While DeepSeek’s open-source architecture offers reliable AI inference with cost advantages across business use cases, organizations addressing data-sensitive workloads face critical implementation decisions. Private deployment – essential for maintaining data security and inference accuracy – demands precise IT infrastructure evaluation that significantly diverges from using public cloud services or AI platforms.
- Enterprises need a stable environment for DeepSeek validation under business scenarios. How can they achieve this with minimal investment while establishing the environment as quickly as possible?
- Do enterprises necessarily need to deploy the DeepSeek-R1-671B model for their use cases? Can they use one IT infrastructure platform to support diverse models (with different parameters) for various business services?
- Do enterprises necessarily need to deploy DeepSeek appliances, given its high cost? Can they manage data access across departments if they share a same DeepSeek model? How to avoid the risk of single-point failures when using DeepSeek appliances?
To address these challenges, SmartX introduced a private deployment solution for DeepSeek and conducted validation in business scenarios. With SmartX ECP, enterprises can deploy DeepSeek (with various parameters) on virtual machines (VMs) or on the bare-metal Kubernetes. By simply scaling ECP clusters with GPU-deployed nodes, enterprises can build flexible and high-performance DeepSeek infrastructure and accelerate the business validation process.
This blog details the deployment solution of DeepSeek on SmartX ECP, addressing enterprises’ concerns about DeepSeek private deployment, providing hardware configuration recommendations, and sharing validation experience of using SmartX ECP to deploy DeepSeek and support an enterprise AI marketing assistant.
Run DeepSeek Privately on SmartX ECP
Overview
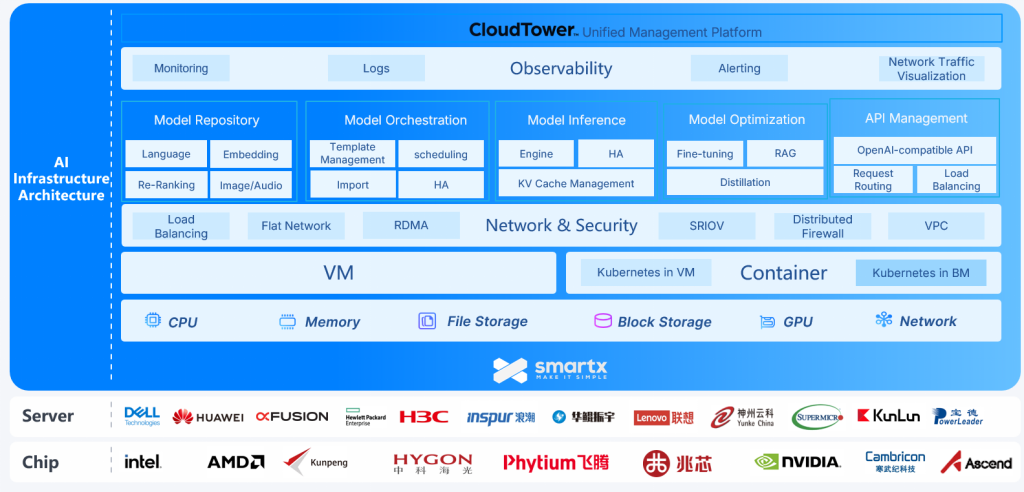
SmartX ECP enables private deployment of DeepSeek V3/R1 models (from Distill-Qwen-7B to 671B) on both VMs (based on SmartX native hypervisor ELF) and bare-metal Kubernetes (based on SMTX Kubernetes Service, SKS). We provide DeepSeek applications with full-stack infrastructure resources, including compute, storage, networking, network security, container management, and cluster management, helping enterprises run both LLMs and other business applications on a unified enterprise cloud platform to reduce costs and simplify operations.
Features
- Extensive Hardware Compatibility: Support multiple CPUs. Support NVIDIA, Cambricon and Ascend GPUs. Support a broad selection of x86 and ARM servers.
- Full-Stack Software Capabilities: Deliver complete infrastructure resources via a unified stack.
