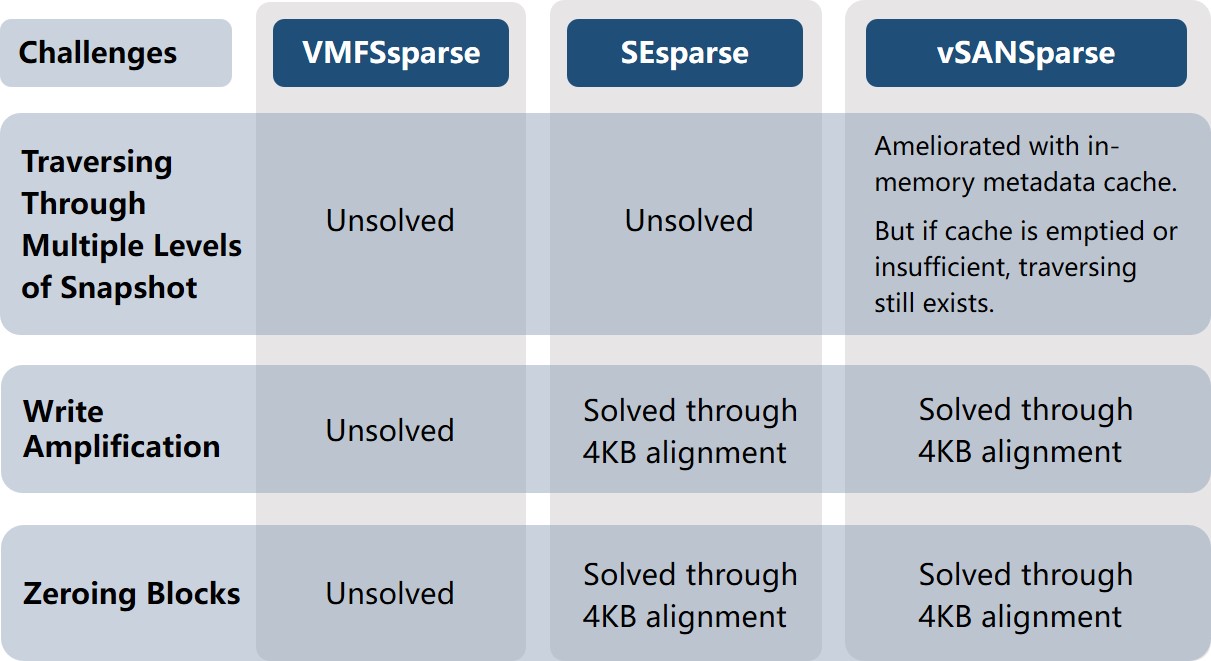
3. VMware vSphere snapshot evolves according to the following sequence: VMFSsparse ->SEsparse -> vSANSparse. Based on VMFSsparse, SEsparse reduces write amplification by aligning partitions to 4KB boundaries. vSANSparse, on the base of SEsparse, further improves I/O performance through in-memory metadata cache mechanism.
4. Different from VMware vSphere snapshot which relies on redo-log files and disk chains, SMTX OS snapshot uses independent metadata to avoid snapshot traversal. It also uses a larger extent to contain data. These features effectively reduce latency and enable a rapid restoration of I/O performance after taking a snapshot.
5. Since no dependency exists between snapshots taken by SMTX OS, deleting snapshots can be more efficient and with less processes.
The virtual machine snapshot is a commonly used feature in the virtualized environment. We usually use snapshots to preserve the state and data of VMs at the specific point of time when installing software and changing system configurations. Despite the convenience it brings, taking snapshots with VMware vSphere may result in problems such as lower VM performance and complexity in snapshot management, and eventually affect the business performance and O&M efficiency.
To help readers gain a better understanding of how snapshot works in VM and impacts I/O performance, we will evaluate VMware vSphere snapshots’ and SmartX SMTX OS (SmartX’s core HCI software) snapshot’s technical mechanism. We’ll also compare the snapshot performance of the two software through the test.
How VMware vSphere Snapshots Work
Snapshot Definition
According to VMware, a snapshot preserves the state and data of a VM at a specific point in time.
- The state includes the VM’s power state (for example, powered on, powered off, suspended).
- The data includes all the files that make up the VM. This includes disks, memory, and other devices, such as virtual network interface cards.
A VM provides several operations for creating and managing snapshots and snapshot chains. These operations let you create snapshots, revert to any snapshot in the chain, and remove snapshots.
Snapshot Formats
- VMFSsparse
VMFSsparse, also referred to as the redo-log format, is a traditional/basic format of VMware vSphere snapshot. VMFS5 uses the VMFSsparse format for virtual disks smaller than 2 TB.
- SEsparse
SEsparse is the default format for all delta disks on VMFS6 datastores. SEsparse is a format similar to VMFSsparse with some enhancements. This format is space efficient and supports the space reclamation technique. On VMFS5, SEsparse is used for virtual disks of the size 2 TB and larger.
- vSANSparse
The vSANSparse format leverages the underlying sparseness of the new VirstoFS filesystem (v2) on-disk format and a new in-memory caching mechanism for tracking updates. It improves snapshot performance while retaining the redo-logs mechanism. It can only take place on vSAN clusters and requires that the VM has no existing VMFSSparse/redo log format snapshots.
- vVols/native snapshots
In a VMware virtual volumes (vVols) environment, data services such as snapshot and clone operations are offloaded to the storage array. So for this format snapshots are not operated on VMware vSphere.
This article mainly focuses on the first three formats as in which snapshots take place on VMware vSphere.
Technical Mechanism
VMFSsparse
VMFSsparse is a virtual disk format used when a VM snapshot is taken or when linked clones are created off the VM. VMFSsparse is implemented on top of VMFS and I/Os issued to a snapshot VM are processed by the VMFSsparse layer. VMFSsparse is essentially a redo-log that grows from empty (immediately after a VM snapshot is taken) to the size of its base VMDK (when the entire VMDK is re-written with new data after the VM snapshotting). This redo-log is just another file in the VMFS namespace and upon snapshot creation the base VMDK attached to the VM is changed to the newly created sparse VMDK.
Comprised Files
- .vmdk and -delta.vmdk
All virtual disks on VMware vSphere have the .vmdk extension of files. When a snapshot is created, .vmdk files will create files with the -delta.vmdk extension. The collection of .vmdk and -delta.vmdk files for each virtual disk is connected to the virtual machine at the time of the snapshot. These files can be referred to as child disks or delta links. These child disks can later be considered parent disks for future child disks. From the original parent disk, each child constitutes a delta pointing back from the present state of the virtual disk, one step at a time, to the original.
- .vmsd
The .vmsd file is a database of the virtual machine’s snapshot information and the primary source of information for the Snapshot Manager. The file contains line entries which define the relationships between snapshots as well as the child disks for each snapshot.
The Disk Chain
Generally, when you create a snapshot for the first time, the first child disk is created from the parent disk. While the parent disk contains the complete block of data before the snapshot is taken, the child disk only records changed blocks and accesses unchanged blocks in the parent disk. Successive snapshots generate new child disks from the last child disk on the chain. The relationship can change if you have multiple branches in the snapshot chain.
