Author: SmartX FSI Team

In this article, we will describe the storage architecture of SmartX distributed block storage ZBS, focusing on its key capabilities and how we achieve them.
Storage Architecture
In general, designing distributed storage architecture revolves around three components: metadata service, data storage engine, and consistency protocol. The figure below shows ZBS’s architecture.
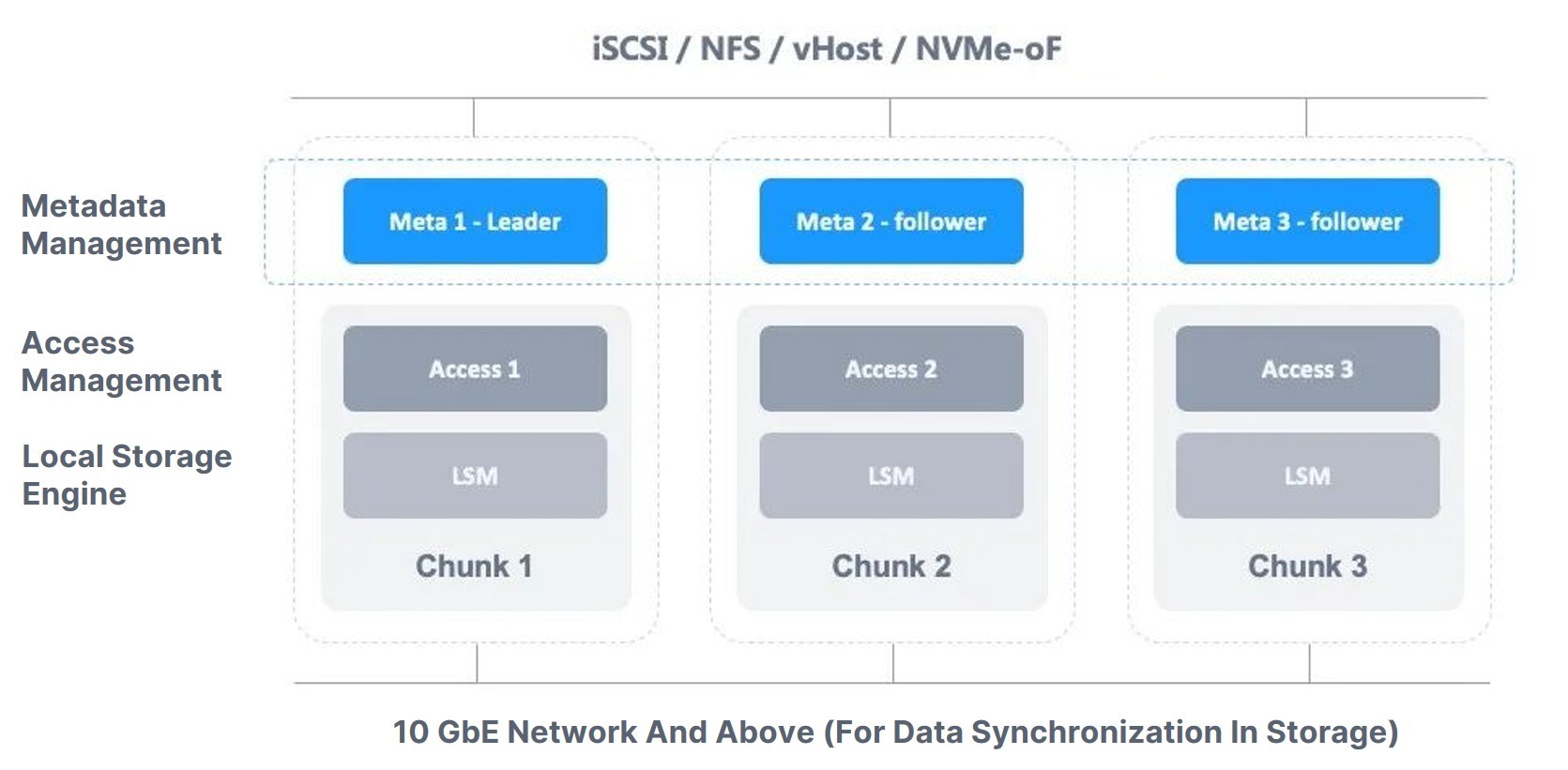
Meta is the distributed cluster’s central management unit, performing tasks such as cluster member management, storage object management, data addressing, replica allocation, access management, data consistency, workload balancing, heartbeat and garbage collection, and so on.
