Author: Ruichuan Chen, Solution Engineer, SmartX FSI Team
In 1987, Tsugio Makimoto, the Chief Engineer at Hitachi, proposed “Makimoto’s Wave.” This concept suggests that chip development cyclically alternates between “general-purpose hardware” and “specialized hardware” roughly every ten years. Over the past decade, general-purpose servers and software-defined solutions have dominated the market. It was against this backdrop that Hyperconverged Infrastructure (HCI) emerged, providing efficient, convenient, and cost-effective infrastructure solutions.
However, as Moore’s Law slows down, the performance growth of general-purpose hardware has hit a bottleneck. Consequently, specialized hardware has once again become a crucial means to boost system performance—a trend clearly reflected in the demand for “ultra-low latency” specialized Network Interface Cards (NICs).
To further optimize performance in virtualized environments, SmartX ECP (based on HCI architecture) has introduced support for various specialized hardware technologies. At the networking layer, by leveraging SR-IOV and PCI passthrough technologies, virtual machines (VMs) can directly access kernel bypass NICs, achieving high-speed, low-latency network transmission.
This article will briefly outline the background behind the birth of kernel bypass NICs, explain how HCI architecture supports them, and showcase their real-world performance on HCI – with network latency down to 2–3 us on SmartX ECP + Solarflare low-latency NICs.
Why Do We Need Kernel Bypass NICs?
Limitations of Traditional TCP/IP Networking
In the vast majority of modern computer systems, network communication relies on a mature and general-purpose architecture—the operating system kernel protocol stack.
When an application needs to send or receive data, the data packets must traverse this “standard path”: it first arrives at the NIC, notifies the CPU via a hardware interrupt, and is then sent into the kernel space; after undergoing complex processing by the TCP/IP protocol stack, including packet validation, sequencing, congestion control, etc., it must ultimately cross the boundary between user and kernel space, getting delivered to the application through a memory copy.
While this path is stable and reliable, its original design was for generality and compatibility, rather than extreme performance. Its bottlenecks lie in frequent context switching (switching back and forth between user mode and kernel mode), multiple memory copies, and heavy kernel processing overhead. These operations consume a massive number of CPU clock cycles and introduce non-negligible latency, making the response time of network communication usually stagnate at the millisecond level.
For ordinary applications such as web browsing or file transfers, this overhead is harmless. However, in cutting-edge fields like high-frequency trading (HFT), real-time financial market data, and high-performance computing (HPC), every single microsecond increase in network latency could mean huge losses. It is precisely these inherent flaws of the traditional TCP/IP network that catalyzed kernel bypass technology.
Kernel Bypass: Eliminating Kernel Stack Overhead for Drastic Latency Reduction
The root cause of high latency in traditional networking is the excessive involvement of the OS kernel in the network transmission. Kernel bypass technology addresses this by constructing a “high-speed expressway” directly from the NIC to the user-space application, effectively circumventing the bottlenecks of the kernel protocol stack.

Core Features
- User-Space Lightweight Drivers: Drivers are implemented in user space to manage the NIC directly. Applications can efficiently send and receive data via memory mapping (mmap).
- Zero-Copy DMA: Utilizing the NIC’s Direct Memory Access (DMA) capabilities, data is read from and written directly to a pre-allocated memory pool in user space. This eliminates the data-shuffling overhead between kernel and user space.
- Poll-Mode Drivers: High-efficiency polling replaces interrupt-driven mechanisms. The CPU actively polls for and processes data, avoiding interrupt-induced latency and jitter.
With these three features, kernel bypass technology slashes network processing latency from milliseconds to microseconds. At the same time, it minimizes kernel-state CPU consumption during network processing, allowing more CPU cycles to be dedicated to user-space application logic, thereby guaranteeing high-performance network handling.
Kernel Bypass NICs: Avoiding Application Code Rewrites and High CPU Overhead
Although kernel bypass technology significantly optimizes network performance, it still introduces two core challenges:
- Requirement for Application Modification: Pure software-implemented kernel bypass typically requires refactoring the application’s network logic to support user-space network calls.