- Compute convergence: Support NVIDIA GPU passthrough and vGPU features, along with Cambricon and Ascend GPU passthrough features, enabling flexible scheduling of CPU and GPU resources.
- Storage convergence: Powerful distributed storage offers high-performance and reliable storage service. For instance, SMTX File Storage (SFS) serves to support model repositories, inference engines, and vector databases, while ZBS provides block storage services for AI applications like Dify components (Redis/PG).
- Workload convergence: SKS provides unified management of virtualized and containerized workloads, allowing enterprises to deploy Kubernetes on VMs or bare metal to meet varied AI application needs. Everoute delivers software-defined network and security features, including distributed firewall, load balancing, and VPC, while ensuring interconnection between virtualization and container environments.
- Model convergence: AI Training and Inference Platform (scheduled to release in Q2), supports private deployment and full lifecycle management of mainstream models:
- Model hosting: Cover LLMs (general & inference), Embedding, Rerank, etc.
- Model orchestration: Compatible with mainstream inference engines such as vLLM, SGLang, and Llama.cpp.
- Model optimization: Support fine-tuning and RAG (Retrieval-Augmented Generation) technologies.
- API management: Provide unified API access and management capabilities.
- Unified Management Platform: CloudTower allows a unified management of virtualization and container environments in multiple data centers, as well as their infrastructure resources, simplifying O&M.
- Rapid Deployment: SKS integrates NVIDIA GPU Operator to automate CUDA driver, Container Toolkit, and container runtime configuration, enhancing deployment efficiency with minimal manual work.
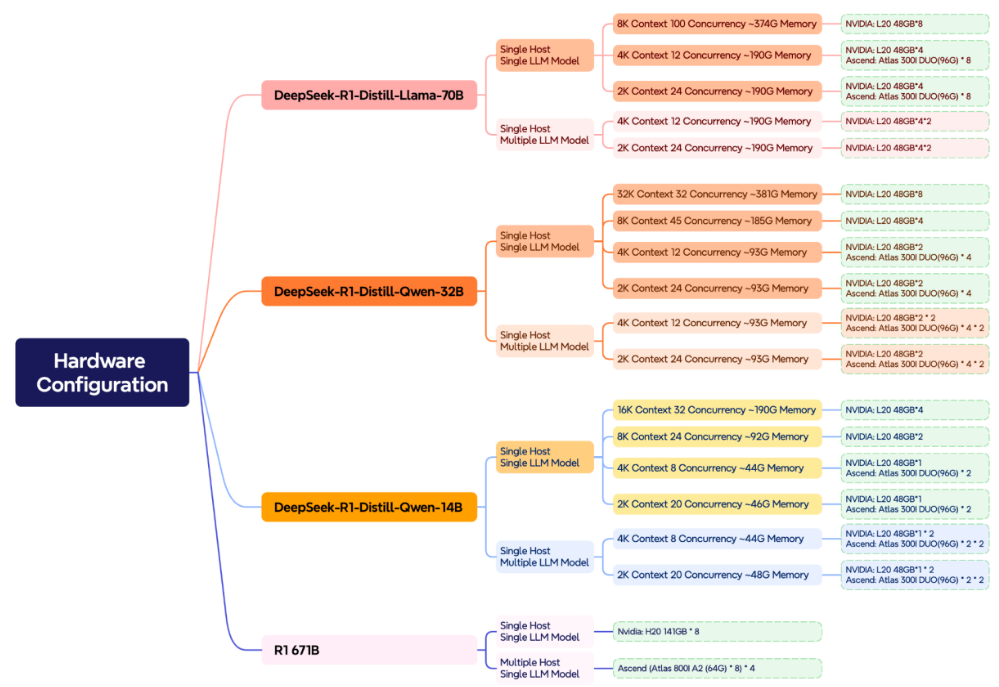
Hardware Configurations
Users can select suitable GPU cards based on model parameters, use cases, context length, and concurrency. Please refer to the chart below for configuring recommendations.