Chunk, the storage of ZBS, is in charge of managing data storage within each node. It also manages local disks and handles issues such as damaged disk or slow disk. And as storage engines are independent of one another, a consistency protocol is required to ensure consistent data access, meeting our expectations towards ZBS.
Access management enables ZBS to provide reliable and high performance to storage services. As shown in the figure above, ZBS supports flexible and rich protocols to meet the needs of various use cases. We will dive in that point in subsequent articles.
Overall, a distributed storage system is built around the components listed above. The differences between distributed storage systems are generally due to different component choices.
Meta (Metadata Service)
Metadata is the “data of data”. If the metadata is lost, or the metadata service fails to function properly, the data in the entire cluster will be inaccessible. Meanwhile, the response capability of the metadata service impacts the overall performance of the storage cluster. Therefore, when designing ZBS, we focused on three capabilities, which are
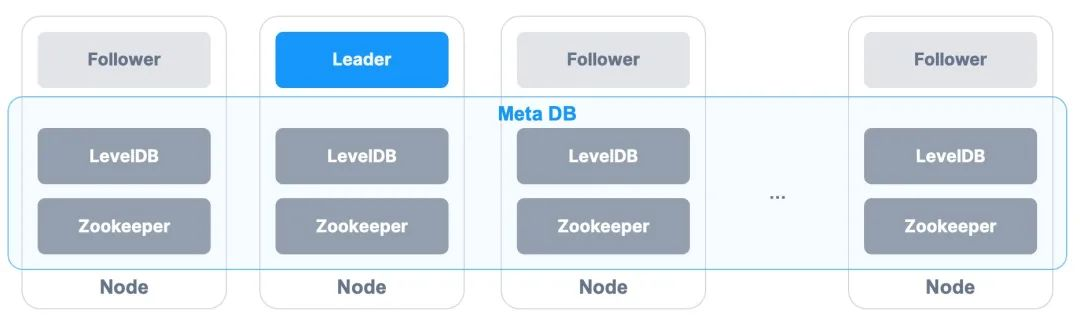
- Reliability: For the single Master architecture, metadata must be stored in multiple copies. Meanwhile, the metadata service needs to allow high error tolerance and quick switching. Using distributed databases to perpetuate and synchronize the metadata will complicate the overall architecture. Eventually, ZBS decided to adopt the local KV DB to fulfill metadata persistence of the meta server. We used the Log Replication mechanism to realize data synchronization of the metadata among multiple nodes. When Meta Lead fails, the Follower node quickly takes over the metadata service by selecting the Master.
- High performance: The goal is to minimize the participation of the metadata service in the storage I/O path. Because ZBS separates the control plane from the data platform, the majority of the I/O requests do not need to access the metadata service. If the metadata needs to be modified (e.g. data allocation), the metadata operation must respond quickly enough. ZBS defines Extent (the data block) to be 256 MiB. Even in a 2 PiB cluster, all metadata can be loaded into the memory for operation, increasing the efficiency of the inquiry.
- Lightweight: To make the architecture simple, ZBS does not divide nodes into management and data nodes. Instead, with proper resource optimization, ZBS deploys the metadata service and data service on the same node, enabling the minimal cluster of 3 nodes and eliminating management nodes.
Storage Engine
We paid special attention to the storage engine’s reliability, consistency, performance and ease of O&M, just as we did in the design of metadata service.