This diagram is an example of a snapshot chain. Each square represents a block of data or a grain as described in the preceding section:
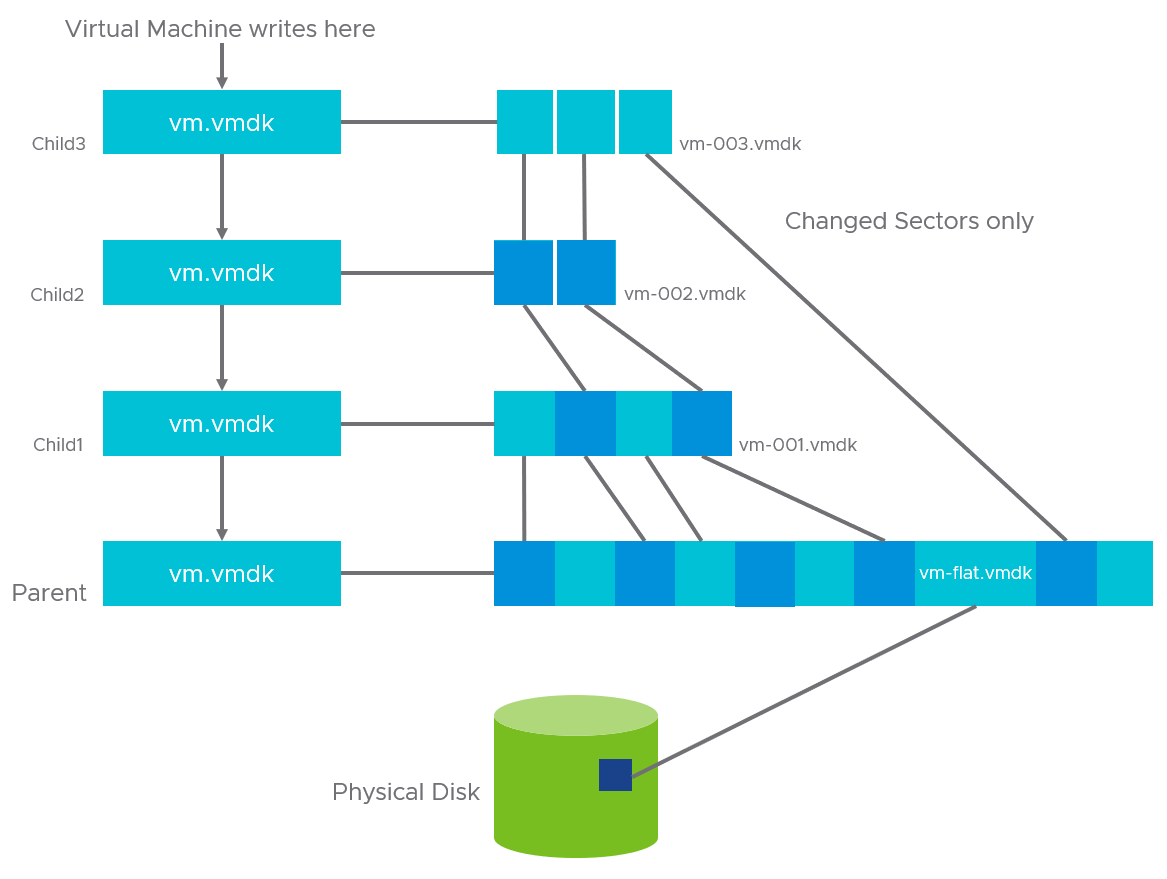
Source: Overview of virtual machine snapshots in vSphere (1015180)
I/O Mechanism
Because VMFSsparse is implemented above the VMFS layer, it maintains its own metadata structures in order to address the data blocks contained in the redo-log. The block size of a redo-log is one sector size (512 bytes). Therefore the granularity of read and write from redo-logs can be as small as one sector. When I/O is issued from a VM snapshot, vSphere determines whether the data resides in the base VMDK (if it was never written after a VM snapshot) or if it resides in the redo-log (if it was written after the VM snapshot operation) and the I/O is serviced from the right place. The I/O performance depends on various factors, such as I/O type (read vs. write), whether the data exists in the redo-log or the base VMDK, snapshot level, redo-log size, and type of base VMDK.
Factors Affecting I/O Performance
- I/O type
Read and write performs differently when a snapshot is taken.
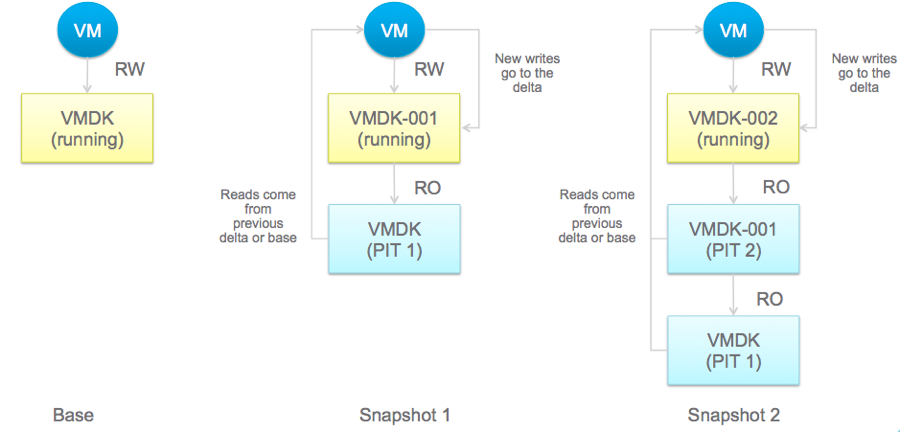
Source: vsanSparse Snapshots
After a VM snapshot takes place, if a read I/O is issued, it is either serviced by the base VMDK or the redo-log, depending on where the latest data resides. This mechanism may not be physical-disk-friendly as some sequential read I/O may change to random read I/O.
For write I/Os, if it is the first write to the block after the snapshot operation, new blocks are allocated in the redo-log file, and data is written after updating the redo-log metadata about the existence of the data in the redo-log and its physical location. If the write I/O is issued to a block that is already available in the redo-log, then it is re-written with new data.
- Snapshot depth
As the snapshot depth increases, performance decreases because of the need to traverse through multiple levels of metadata information to locate the latest version of a data block.
Below shows an example of I/O performance with different snapshot depths. After taking 32 snapshots, VM performance drops significantly to nearly 0, and will not restore within an hour.
