Enterprises frequently face challenges when deploying AI models in private environments, often due to the unfamiliar concepts introduced by AI technologies. To assist organizations in speeding up AI model deployments and ensuring long-term success, this blog will explore ten essential concepts related to AI model deployment. These include AI infrastructure, inference engines, AI training frameworks, model registries, AI engineering, ModelOps, MLOps, LLMOps, MaaS, and AI agents.
AI Infrastructure
AI infrastructure consists of both hardware and software layers, which are the IT infrastructure services required for the deployment and operation of AI systems. Like a “foundation,” they provide solid support for the operation of AI models and applications.
Hardware Stack
This includes physical servers and necessary components, such as computing hardware (GPU, CPU, FPGA, etc.), storage hardware (e.g., high-speed SSD/HDD), and network hardware (high-speed NIC, switches, routers, etc.).
Some vendors have launched all-in-one appliances specifically designed for GenAI, offering pre-installed GPUs and AI models. However, these machines can cost millions, making them less suitable for enterprises with limited budgets or those conducting small-scale deployments for initial validation.
Software Stack
This includes the operating system and software that optimizes hardware resource scheduling, especially for the computing and storage layers.
- Computing Layer: Enterprises can choose to use virtual machines or Kubernetes as the primary environment for running AI models. VMs have a mature operational management system and higher model compatibility. This is because, currently, some models’ fine-tuning and inference stages are not yet fully containerized, making VMs more suitable in terms of dependencies, drivers, and environment adaptation. On the other hand, Kubernetes is better suited for containerized tasks, offering better scalability and fault recovery capabilities. Therefore, the hybrid use of VMs and Kubernetes has become the mainstream solution for enterprises running various AI workloads.
- Storage Layer: Since the storage requirements vary at different stages of the AI workflow, it is recommended that enterprises choose software-defined high-performance distributed storage solutions. Specific criteria include support for diverse data types, flexible deployment capabilities, data management, scalability, performance, Kubernetes support, and cost-effectiveness.
AI Frameworks and Inference Engines
Besides AI infrastructure, to successfully train and run AI models, enterprises also need to deploy AI frameworks and inference engines.
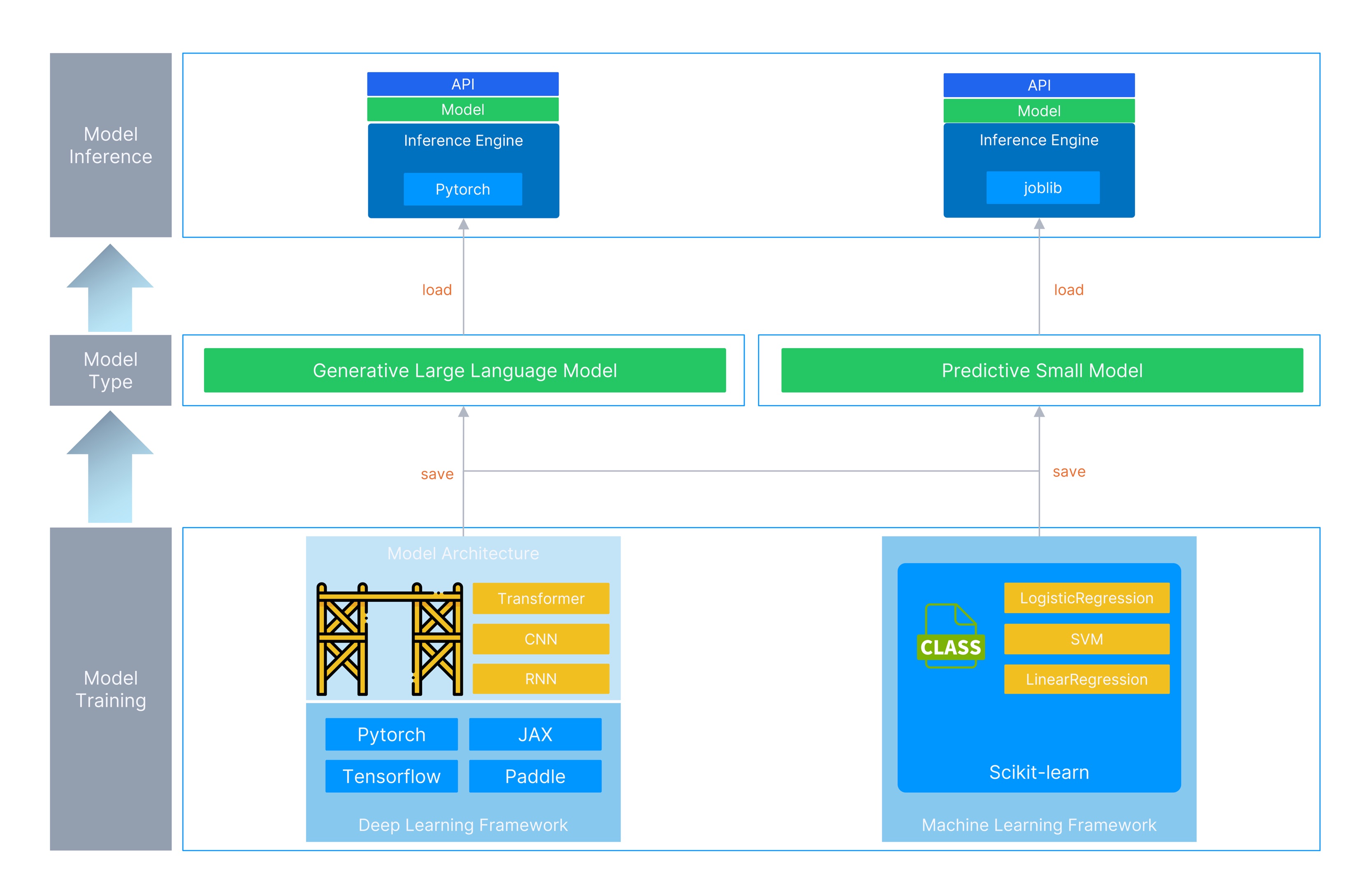
The core task of an AI model is to learn patterns from vast amounts of data to complete specific prediction or generation tasks; the former stage is “model training,” and the latter is “model running.” During model training, engineers typically prepare training data (training and test sets), and the AI framework calls the data to complete the model’s training. Once the model is trained, engineers distribute the model and run it via an inference engine. Users then invoke the model through an API to complete specific tasks.
| For example: – Game developers complete the development of a game (model) through various tools (AI frameworks). – The game developer “burns” the developed game onto a cartridge or releases a digital version of the game on a platform (trained model). – Players use a compatible console (inference engine) to play the game (use the model). |
For different models, the AI frameworks and inference engines used vary.
Predictive Small Models
These models have fewer parameters and shallower layers. In solving classification problems such as spam detection, multivariate classification models such as Logistic Regression can be used to achieve prediction tasks. During training, the Scikit-learn (sklearn) machine learning framework in Python is typically used to quickly call the implemented logistic regression model, and training is completed through the fit method.