Deploy DeepSeek on VMs
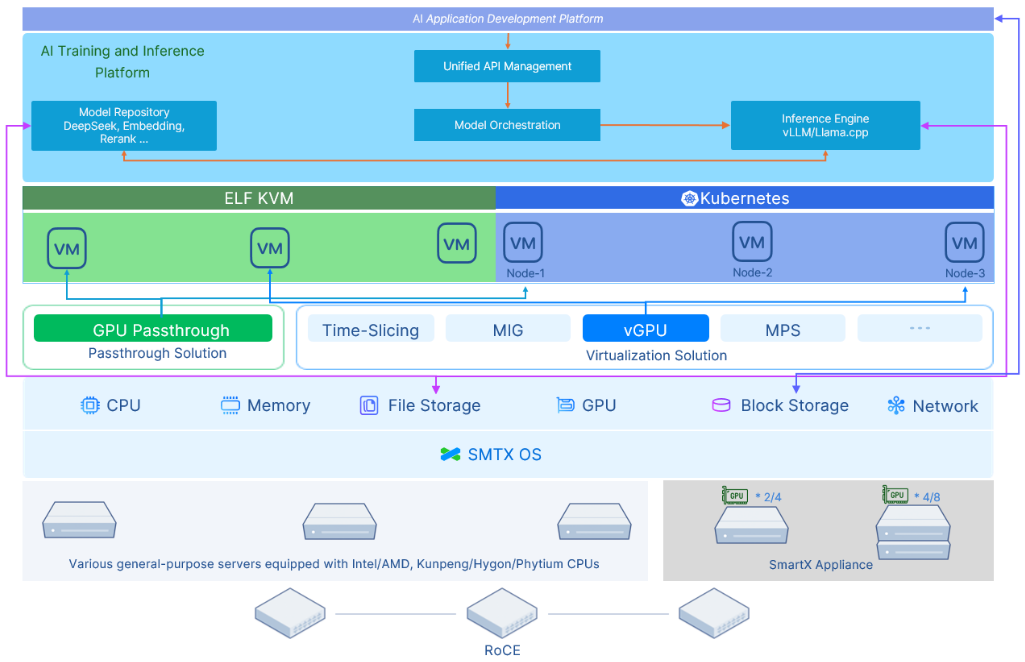
Users only need to add one host to the existing ECP cluster for DeepSeek deployment. SmartX ECP provides unified infrastructure resources and management for AI workloads running on both VMs and containers. Through GPU sharing, SmartX ECP allows users to deploy multiple independent models for various use cases.
Advantages
- Flexible Architecture: Support virtualized and containerized AI workloads. Support multiple model deployment. Support on-demand scaling.
- Reliability and Availability: Feature enterprise-grade HA capabilities and distributed architecture, eliminating the risk of single-point failures. Support the deployment of multiple models with the same size to ensure high availability of LLM models.
- Balanced Resource Allocation: ELF’s DRS feature enables the dynamic scheduling of VM/container nodes for balanced cluster resource usage.
- Extended Scenarios: Given SmartX ECP’s RoCE and SR-IOV support, users can explore distributed inference and deploy larger models.