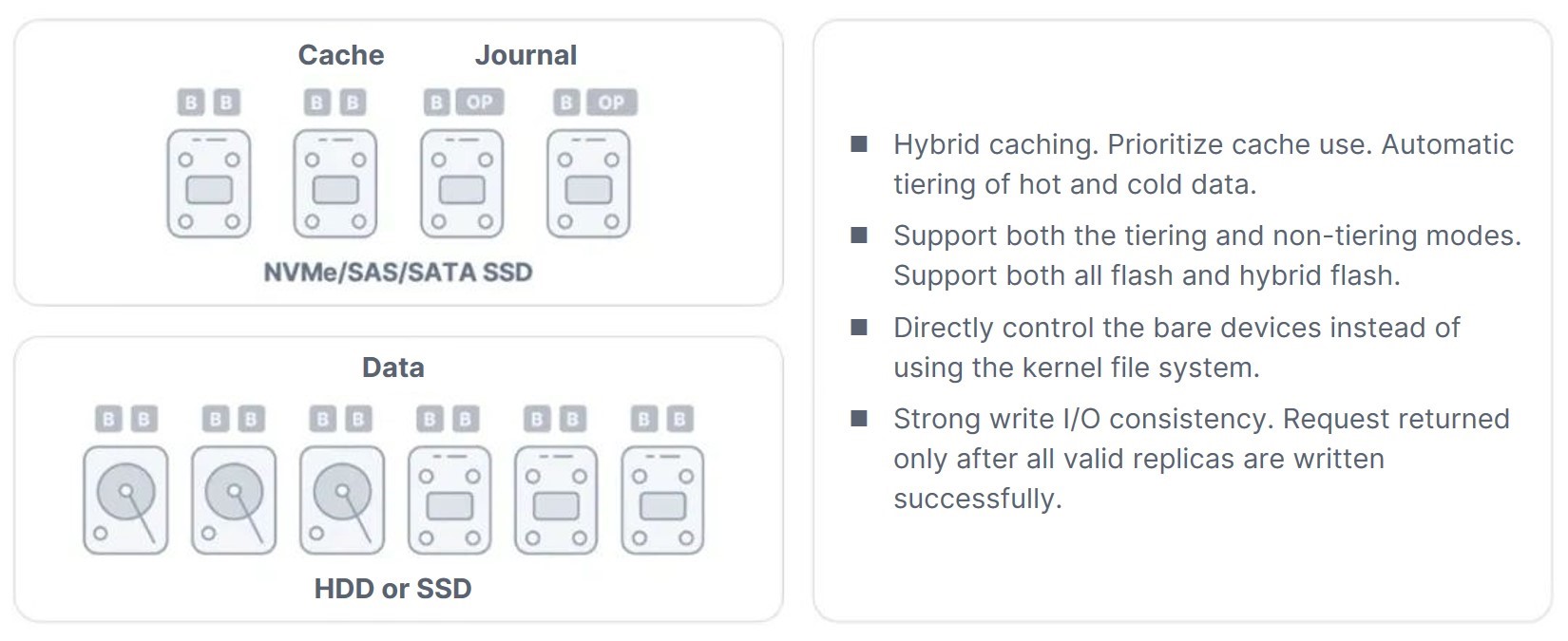
- Reliability: ZBS relies on the replica for data protection. This technology will check the version number of replicas to achieve data consistency. When the number of replicas falls below expectation, data reconstruction will be automatically triggered. Furthermore, Meta will address dirty data and perform garbage connection on a regular basis.
- Performance: ZBS supports all flash and hybrid flash storage solutions that can meet a wide range of performance requirements. Furthermore, as hardware devices improve in data transmission speed (NVMe, 25 GbE, and so on), the performance bottleneck will shift from hardware to software, specifically the storage engine. ZBS strives to improve storage engine performance through program lock, context switching, and other means.
- Bare device management: Instead of using the existing file system as the storage engine, ZBS runs data allocation, space management and I/O logic on the bare devices. This design avoids file system issues such as performance overhead and Journal write amplification.
- O&M: ZBS O&M has two objectives. First, it should be simple to use and upgrade, allowing users to perform daily O&M with ease. Second, it should be simple to troubleshoot so that IT engineers can quickly locate and repair the problem. One option is to use Kernel Space. Kernel Space can improve performance but may cause serious issues such as debugging and upgrading difficulties. This has the potential to expand the Kernel module fault domain and eventually pollute the Kernel. As a result, ZBS uses User Space for storage engine, simplifying software upgrades and avoiding the Kernel pollution.
