In our previous blogs, we’ve addressed common misconceptions about hyperconverged infrastructure (HCI) in terms of its cloud-building capabilities and ability to support production workloads.
However, when it comes to long-term stability and operational control, some IT teams still have lingering doubts about whether an HCI-based platform can match the proven reliability of traditional architectures (like VMware virtualization plus centralized storage). Typical concerns include:
- Are standard x86 servers as reliable as the proprietary hardware often used in traditional architectures?
- Will a single fault cause widespread disruption in HCI?
- Are HCI products essentially “black boxes” that reduce operational transparency and leave administrators unable to monitor and maintain their systems effectively?
The truth is, as a full-stack enterprise cloud solution listed by Gartner’s HCI report, SmartX Enterprise Cloud Platform (ECP) has already helped hundreds of enterprises run critical workloads with confidence — delivering proven stability, transparent operations, and enterprise-class high availability even in the most demanding environments.
In this article, we’ll address three of the most common misconceptions about SmartX ECP when it comes to ensuring stability and system control.
Misconception #1: Based on HCI, SmartX ECP Is Too Complex to Ensure Cluster Stability
“Because HCI converges compute, storage, and networking into one system, the architecture seems more complex and tightly coupled, with more components to go wrong.”
This concern stems from the perception that distributed, software-defined architectures are more sensitive to hardware faults and network instability. Many worry that high storage utilization or unstable hardware could compromise overall cluster performance, or that the technology is still too immature to ensure long-term stability in production environments.
