SmartX ECP has been providing disk health check features since the launch of SMTX OS 4.0.10. These features assist O&M engineers in detecting potential hard disk failure risks and handling failed physical disks. In our previous article, we dived into three types of hard disk health check strategies supported by SmartX ECP. With the release of SMTX OS 6.1, SmartX ECP improves its capabilities in handling hard disk failures by adding new features to identify I/O blocking and software RAID failures, further ensuring continuity and stability for critical businesses.
Management of Physical Disks with I/O Blocking
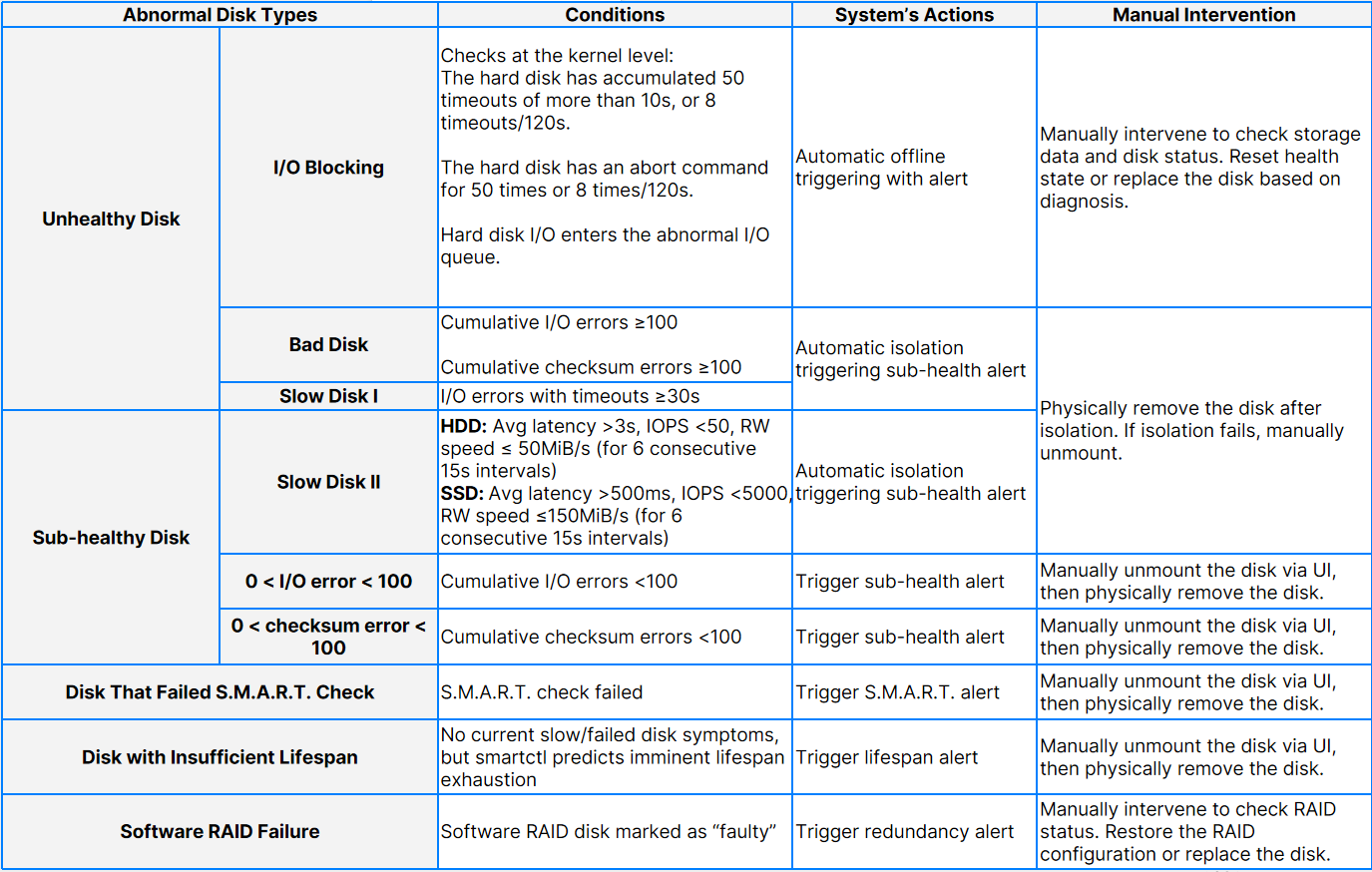
Before the SMTX OS 6.1 version, SmartX ECP checked disk health mainly through three methods: the open-source tool S.M.A.R.T., SmartX independently developed tool disk-health, and the data inspection feature of SmartX ECP clusters. These methods enable SmartX ECP to identify four types of abnormal hard disks: unhealthy disks, sub-healthy disks, disks that failed S.M.A.R.T. checks, and disks with insufficient lifespan, and then trigger corresponding alerts and/or isolation actions.