Deploy DeepSeek on Bare-Metal Kubernetes
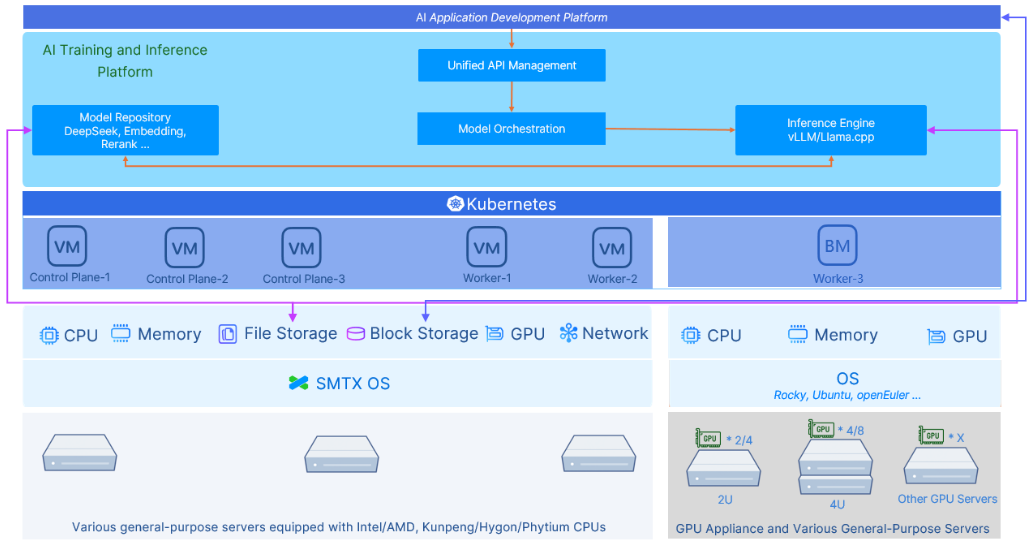
Given SKS’ unified management capability of VM-based Kubernetes and bare-metal-based Kubernetes clusters, users only need to add a physical server as the Worker node to the existing ECP cluster for DeepSeek deployment, achieving unified management with VM clusters. With this solution, users can deploy more types of DeepSeek models, including the 671B model.
Advantages
- Dual Environment Support: Users can deploy model orchestration, repositories, and non-GPU-relied AI applications on VM-based Kubernetes worker nodes to optimize resource utility.
- High Performance: Eliminate virtualization layer (CPU/Memory) overhead, offering a 10%-20% higher performance than virtualized Kubernetes clusters for complex models. (With GPU passthrough feature, Kubernetes on VMs can achieve bare-metal-level performance.)
- Low Hardware Requirements: Minimum HDD/SSD or NIC configuration is not required.
- Minimized Fault Impact: Physical nodes exclusively run AI workloads, isolating failures from other components.
Deployment Recommendations
After selecting GPUs according to the LLM model (refer to the chart above), users should decide where to deploy DeepSeek models (please refer to the chart below).
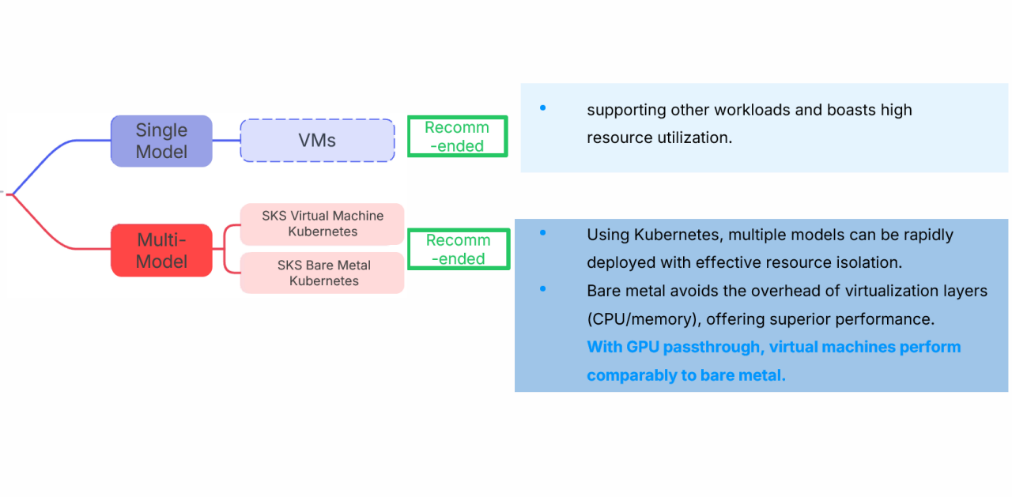
We suggest starting with a minimal investment to fast-track a validation environment. Expanding resources only after the model meets accuracy goals. Also, the full-scale DeepSeek-R1-671B model is not always necessary—it requires a high investment but with uncertain ROI, while 70B or even 32B can suffice for most enterprise use cases (The 32B model outperforms 70B in Chinese processing tasks—see details below).