- High CPU Occupation: Software kernel bypass merely shifts network processing from kernel space to user space; network tasks still require substantial CPU involvement, tying up critical computing resources.
Kernel bypass NICs are hardware-software co-designed solutions that combine kernel bypass technology with hardware offloading. Currently, mainstream products on the market include AMD Solarflare’s Onload technology, Nvidia Mellanox’s VMA technology, and Cisco Exablaze’s ExaNIC Software technology. These solutions build upon kernel bypass by offloading a portion of the network functions directly onto the NIC hardware, further amplifying network capabilities.
To resolve the aforementioned challenges, kernel bypass NICs and their accompanying solutions adopt the following strategies:
- User-Space TCP/IP Stacks to Avoid Application Modification: Applications can continue using standard Socket APIs without altering a single line of existing code. Network offloading components on the OS side transparently intercept the traffic.
- Hardware Offloading: The CPU only manages the control plane, while the NIC hardware handles the data plane. This drastically minimizes CPU involvement during network I/O processes.
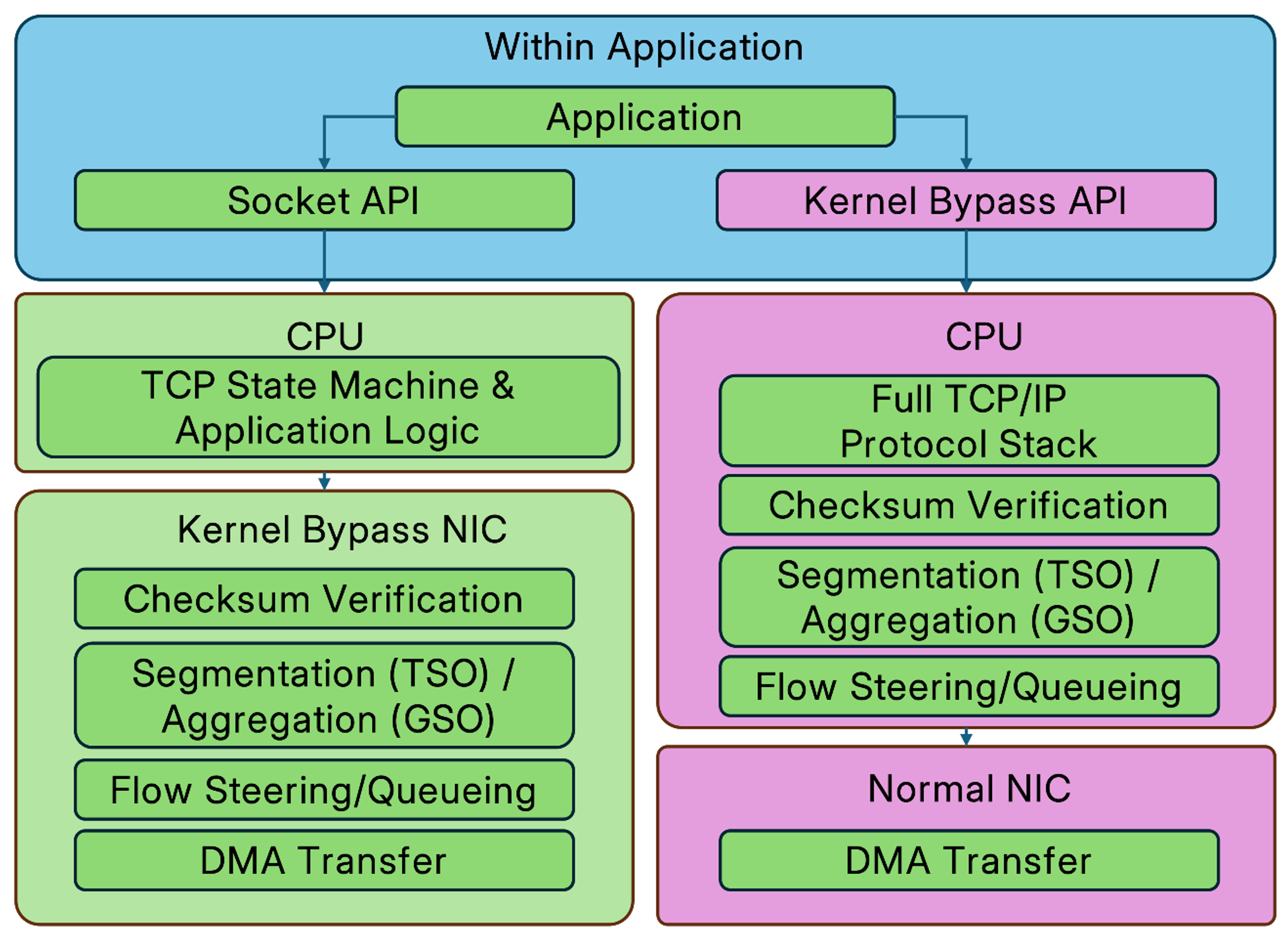
The aforementioned improvements enhance the utility of kernel bypass technology. By means of “bypassing the kernel, zero-copy, reducing context switching, and hardware offloading,” kernel bypass NICs minimize microsecond-level latency and jitter, making them the ideal technical solution for low-latency application scenarios.