| – Scikit-learn: A library specifically designed for machine learning; like os or math, it is one of the standard tools in the Python ecosystem. – LogisticRegression: In sklearn, it can be called both a “model” and an “algorithm”; at the code level, it is represented as a class (LogisticRegression). * eg: from sklearn.linear_model import LogisticRegression |
Once the model is trained, it is typically saved in formats such as joblib or pkl and loaded and run via an inference engine. At this stage, the inference engine is primarily responsible for reading and loading the trained model file, providing a model prediction API interface, calling the model object’s predict method for prediction, and returning the prediction results to the user.
Generative Large Models
These models have more parameters and deeper layers, offering stronger expressive capabilities and higher accuracy. In solving problems such as text generation and summarization, architectures such as CNN, RNN, and Transformer can be used. During the training, generative models can be implemented based on different model architectures (CNN, RNN, and Transformer) with the help of deep learning frameworks such as PyTorch, TensorFlow, and JAX.
| – PyTorch: A library specifically designed for deep learning; like os or math, it is one of the standard tools in the Python ecosystem. – Transformer: Unlike the LogisticRegression mentioned above, Transformer is not a pre-implemented model but a framework for implementing a model, similar to scaffolding; a high-performance model can be implemented according to this framework through “classes” (import torch.nn as nn) implemented in PyTorch. |
Once the model is trained, it is typically saved in formats such as safetensors or gguf and run using inference engines such as vLLM, SGLang, or llama.cpp. This type of inference engine is more complex: in addition to providing API interfaces and reading/loading models, it iteratively calls the model object’s forward() method to generate tokens step-by-step, manages KV-Cache, and returns the generation results to the user in real-time.
The entire process can be illustrated as follows.
Model Registry
After training a model, it is necessary to introduce a model registry to manage, retrieve, and distribute the model. A model registry is a system or directory structure used for the centralized storage, management, and distribution of AI models. It facilitates model sharing, version control, and deployment within teams or across systems.
- Local model registry: Created and maintained by developers after completing model training.
- Online model registry: Includes both open-source and enterprise-level model registry platforms, such as Hugging Face, which allow users to share large models, manage versions, and perform other operations.
After constructing the AI infrastructure and configuring the learning frameworks and inference engines, users can train and validate models independently, then publish models or obtain other pre-trained models through a model registry to achieve model training, deployment, and usage.
However, when practicing—especially for enterprise-level deployment, delivery, and management of AI models—problems such as complex model file management, slow model delivery, and difficulties in the efficient and unified management of multiple models are frequently encountered. Furthermore, AI models obtained directly from model registries require fine-tuning based on actual business applications and data to achieve enterprise-grade results. These challenges necessitate the introduction of AI Engineering tools to bridge the “last mile” from laboratory development to enterprise-level applications for AI models.