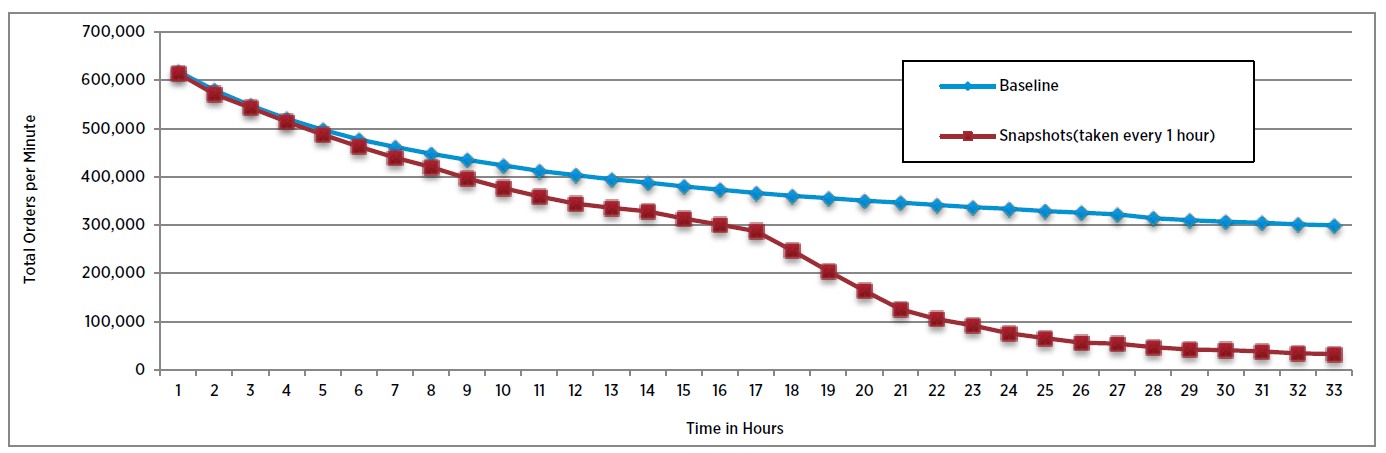
Source: VMware Virtual SAN Snapshots in VMware vSphere 6.0
- Base VMDK type
Base VMDK type impacts the performance of certain I/O operations. After a snapshot, if the base VMDK is thin format, and if the VMDK hasn’t fully inflated yet, writes to an unallocated block in the base thin VMDK would lead to two operations: (1) allocate and zero the blocks in the base, thin VMDK and (2) allocate and write the actual data in the snapshot VMDK. There will be performance degradation during these scenarios.
SEsparse
SEsparse is a new virtual disk format that is similar to VMFSsparse (redo-logs) with some enhancements and new functionality. One of the differences of SEsparse with respect to VMFSsparse is that the block size is 4KB for SEsparse compared to 512 bytes for VMFSsparse. Most of the performance aspects of VMFSsparse discussed above — impact of I/O type, snapshot depth, physical location of data, base VMDK type, etc. — applies to the SEsparse format also.
In addition to a change in the block size, the main distinction of the SEsparse virtual disk format is space-efficiency. With support from VMware Tools running in the guest operating system, blocks that are deleted by the guest file system are marked and commands are issued to the SEsparse layer in the hypervisor to unmap those blocks. This helps to reclaim space allocated by SEsparse once the guest operating system has deleted that data, achieving the goal of saving storage space.
4KB Alignment Ameliorates Write Amplification
A single 4KB guest OS write, when running on a VMFSsparse snapshot, could result in significant write amplification. This single guest OS 4KB write could generate multiple write operations on the back-end storage array.
In the diagrams below, an example is shown where a single 4KB I/O is issued from the guest OS. The issue with VMFSsparse disks is that they are backed by block allocation unit sizes of 512 bytes. This means that in a worse case scenario, this 4KB I/O may involve 8 distinct 512-byte writes to different blocks on the underlying VMFS volume, and in turn lead to 8 I/Os issued to the array, what is termed in the industry as write amplification.
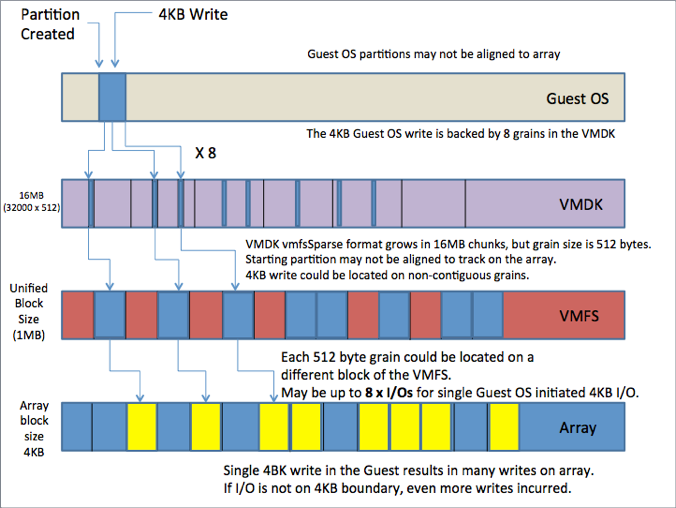
Source: vsanSparse Snapshots
Using SESparse with a new block allocation size of 4KB, the 4KB I/O from the Guest OS will use a single block in the VMDK, which in turn will use a single VMFS block (1 MB), and generate a single I/O to the array.
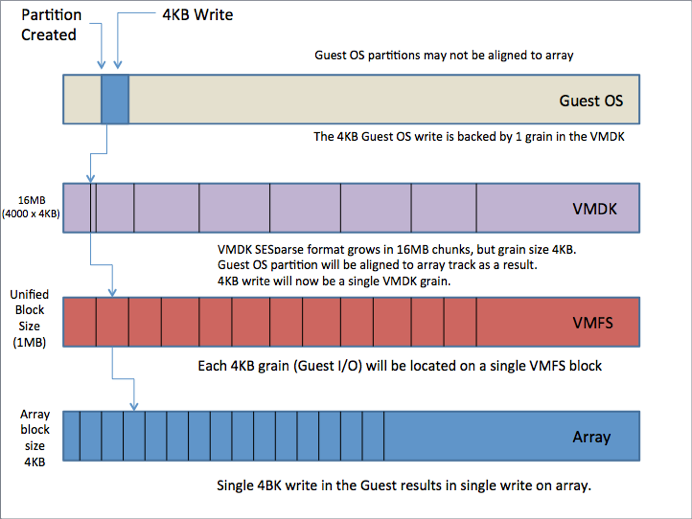
Source: vsanSparse Snapshots
Examination of 4KB Alignment Effect
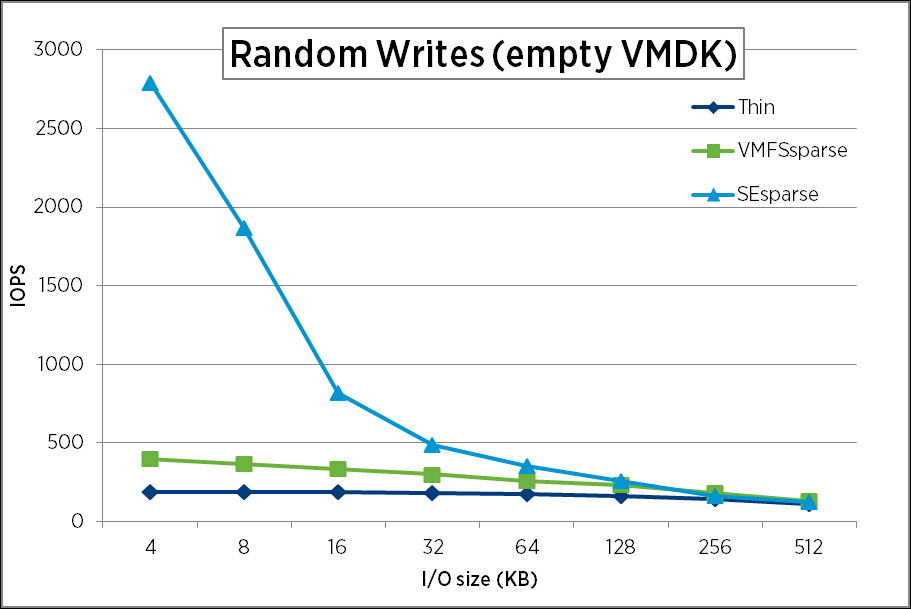
The graphs below illustrate the performance of VMFSsparse and SEsparse delta-disks compared against the thin VMDK when processing blocks with different sizes generated by IOMeter.