Performance of Kernel Bypass NICs on HCI: 2–3 us Latency with SmartX ECP
How HCI Supports Kernel Bypass NICs
In industries like futures and securities, some clients execute quantitative trading through customized trading strategies. Among these, HFT is extremely sensitive to market fluctuations, where millisecond or even microsecond delays can significantly impact trading returns. To address these scenarios, the industry typically adopts solutions like Solarflare’s kernel bypass NICs to drive down network latency.
In traditional deployment models, these NICs are usually installed in bare-metal physical servers, with independent NICs dedicated to each server, significantly increasing hardware costs. The introduction of virtualization technology can effectively reduce hardware investments and achieve more flexible resource utilization.
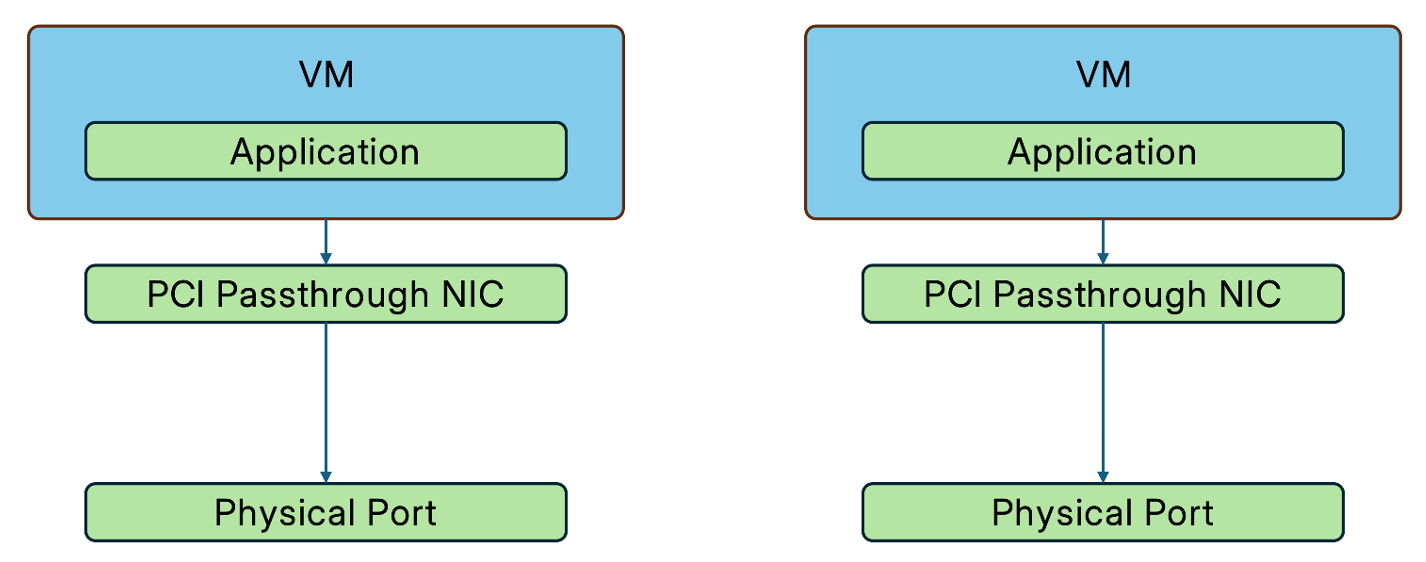
However, traditional virtualized networks generally use virtio or similar virtual NICs to provide network interfaces for VMs, which do not possess the high-performance attributes of Kernel Bypass NICs on physical servers. To bridge this gap, SmartX ECP supports network card passthrough, which allows both physical PCI NICs and SR-IOV NICs to be passed through directly to VMs for use.