However, besides these four hard disk failure types, users might encounter node I/O blocking caused by single disk failure; the failed disk continuously generated abnormal I/O requests, causing the “eh thread” to repeatedly reset the HBA/RAID controller that manages error queues. This resulted in sustained I/O interruptions across all physical disks managed by the controller until the failed disk was manually removed.

In this regard, SMTX OS version 6.1 introduces a new strategy to identify and handle hard disks with I/O blocking.
Conditions
When the system detects any of the following conditions at the kernel level, the hard disk will be identified as I/O blocking and automatically go offline:
- The hard disk has accumulated 50 timeouts of more than 10s, or 8 timeouts/120s.
- The hard disk has an abort command for 50 times or 8 times/120s.
- Hard disk I/O enters the abnormal I/O queue.
Management
When I/O is blocked, the system will automatically offline the failed disk to halt further I/O processing. This helps to quickly solve the blocking case and restore the overall I/O of the node, shortening the time length of I/O interruption to within minutes (generally within 3 minutes).
- To ensure system and data security, only one disk is allowed to be offline at the same time in the same cluster.
- Alert: Physical disks are offline.
- Physical disk status: Abnormal disk – requires processing.
- Physical disk details: Prompt to contact SmartX after-sales engineers. Our engineers will assist in processing (check the status of storage data and physical disk, then decide to either reset the disk health status or replace it).
Management of Software RAID Failures
In addition, since SMTX OS 6.0, SmartX ECP has been able to identify and manage software RAID failures, which further facilitates O&M staff and SmartX after-sales engineers to locate the problem.
When the system disk constituting the software RAID has errors or high latency in reading and writing, it will be marked as faulty by the software RAID. At this point, the physical disk will no longer handle read/write operations for the operating system partition and metadata partition. These operations will be taken over by another physical disk in the software RAID, and an alert for insufficient redundancy in the system partition will be triggered. If the software RAID fails due to the hardware issue of the physical disk, the physical disk must be unmounted and repaired or replaced.
Performance Test of Hard Disk Failure Scenario
To help users further understand the impact of hard disk failures on the performance and stability of SmartX ECP clusters, we conducted a performance test on SmartX ECP and another HCI platform.
Test Details
- We simulated hard disk failure scenarios in the SmartX ECP cluster and the HCI cluster from vendor A, with the same hardware servers, VM configurations, and client-end operating systems.
- Started a VM on each node of a 3-node cluster and ran the FIO stress test.
- After the FIO stress test had been running for a while, removed a hard disk from one of the nodes to simulate a disk failure scenario.
- Collected FIO performance data during the entire test.
Results

- Performance fluctuation caused by hard disk failure: In the SMTX OS cluster, VMs only experienced a slight performance fluctuation, with the lowest IOPS close to 80,000 and a duration of about 2 minutes and 30 seconds. In contrast, in vendor A’s HCI cluster, all VMs experienced severe performance impact, with multiple instances’ I/O dropping to zero (I/O interruption). The severe fluctuation continued until data recovery began.
- VM performance recovery on the node with the failed hard disk: In the SMTX OS cluster, VMs’ performance became stable approximately 2 minutes after the disk failure (at 86% of the original performance), and data recovery was completed within 15 minutes, with 100% performance restored. In Vendor A’s HCI node, performance fluctuation was alleviated after about 13 minutes (with data recovery triggered at around 10 minutes), and it never fully recovered to the original performance (only 69% of the original performance).
Summary
With an all-rounded hard disk failure identification and management mechanism, SmartX ECP can quickly identify and provide emergent responses to multiple hard disk failure scenarios while ensuring minimal performance impact and fast recovery. These features further guarantee the continuity of the enterprise’s critical business services and facilitate O&M staff to locate and handle the failure quickly.