✅ SmartX ECP: Proven Stability Even at Scale
SmartX ECP is designed to maintain stable performance and availability even under high load and adverse conditions, thanks to rigorous design, mature technology, and advanced fault detection and isolation.
- Proven in Production: With nearly 400 financial services customers, more than 90% of whom run production and mission-critical workloads on SmartX ECP, single-customer clusters have been operating stably for over seven years. Benchmark tests show that even under 12 hours of sustained high I/O pressure, performance remains consistent (Figure 1). Similarly, clusters with storage utilization above 80% continue to deliver predictable, high-level performance (Figure 2).
- Network Health Detection and Isolation: The system continuously monitors NICs and node-level networking, raising alarms and isolating abnormal components proactively or on-demand, minimizing impact to cluster services.
- Disk Health Detection and Isolation: To mitigate the impact of failed or degraded disks on the cluster, SMTX OS employs both active and passive monitoring to detect abnormal disks and automatically isolate them, ensuring disk issues do not compromise cluster stability.
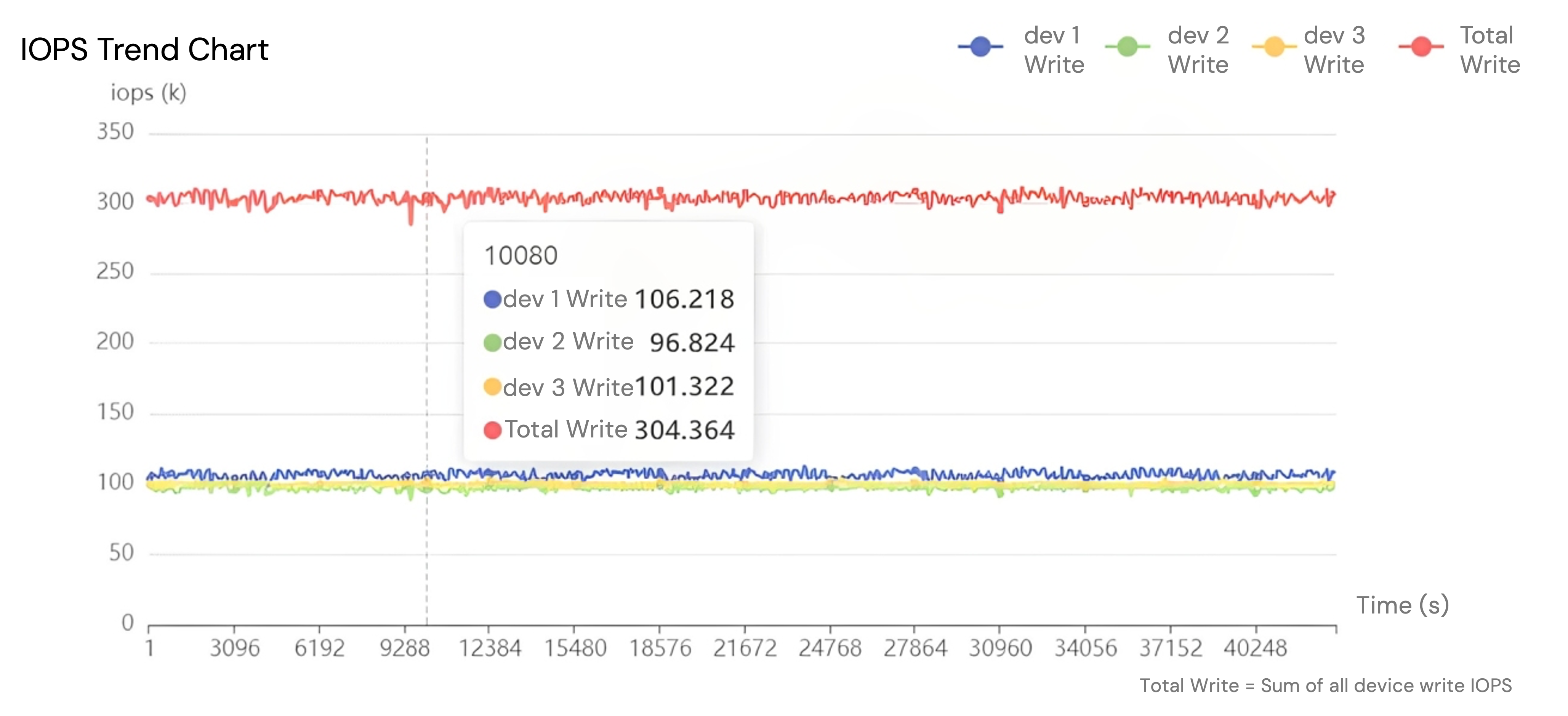
The chart above shows a performance stress test of a three-node cluster. The curves for dev1, dev2, and dev3 represent the performance of each node, while the red curve represents the overall cluster performance. Smaller fluctuations in the curves indicate more stable cluster performance.
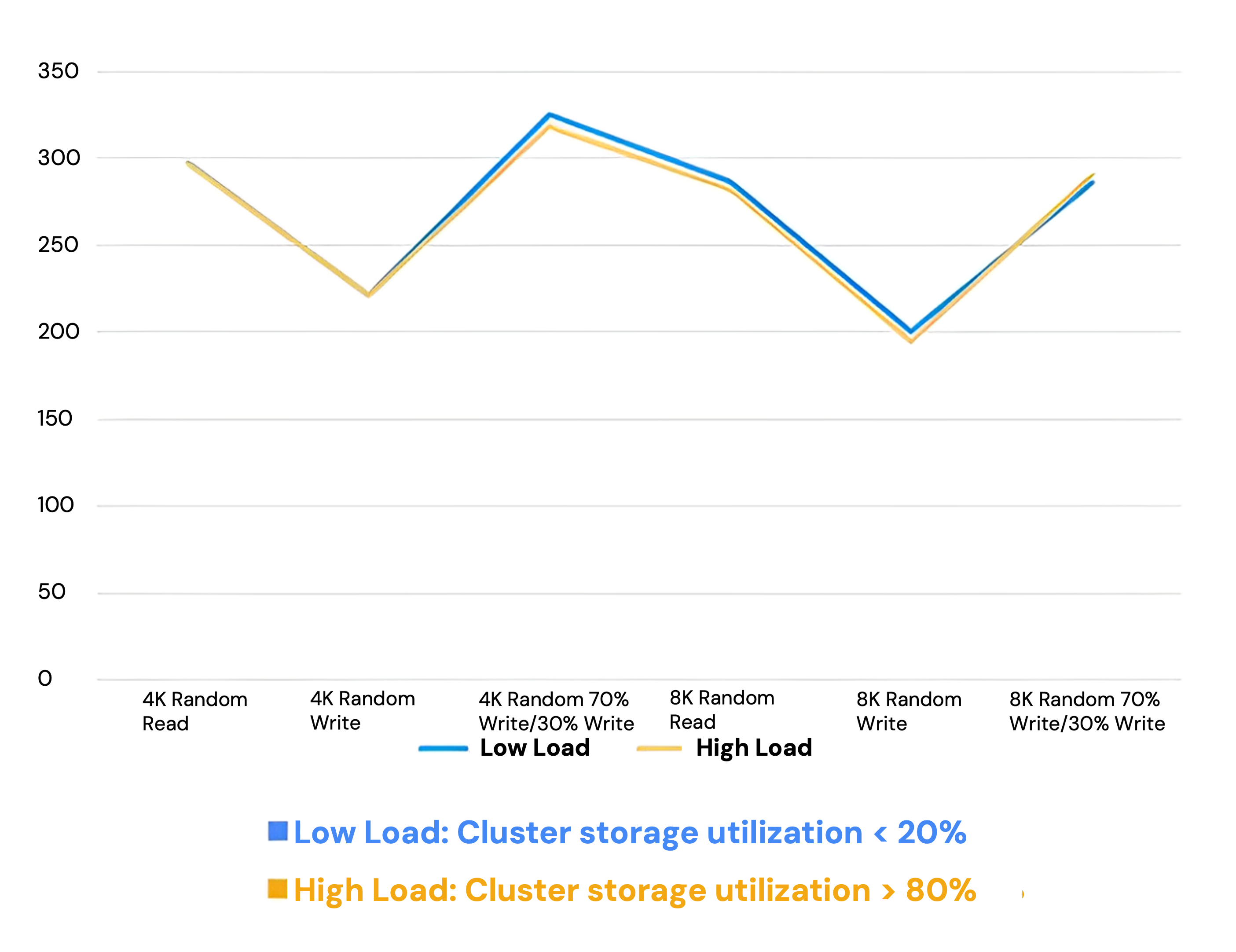
Misconception #2: HCI Can’t Guarantee Stability Under Failure Scenarios
“We know how traditional architectures behave under failure scenarios, but what happens to HCI when things go wrong? Will data and performance hold up?”