Source: SEsparse in VMware vSphere 5.5
Thin random write performance is the lowest across all the data points because for the thin case, we first zero the blocks before writing actual data. This is because VMFS allocates blocks at a 1MB granularity while only part of that area may be filled with real data. Zeroing prevents applications from reading sensitive residual data from an allocated 1MB region of the physical media. In contrast, when reading from SEsparse and VMFSsparse formats, allocations happen in much smaller block sizes, namely 4KB and 512 bytes, respectively, and therefore there is no need to zero the blocks if I/O is at least 4KB and it is 4KB aligned (for the other cases, we do a read-modify-write operation).
SEsparse performs far better than the thin and VMFSsparse formats in the case of random writes. This is because SEsparse implements intelligent I/O coalescing logic where these random I/Os are coalesced into a bigger I/O and the disk controller does a better job of scheduling these I/Os for better performance. Note that SEsparse performs on par with or better than VMFSsparse only in cases when the I/Os are aligned to 4KB boundaries. This is because for I/Os smaller than 4KB, or if an I/O is not aligned to the 4KB boundary, writes to SEsparse can result in a read-modify-write operation, increasing overhead. However, almost all file systems and applications are 4KB aligned and therefore SEsparse performs well in common use cases.
vSANSparse Snapshot
vSANSparse, introduced in vSAN 6.0, is a new snapshot format that uses in-memory metadata cache and a more efficient sparse filesystem layout; it can operate at much closer base disk performance levels compared to VMFSsparse or SEsparse.
When a read I/O request arrives at Virtual SAN, the snapshot logic traverses through the levels of the snapshot tree and composes the information as to which Virtual SAN object and what offset contains the data requested. This addressing information is then cached in the Virtual SANsnapshot metadata cache. The snapshot metadata cache exists in memory, and it is critical to the read performance of snapshots. This is because, for every miss in this cache, the address information has to be obtained by traversing through multiple levels of snapshot, which increases latency. This cache also prefetches the addressing information so that workloads with localized access patterns can benefit. This metadata cache, however, is limited in size and is shared across VMDKs that are open in the system. Therefore, when the cache is full, the least recent address information is flushed out.
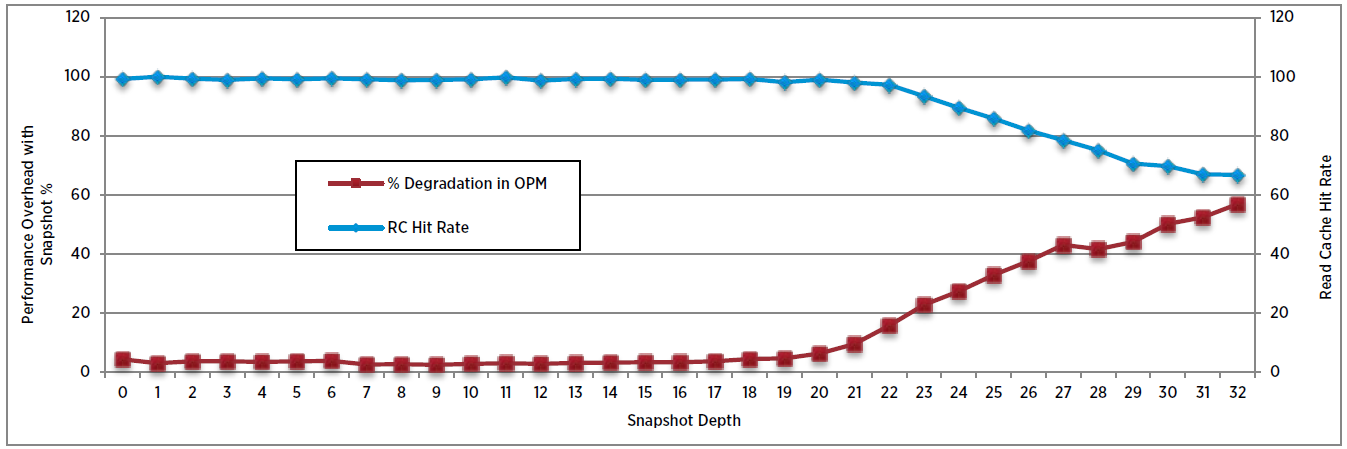
The figure below shows the impact of the Virtual SAN read cache hit rate on snapshot performance.
Source: VMware Virtual SAN Snapshots in VMware vSphere 6.0
The Virtual SAN read cache hit rate remains more than 98% until snapshot level 19. This shows that vSANSparse improves read I/O operations considerably. But beyond that the hit rate drops steadily leading to I/Os being served from the magnetic disk layer, increasing latencies. After taking 32 snapshots, OPM (orders per minute, the primary performance metric of DVD Store) drops by about 56%. Moreover, since the snapshot metadata cache exists in memory, cache will be lost if the host reboots, leading to performance decrease of VMs with snapshots.
The below table summarizes guest application performance loss in the presence of one snapshot with a variety of workloads on VMFS and vSAN.

Source: VMware vSphere Snapshots: Performance and Best Practices
It can be seen that vSANSparse significantly improves I/O performance with 1 snapshot depth.
But how well does vSANSparse snapshot perform as snapshot depth increases?
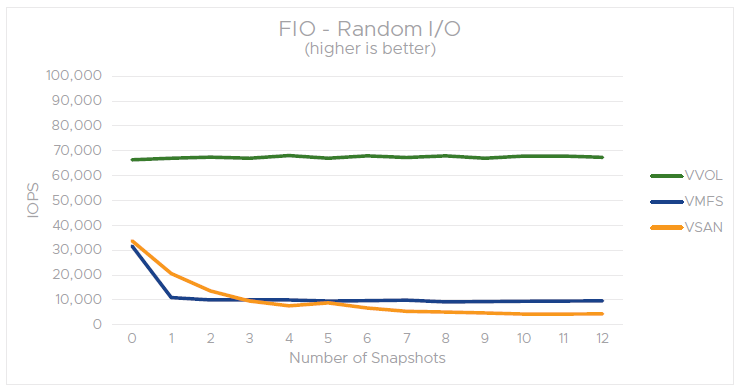
FIO – Random I/O performance with snapshots on VMFS, vSAN, and vVOL (50% read,50% write)
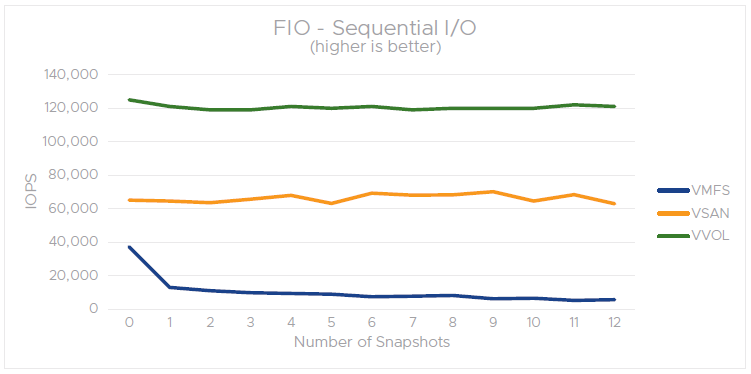
FIO – Sequential I/O performance with snapshots on VMFS, vSAN, and vVOL (50% read,50% write)
Source: VMware vSphere Snapshots: Performance and Best Practices
It can be observed that the presence of VM snapshots on a vSAN datastore has minimal impact on guest application performance for workloads that have predominantly sequential I/O. In the case of random I/O tests, similar to the VMFS scenario, we observe substantial impact on guest performance on vSAN. That is, as the number of snapshots increases, vSANSparse is less effective in optimizing random I/O.