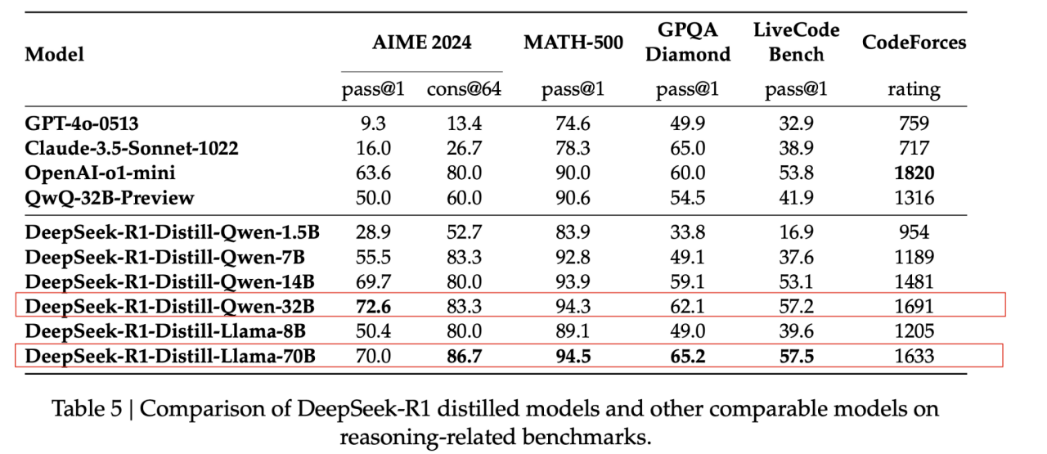
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Validation: Supporting AI Assistant with SmartX ECP
For enterprise marketing campaigns, deploying AI agents on digital platforms enables 24/7 customer service. By integrating enterprise knowledge bases, these AI agents can deliver more accurate and relevant responses while reducing service costs. We deployed DeepSeek-R1-Distill-Qwen-14B and 32B models on SmartX ECP (on VMs) and used Dify to build the entire AI agent workflow. The architecture is shown below.
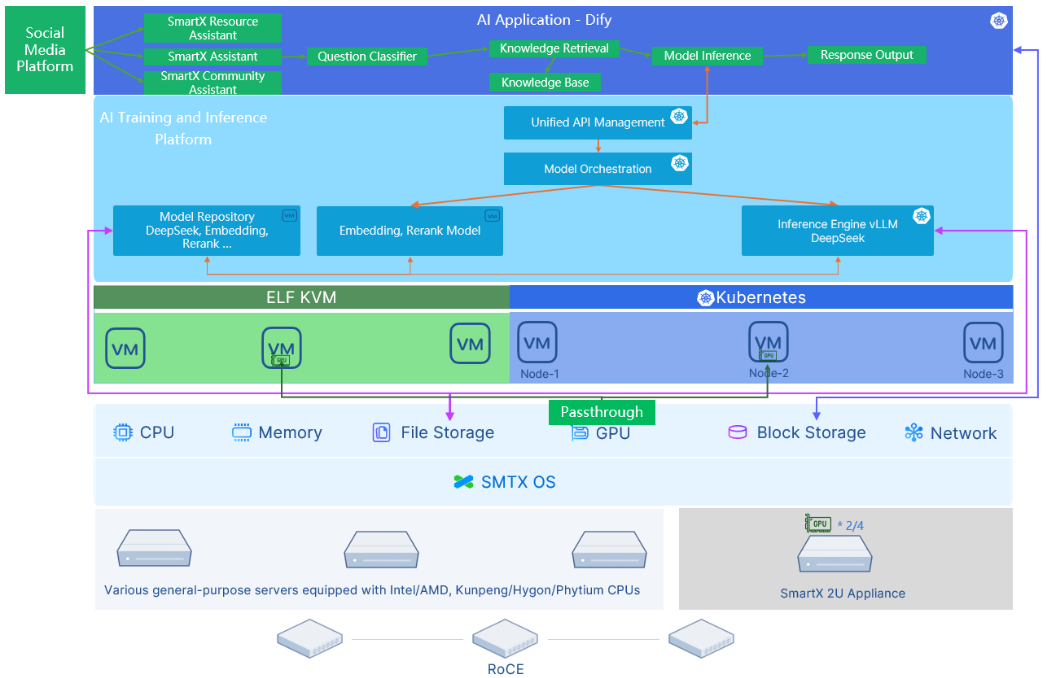
Validation
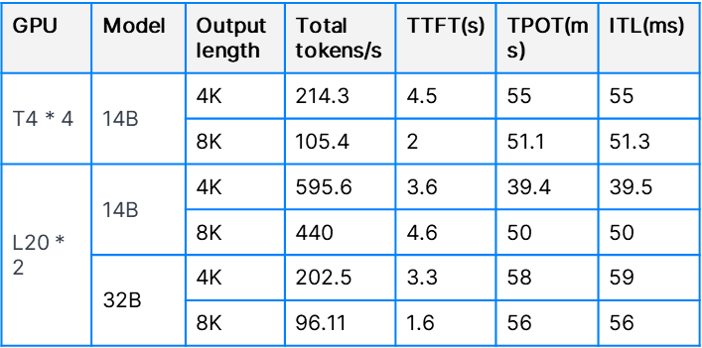
We tested the DeepSeek-R1-Distill-Qwen-14B (BF16) and 32B (BF16) models on SmartX ECP using NVIDIA T4 and L20 GPUs, evaluating their performance in AI customer service by measuring response accuracy, token usage, and response time.
Test Environment
We built a three-node SmartX ECP cluster and deployed DeepSeek models on VMs (32 vCPUs, 64GB RAM). Four NVIDIA T4 and two NVIDIA L20 GPUs were configured respectively to support 14B and 32B models via GPU passthrough. vLLM framework was used for model inference.
Test Results
Performance Comparison
With an input length of 1K, 14B and 32B models showed the following performance.
Use Case Validation
Based on SmartX ECP, the DeepSeek-R1-Distill-Qwen-14B/32B models were deployed to perform an AI customer service assistant and showed the following results:
- 14B Model (after workflow optimization): 90% valid outputs, avg 2,669 tokens/26.3s per request.
- 32B Model (after workflow optimization): 95% valid outputs, avg 2,611 tokens/27.1s per request.
The 32B model delivers higher output quality than the 14B while maintaining similar response speed. In general, with manual optimization, using SmartX ECP to support DeepSeek-R1-32B can satisfy the basic demands of providing AI customer services. Further optimizing workflows and knowledge bases will improve the AI agent’s efficiency and quality.
Comparison with Public Cloud Solutions
We also compared the performance and output quality between DeepSeek-R1-671B deployed on the public cloud (Coze) and DeepSeek-R1-14B/32B deployed on SmartX ECP in this use case. The hardware configurations are consistent with that above.
Test Results

The results showed that the privately deployed DeepSeek models have achieved 90-95% accuracy of the 671B model deployed on the public cloud, with comparable or even faster generation speed, fulfilling users’ core business demands.
Benefits
- Increased Service Availability: Providing 24/7 automated customer services, improving customer satisfaction while reducing reliance on human agents.
- Enhanced Response Precision: LLM can rapidly retrieve knowledge bases and provide accurate outputs, increasing service efficiency and consistency.
- Optimized Resource Utilization: AI-driven knowledge classification and indexing enhance resource accessibility and utilization.
Learn more about SmartX ECP and contact us for AI solution details.