✅ SmartX ECP: Transparent, Automated Fault Handling
SmartX ECP empowers built-in distributed storage with advanced HA and data protection features, keeping failures contained and recovery automated.
Core competence
- VM High Availability (HA): In the event of node, storage network, or VM failure, affected VMs are automatically restarted on healthy nodes, ensuring business continuity.
- Dynamic Resource Scheduling (DRS): Continuously monitors CPU, memory, and storage usage across VMs. When it detects resource imbalance, it generates migration recommendations and can automatically or manually move VMs to maintain optimal cluster resource distribution.
Performance Under Various Failure Scenarios
(1) Disk Failures:
- Tiered Mode: A data disk failure does not impact performance; a cache disk failure may cause a brief performance dip, which stabilizes shortly after.
- Non-Tiered Mode: Disk failures may result in a short-term performance fluctuation before returning to normal.
(2) Network Failures:
- Management Network: A complete failure of the management network does not disrupt business operations.
- Storage Network: A single-link failure has no impact; a complete failure triggers data recovery and VM HA migration.
- Business Network: A single-link failure has no impact; a complete failure triggers live VM migration within approximately 60 seconds.
Intelligent Data Recovery
When data recovery is triggered, SmartX ECP dynamically adjusts the recovery speed based on the current business workload — accelerating recovery during low-load periods while prioritizing business performance during high-load periods.
Unexpected Power Outage
In the event of a complete power loss, the cluster automatically recovers when power is restored, with VMs restarting automatically to resume operations.
These features make failures predictable, localized, and manageable.
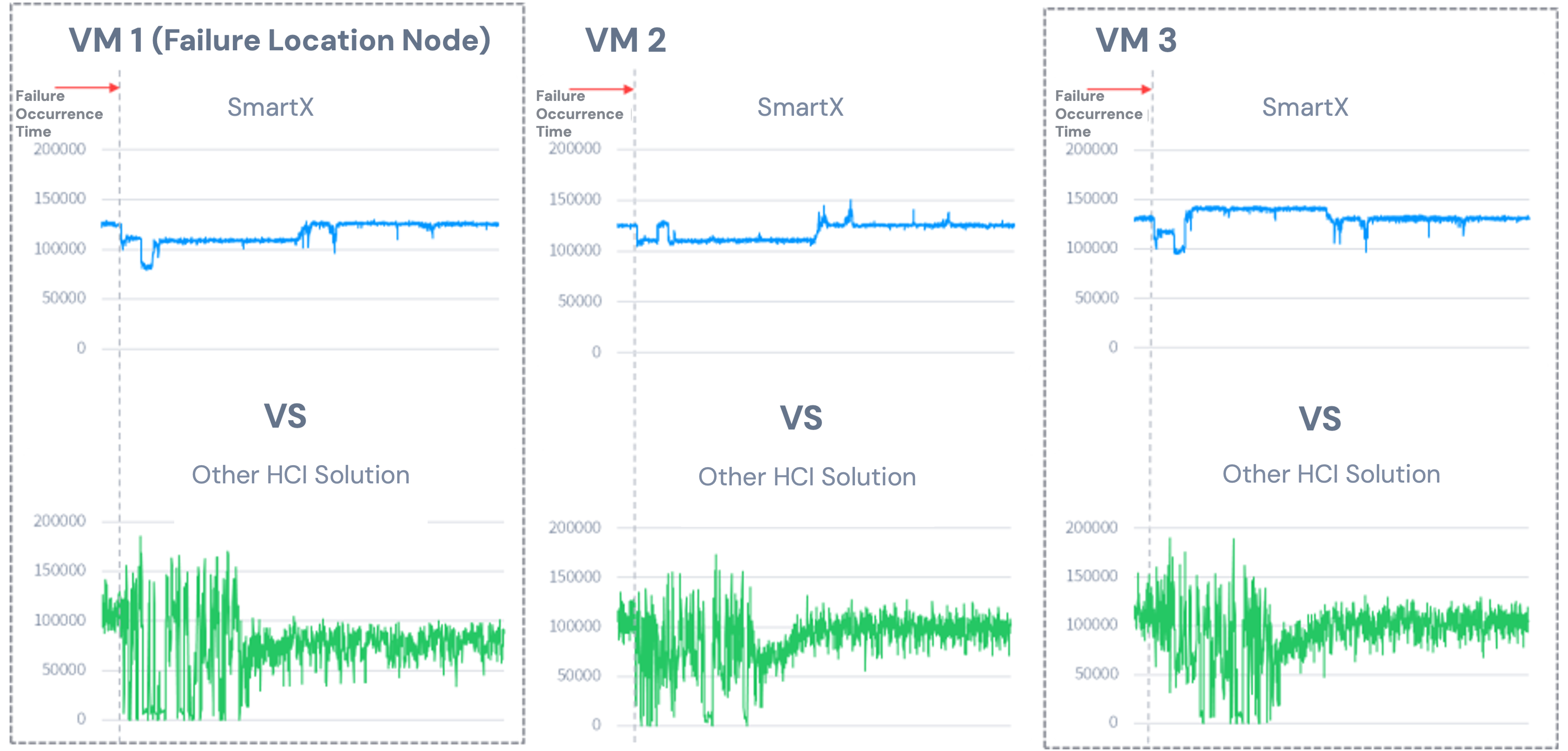
Data sampling window: 90 seconds before failure, total duration of 31 minutes. Smaller performance fluctuations and higher recovery ratio indicate better performance stability under failure scenarios.
Misconception #3: SmartX ECP Is a “Black Box” With Little Operational Visibility or Control
“Unlike traditional architectures where compute, storage, and networking are separate and easy to troubleshoot, HCI seems tightly coupled and vendor-dependent. Will operations feel like walking a tightrope?”
In traditional architectures, storage, networking, and servers are maintained separately, making issues easier to isolate. HCI, however, can span multiple layers when faults occur, often requiring vendor support and leaving users feeling less in control. This may lead to concerns about SmartX ECP, such as:
- Complex upgrades that disrupt business performance.
- Lack of holistic fault diagnosis.