Comparison of The Three Formats
vSANSparse snapshot may have considerable impact on performance when:
- snapshot level increases;
- the host reboots or a VM powers off because the cache will be erased. Therefore, the next time the virtual disk is opened, the cache is cold and needs to be filled up, leading to unnecessary latency; or
- merging snapshots multiple times before a snapshot can be deleted.
How SMTX OS Snapshot Works
Snapshot Definition
SMTX OS snapshot preserves the data and resource configuration of a virtual machine at a specific point in time.
The virtual machine snapshot contains the following data:
- Data of virtual machines, including all virtual volumes (except the shared virtual volumes).
- Configuration information of virtual machines, for instance, the number of vCPUs, memory size, disk boot sequence, and network configuration, etc.
SMTX OS snapshot supports the crash consistency snapshot1 and file system consistency snapshot2 though it does not support memory snapshot3 for now. Moreover, the snapshot supports management operations such as creating snapshots, restoring any snapshot, removing the snapshot of any moment separately, and rebuilding (cloning) the snapshot at a particular moment. Notably, VMware vSphere snapshot does not allow users to delete the snapshot located in the snapshot chain individually. The deletion can only be accomplished after combining multiple snapshots taken afterwards.
Technical Mechanism
Unlike VMware vSphere snapshot, SMTX OS is not designed based on the redo-log file. As a result, the snapshot chain structure does not exist in SMTX OS snapshot, leading to the independence between snapshots.
Parts Included
There is no VMFS file system layer or VMDK file layer in SMTX OS snapshot. Instead, it has a simpler structure with only two parts:
- metadata
The metadata information structures for both the snapshot and the virtual volume (vDisk) are similar, with each containing the extent table. If the virtual disk has multiple snapshots, each snapshot has its own metadata (including physical location information of all extents related to the snapshot). And the metadata is stored in the database in the distributed meta service (zbs-meta).
- extent
The data of the snapshot is stored in extents (each with 256MB). Generally, a snapshot consists of several extents. After taking a snapshot, changed data will be stored in new extents while unchanged extents will be shared between the snapshot and original vDisk.
I/O Mechanism
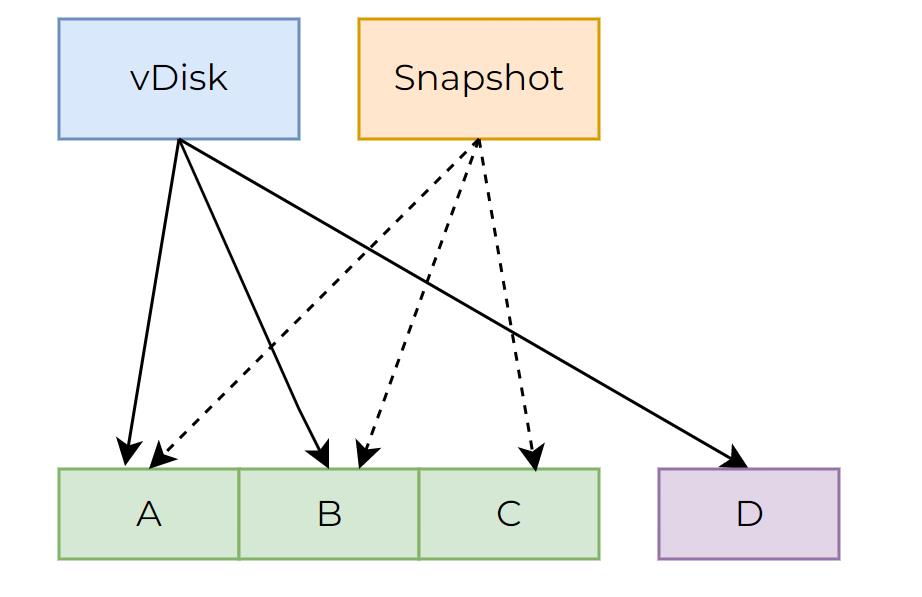
A vDisk has its own metadata information and stores the mapping relationships between vDisk and the original extents. Once a snapshot operation is carried out, the system will generate independent snapshot metadata information and record the extent mapping relationships related to the snapshot (as shown in the figure below). If there is no change to the data, snapshot’s corresponding extents are fully consistent with those of vDisk. This is to say, the snapshot and vDisk share all extents, and the snapshot does not occupy any additional storage space.
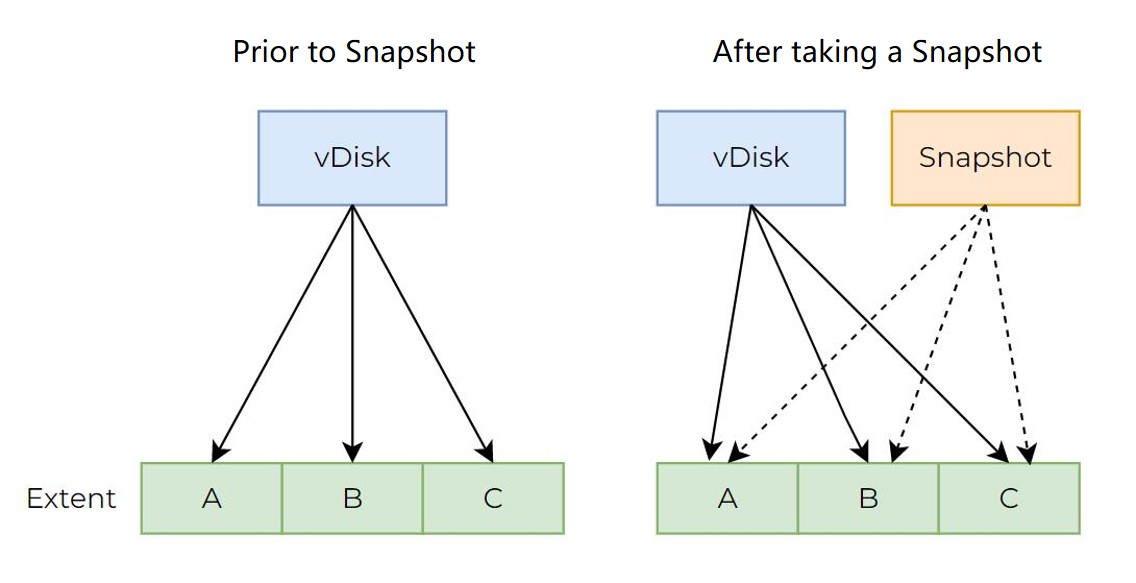
When a write I/O is issued, if it is the first write to the extent after the snapshot operation (the extent is not assigned), it will be assigned a new extent. The metadata information of vDisk and mapping relationship between the vDisk and new extent will be updated.