- PCI NIC Passthrough: A physical NIC on the host is passed through directly to a VM as a PCI passthrough NIC, becoming exclusively dedicated to that specific VM.
- SR-IOV Passthrough: A single physical NIC supporting SR-IOV is virtualized into multiple VFs (Virtual Functions). These VFs are attached directly to VMs as SR-IOV passthrough NICs, allowing multiple VMs to share the communication capabilities of a single physical NIC.
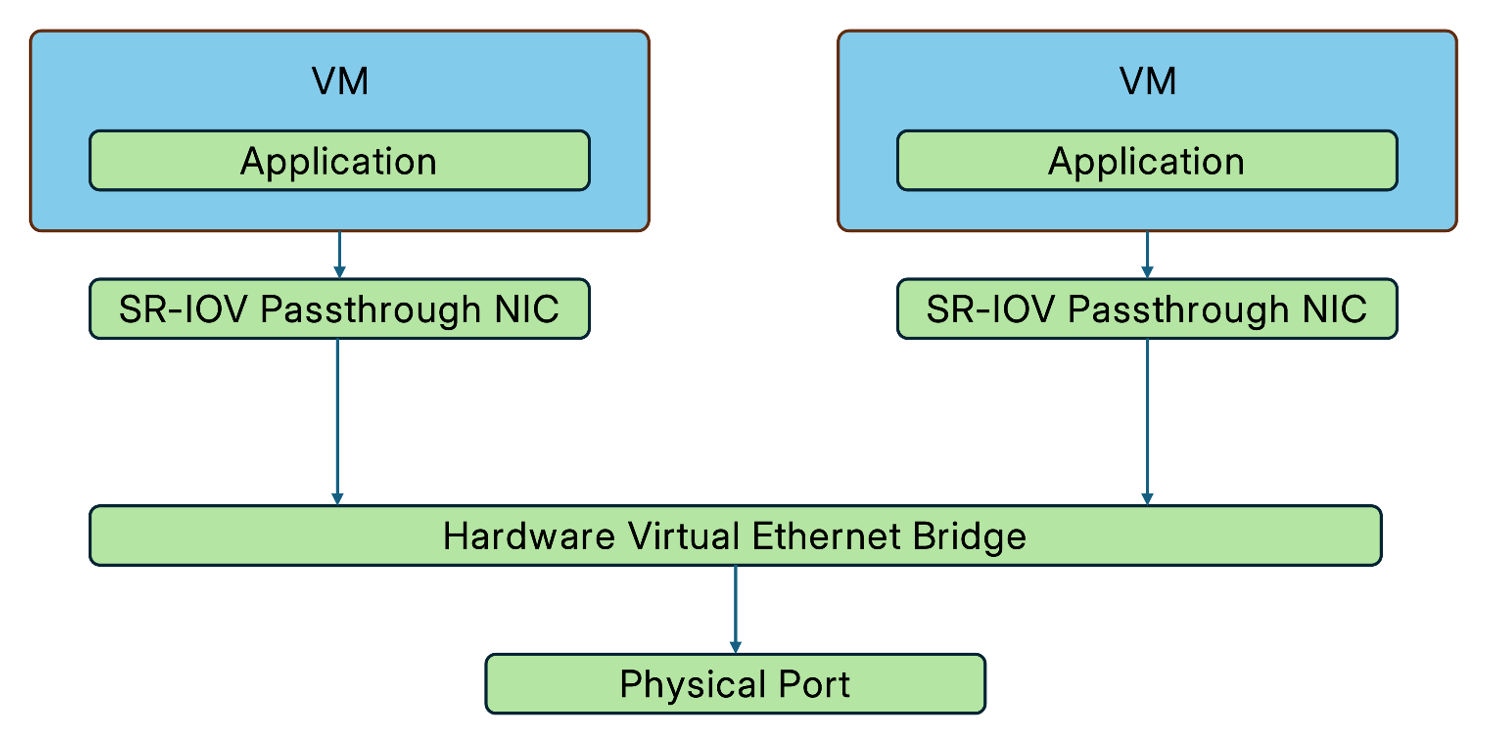
>Learn more:Network I/O Virtualization in SmartX HCI: Virtual NIC, PCI Pass-through and SR-IOV Pass-through
Network card passthrough directly maps all the features of a physical NIC into the VM, granting the VM complete access to the physical hardware. Through this feature, VMs can utilize hardware acceleration capabilities—including PTP (Precision Time Protocol) and Onload offloading—thereby meeting the rigorous demands of high-performance network scenarios such as futures trading and HPC.
Real-World Performance Validation of Kernel Bypass NICs on HCI
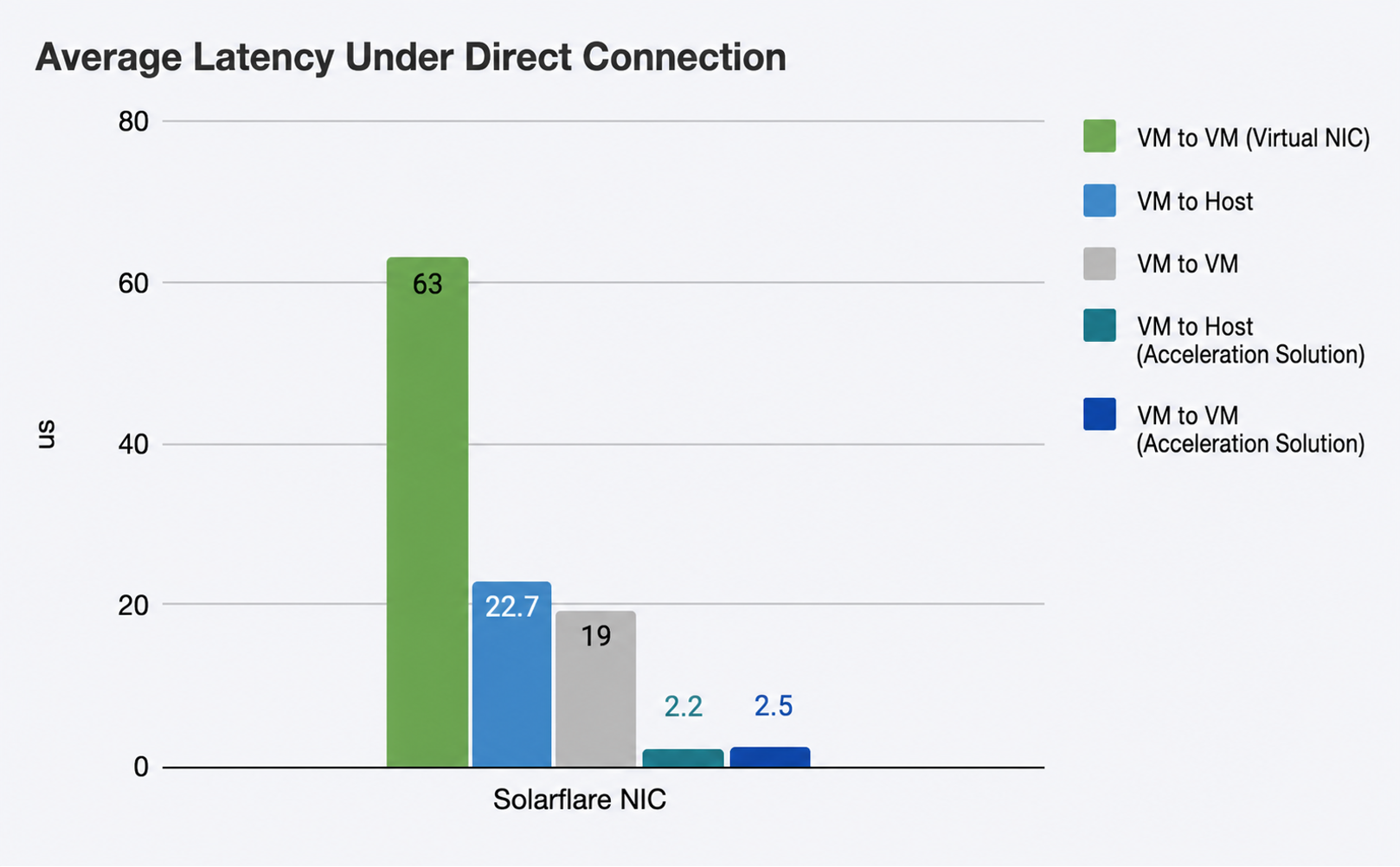
In this test case using SMTX HCI and Solarflare low-latency NICs, we utilized the sfnettest to conduct peer-to-peer latency testing, evaluating latency performance across five distinct scenarios:
- VM to VM (Virtual NIC): Two VMs are deployed across different nodes on the hyperconverged platform with virtual NICs attached. The latency results serve as the baseline value to compare the latency reductions of other solutions.
- VM to Host (SR-IOV): One VM is deployed on the hyperconverged platform with an SR-IOV NIC attached to test the latency against a physical host.
- VM to VM (SR-IOV NIC): Two VMs are deployed across different nodes on the hyperconverged platform with SR-IOV NICs attached to test the latency.
- VM to Host (Onload Acceleration): One VM is deployed on the hyperconverged platform with an SR-IOV NIC attached, while the physical server uses a physical NIC. Once the NICs are correctly recognized on both sides, the acceleration solution is enabled for latency testing.
- VM to VM (Onload Acceleration): Two VMs are deployed across different nodes on the hyperconverged platform with SR-IOV NICs attached. Once the NICs are correctly recognized, the acceleration solution is enabled for latency testing.
The test results indicate that under a direct peer-to-peer connection mode (without passing through an intermediate switch), relying solely on standard virtual NICs cannot meet the demands of low-latency applications. Conversely, employing SR-IOV passthrough NICs—even without enabling the acceleration software—dramatically reduces latency in both VM-to-VM and VM-to-Host scenarios.
When the network acceleration solution is fully enabled, the combination of Solarflare NICs and Onload acceleration further squeezes network latency down to 2–3 us across all tested scenarios.
Currently, a securities institution has successfully validated the performance of SmartX ECP + Solarflare low-latency NICs in their production environment for ultra-fast trading. By utilizing low-latency VMs to support client algorithmic trading engines, they reduced hardware costs by over 50% and slashed power consumption by approximately 50% compared to bare-metal servers. >>Learn more
Conclusion
To meet the higher requirements of modern applications on infrastructure, SmartX ECP introduces kernel bypass NICs into virtualized environments via SR-IOV and PCI NIC passthrough technologies. This achieves simultaneous breakthroughs in virtualized network performance enhancement and cost reduction, providing enterprise users with a highly practical and deployable technical solution for building high-performance, cloudified datacenters based on HCI architecture.
Appendix: Physical Host Configurations for Testing