Data path
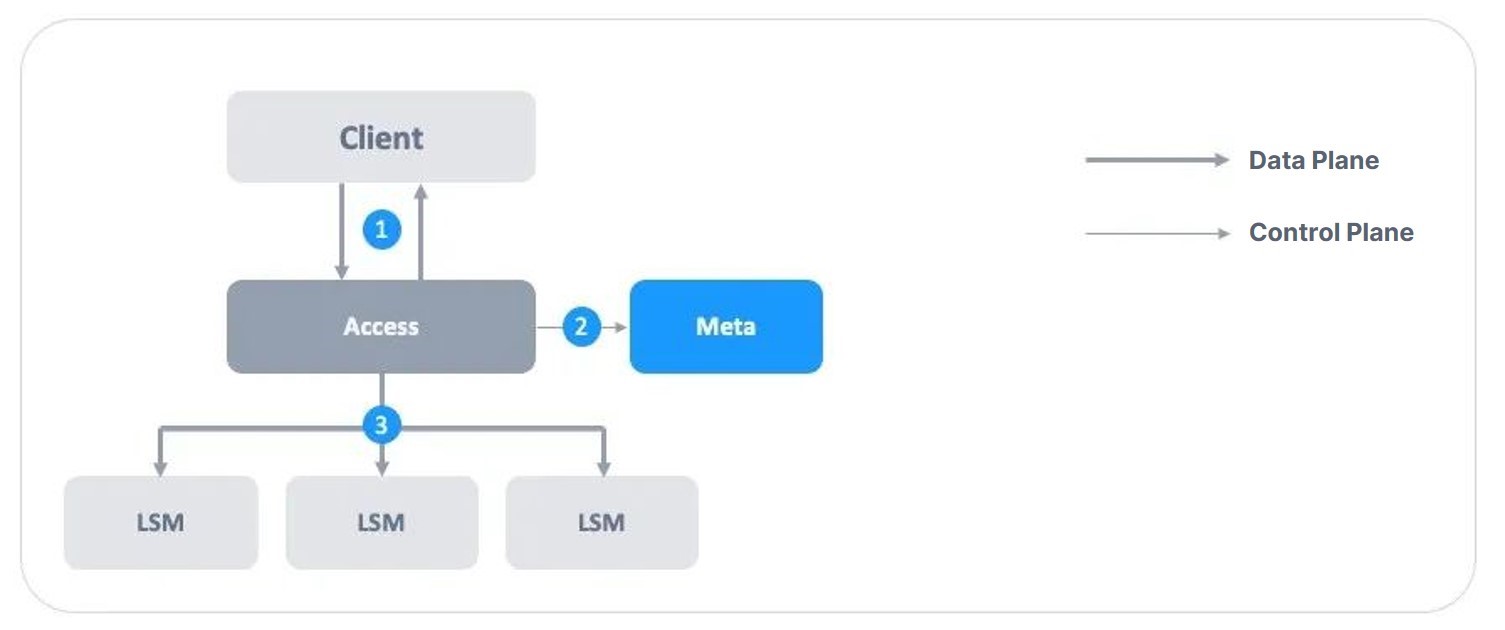
- The Client issues the I/O request. Different interaction models will be applied to different access protocols (e.g., iSCSI, NFS, vhost, and NVMe-oF). A detailed introduction will be given in subsequent articles. Then Node Access receives the I/O request.
a.If ZBS is deployed on the hyperconverged architecture and the node state is normal, I/O request is sent to local Access.
b.If ZBS is deployed on compute-storage-separated architecture, the Access of I/O access is allocated by Meta upon initial connection. - Access requests authority from Meta, and acquire the operation authorities over Extent through Lease. It also caches location information of Extent.
- Access performs I/O operations of strong consistency over the location of multiple Extents.
ZBS Performance
Over the years, ZBS’s storage performance has experienced considerable optimization. The figure below shows the storage performance of ZBS’s latest version based on different storage mediums, networks and features.