- Insufficient monitoring granularity.
- Inability to integrate third-party monitoring tools.
- No unified documentation portal.
- Risks from vendors relying on open-source storage frameworks like Ceph or GlusterFS, which they can’t fully control.
✅ SmartX ECP: Transparent, Intelligent, and Controllable Operations
SmartX ECP addresses these challenges with a combination of “decoupled architecture, intelligent operations, and unified management,” giving enterprises both simplicity and autonomy:
- Decoupled architecture for better control: Even though compute, storage, and network are converged under the hood, SmartX ECP maintains logical separation in design. Users can independently monitor and manage each layer — nodes, networks, VMs, and storage — with clear status and logs, making it easy to locate and resolve issues.
- Intelligent operations to enhance autonomy: ECP provides automated monitoring across disks, networks, and hosts, detecting potential problems early. The CloudTower (management platform) provides inspection and upgrade centers, simplifying ongoing maintenance and reducing risk during upgrades.
- Unified management with full visibility: CloudTower offers a single, panoramic view across clusters and regions, enabling centralized monitoring and management of all HCI resources — compute, storage, network, and virtualization. This eliminates data silos and improves operational efficiency.
- Open APIs and robust documentation: SmartX provides extensive APIs to integrate with third-party monitoring tools such as Prometheus and Zabbix, ensuring that enterprises can extend their monitoring capabilities. A centralized documentation portal offers quick access to all necessary technical resources.
- Fully self-developed core technologies: Unlike many domestic HCI solutions that build on open-source distributed storage frameworks (e.g., Ceph, GlusterFS), SmartX’s distributed storage is designed and developed entirely in-house, giving full control over its codebase and enabling fast issue resolution.
Emphasis on optimizing self-developed technologies: Similarly, SmartX’s ELF virtualization is based on KVM but includes deep, proprietary optimizations such as Boost mode and NUMA-aware scheduling, contributing back to the open-source ecosystem while ensuring enterprise-grade stability and performance.
Build a Stable, Reliable Cloud With Confidence
The idea that HCI is inherently unstable is outdated. SmartX ECP proves that hyperconverged platforms can deliver enterprise-grade stability, reliability, and operational autonomy — even in high-pressure, mission-critical environments. With built-in HA, intelligent recovery, proven long-term stability, and transparent operations, SmartX ECP helps enterprises confidently modernize their infrastructure without sacrificing control or peace of mind.