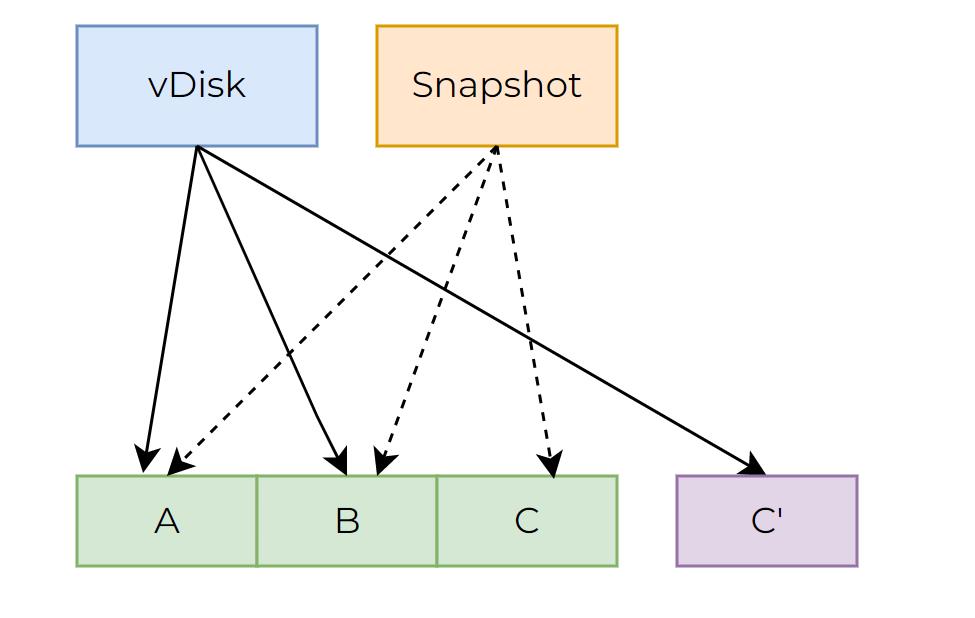
If the written extent has been assigned in the original vDisk, the system will, likewise, assign a new extent (in the example shown below, the new extent is extent C‘), update the metadata information of vDisk and the mapping relationship between vDisk and the newly assigned extent. However, this may lead to multiple read-modify-write I/O operations.
Notably, a block (each with 256KB) is the data block unit smaller than extent. As the extent is 256MB, one extent contains 1024 blocks.
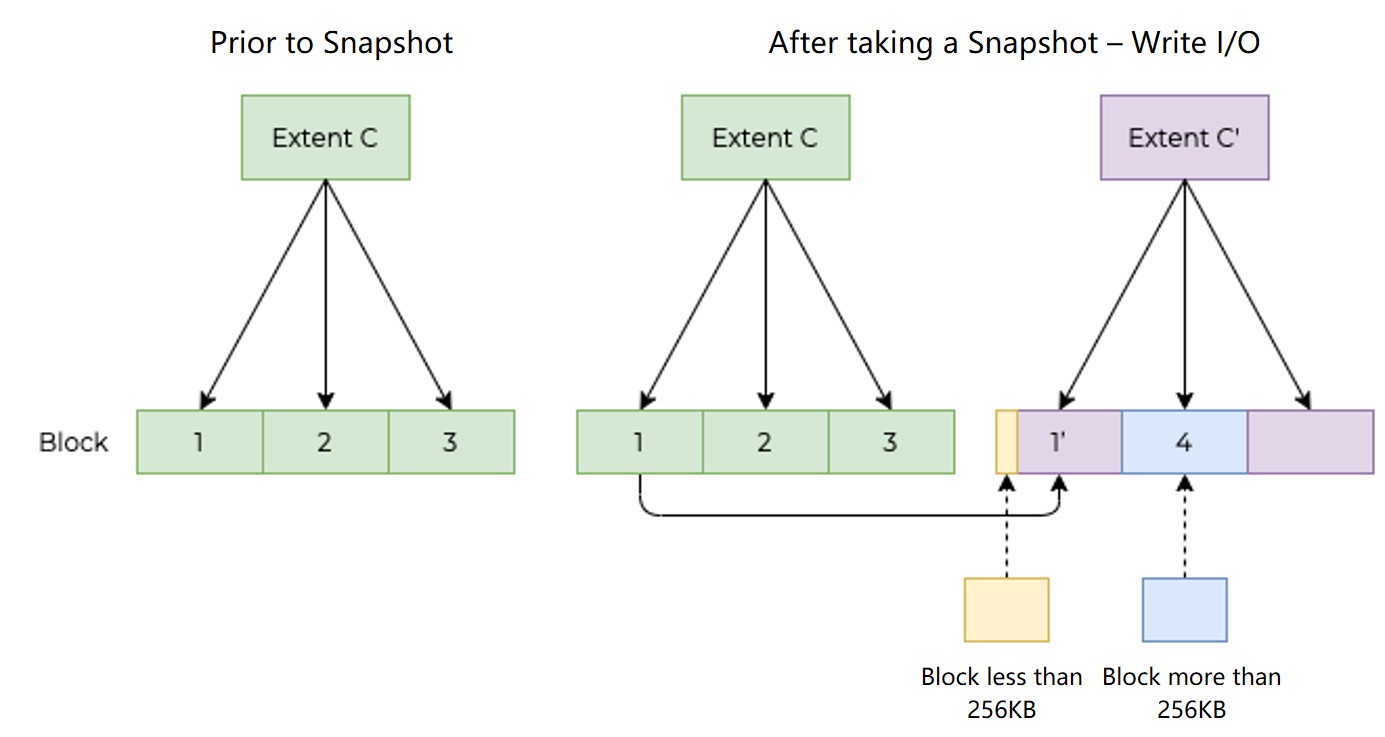
If the write I/O is less than 256KB (for instance, with 4KB data to be written), it will read data from the corresponding block in the original extent (in the example shown above, the original extent is extent C) and modify data, and then writing the modified data to the corresponding block in new extent (in the example shown above, the new extent is extent C’). If the write I/O is aligned to 256KB, it will be directly written to the new location instead of reading blocks.
If a read I/O is issued, it is serviced by both snapshot blocks and original vDisk blocks. Since the mapping relationships are always updated as the latest version, it does not need to traverse through all the snapshot levels to locate the data in SMTX OS. This effectively reduces the read latency.
Moreover, since the metadata of SMTX OS snapshot is stored in the ZBS distributed storage MetaServer cluster (i.e., in the memory), it can provide faster responses. Also, as the metadata will be persistently updated to the SSD medium, it can be loaded to the memory rapidly even after the host reboots.
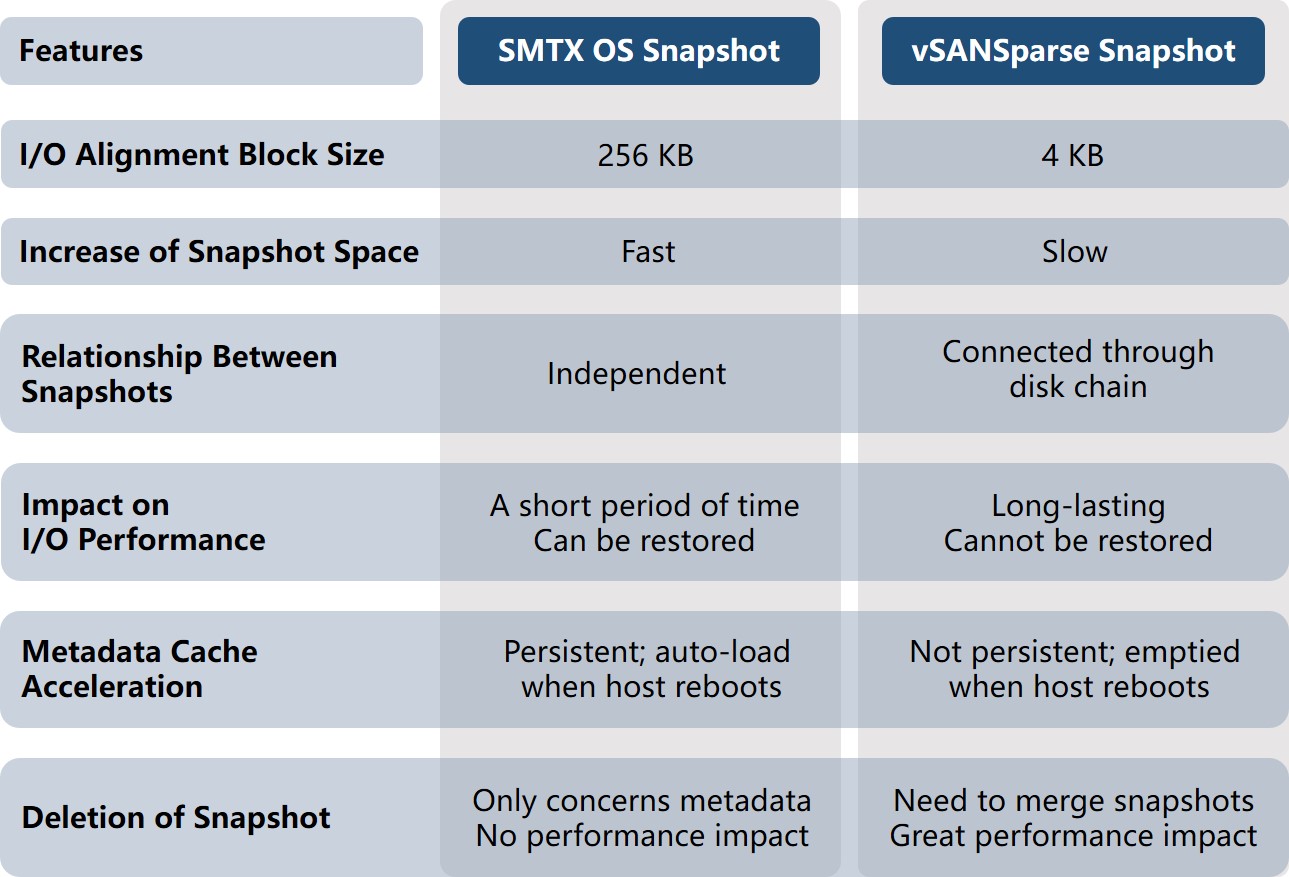
VMware vs. SmartX: Snapshot Features
VMware vs. SmartX: I/O Performance After Taking Snapshot
We tested the 4K random write I/O performance of SMTX OS 5.0 and vSAN 7.0 before and after taking a snapshot. The test was conducted under the same hardware configurations.
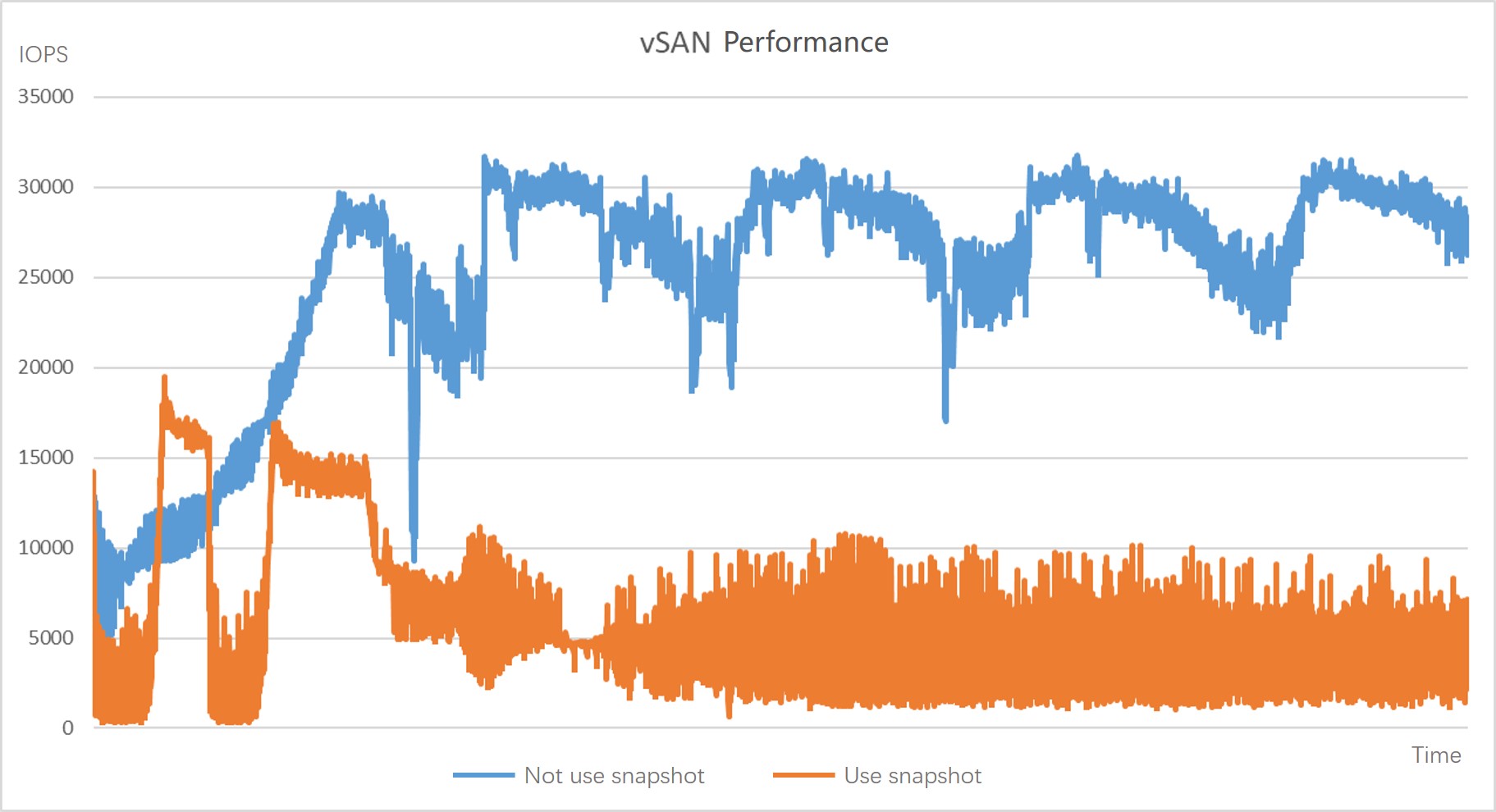
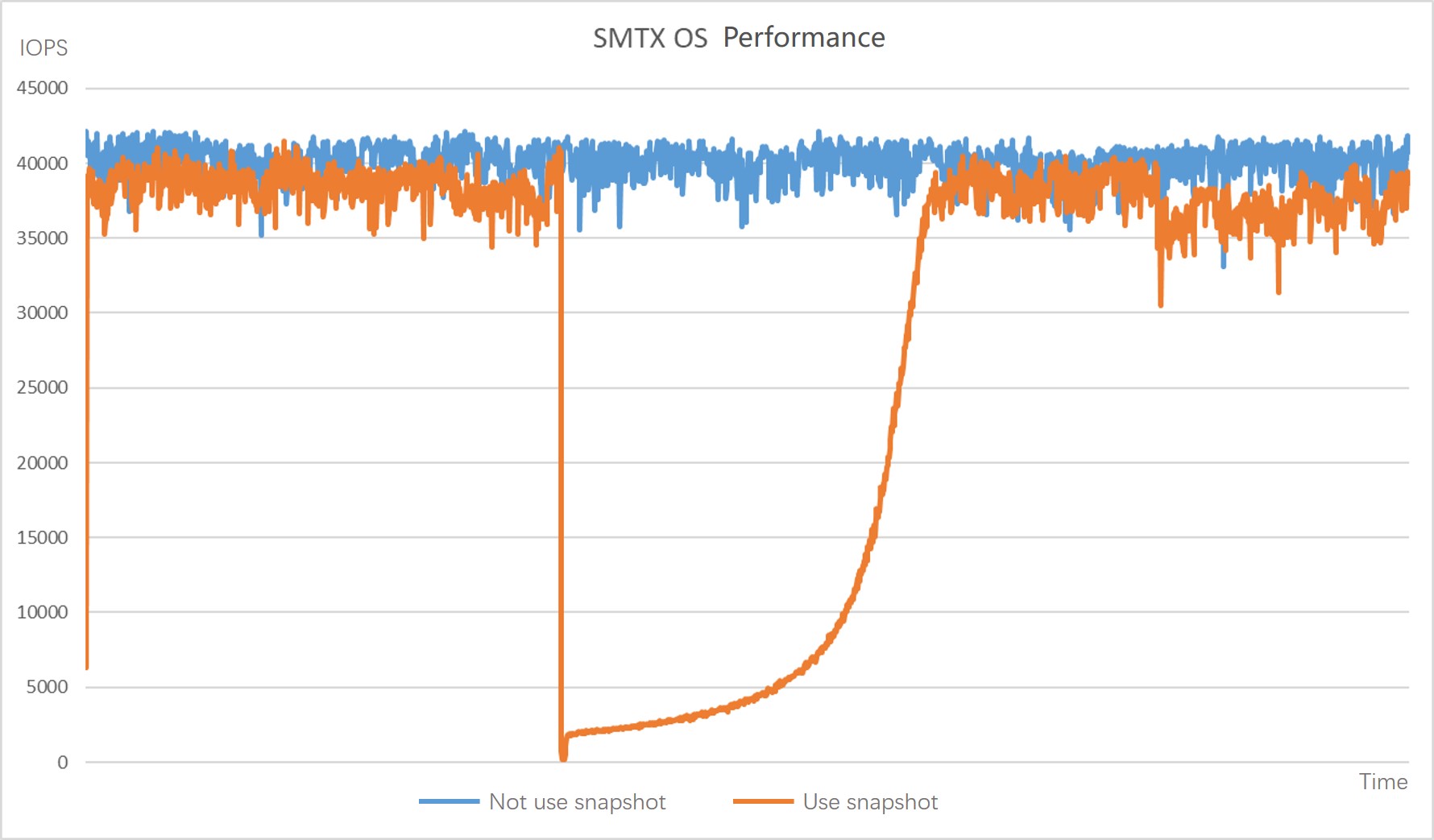
As we can see from the results, after vSAN created a snapshot, the VM performance decreased by 60% and could not be recovered. On the contrary, after SMTX OS created the snapshot, the VM performance dropped drastically for a short period of time and then gradually recovered. The complete recovery took about 20 minutes.
Conclusion
Through a comprehensive analysis of VMware vSphere snapshots’ and SmartX SMTX OS snapshot’s technical mechanism, and a test of SMTX OS’s and vSAN’s snapshot performance, we can come up with following conclusions:
- Different from VMware vSphere snapshot which relies on redo-log files and disk chains, SMTX OS snapshot uses independent metadata and larger extents. This helps SMTX OS snapshot avoid factors that influence VMware vSphere snapshot I/O performance, significantly reducing the time period of performance degradation and enabling performance restoration.
- SMTX OS snapshot is not based on the disk chain structure, which can ensure the independence of multiple snapshots, simplify the management of snapshots (e.g., snapshot deletion), and reduce the O&M pressure of IT engineers.
In addition, if users deploy SMTX OS with VMware vSphere (SMTX OS provides shared storage services for vSphere), it is viable to use vVols/native snapshots and offload vSphere snapshots operations to SMTX OS through VAAI.
Crash consistency snapshot1: the crash consistency snapshot records the data already written into the vDisk. It will not capture the data in the memory or waiting I/O operations. So this type of snapshot cannot ensure the consistency of the file system or application. You may be unable to restore the virtual machine with the crash consistency snapshot.
File system consistency snapshot2: aside from the data on the vDisk, the file system consistency snapshot will record all data in the memory and the I/O operations to be handled. Before taking the file system consistency snapshot, the file system on the visitor operating system will enter the quiesce state with all file system cache data in the memory and I/O operations to be handled updated to the hard disk.
Memory snapshot3: memory snapshot means that when the virtual machine performs snapshot operation, in addition to performing snapshot over the hard disk data, the virtual machine will enter the quiesce state and the memory will also take the snapshot and store the memory data permanently; when restoring the virtual machine snapshot, the memory snapshot data may be loaded.
References:
- Overview of virtual machine snapshots in vSphere (1015180)
https://kb.vmware.com/s/article/1015180?lang=en_us - vsanSparse Snapshots https://core.vmware.com/resource/vsansparse-snapshots#section1
- VMware Virtual SAN Snapshots in VMware vSphere 6.0 https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/vsan-snapshots-vsphere6-perf-white-paper.pdf
- SEsparse in VMware vSphere 5.5 https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/sesparse-vsphere55-perf-white-paper.pdf
- VMware vSphere Snapshots: Performance and Best Practices https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/performance/vsphere-vm-snapshots-perf.pdf