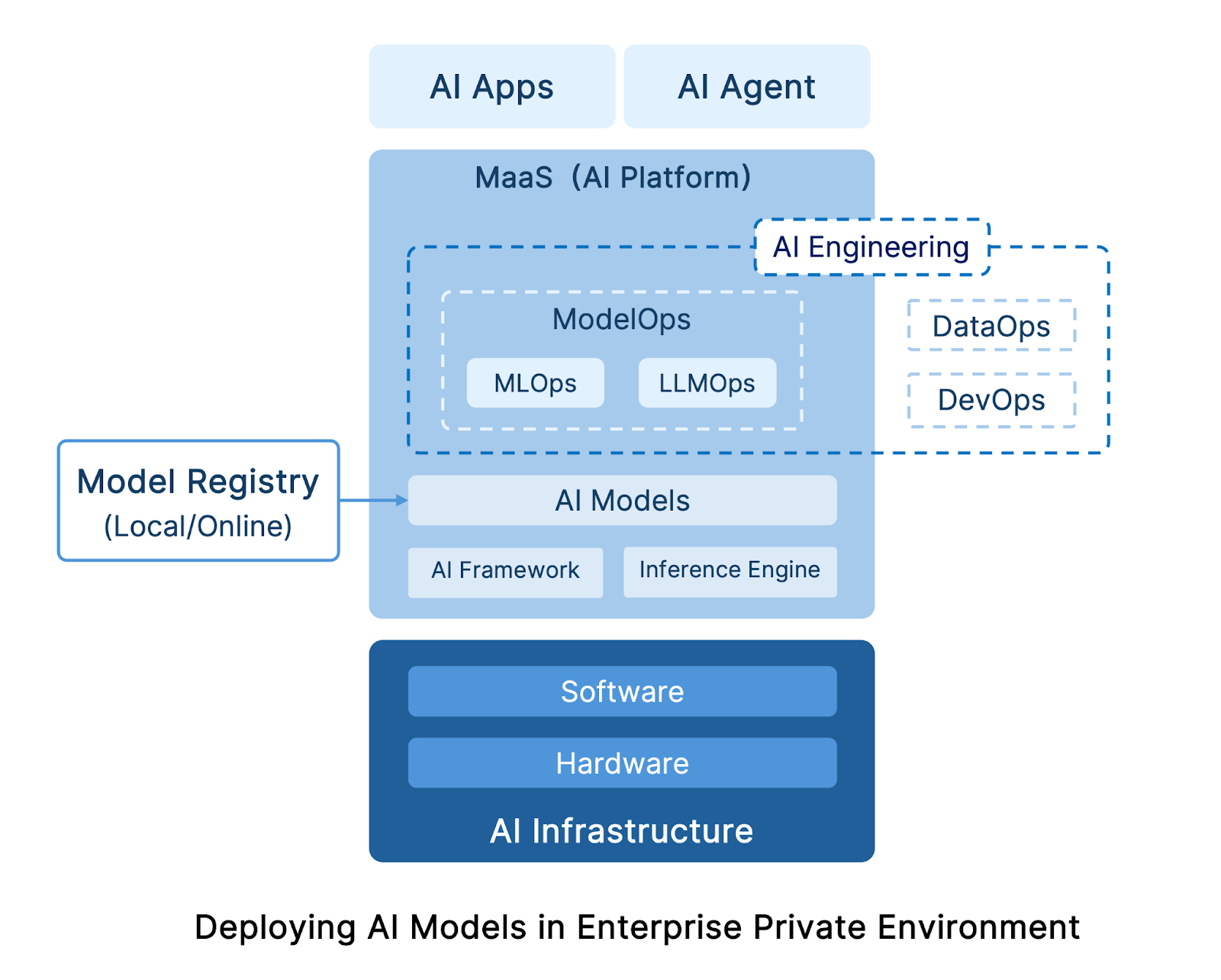
AI Engineering
According to the Gartner report “Hype Cycle for AI in Software Engineering, 2025”, AI Engineering is the foundational engineering for enterprises to deliver AI and GenAI solutions at scale. It integrates DataOps, ModelOps, and DevOps pipelines, helping organizations build a coherent framework for AI system development, deployment, and operation.
ModelOps
According to Gartner’s Demystify the Ops Landscape to Scale AI Initiatives: A Gartner Trend Insight Report, ModelOps is the core of AI Engineering, focusing on the end-to-end governance and lifecycle management of artificial intelligence (AI), decision models, and deep analytics.
The core tasks of ModelOps include model management, deployment, interpretability, rollback/retraining/fine-tuning/upgrading, monitoring, integration, compliance and auditing, and security and privacy.
Through ModelOps, different teams can standardize the construction, testing, deployment, operation, and monitoring methods of multiple AI models across various environments (such as development, testing, and production environments). This ultimately achieves the goals of simplifying model deployment difficulty, improving inference performance and resource utilization, and efficiently managing multiple models.
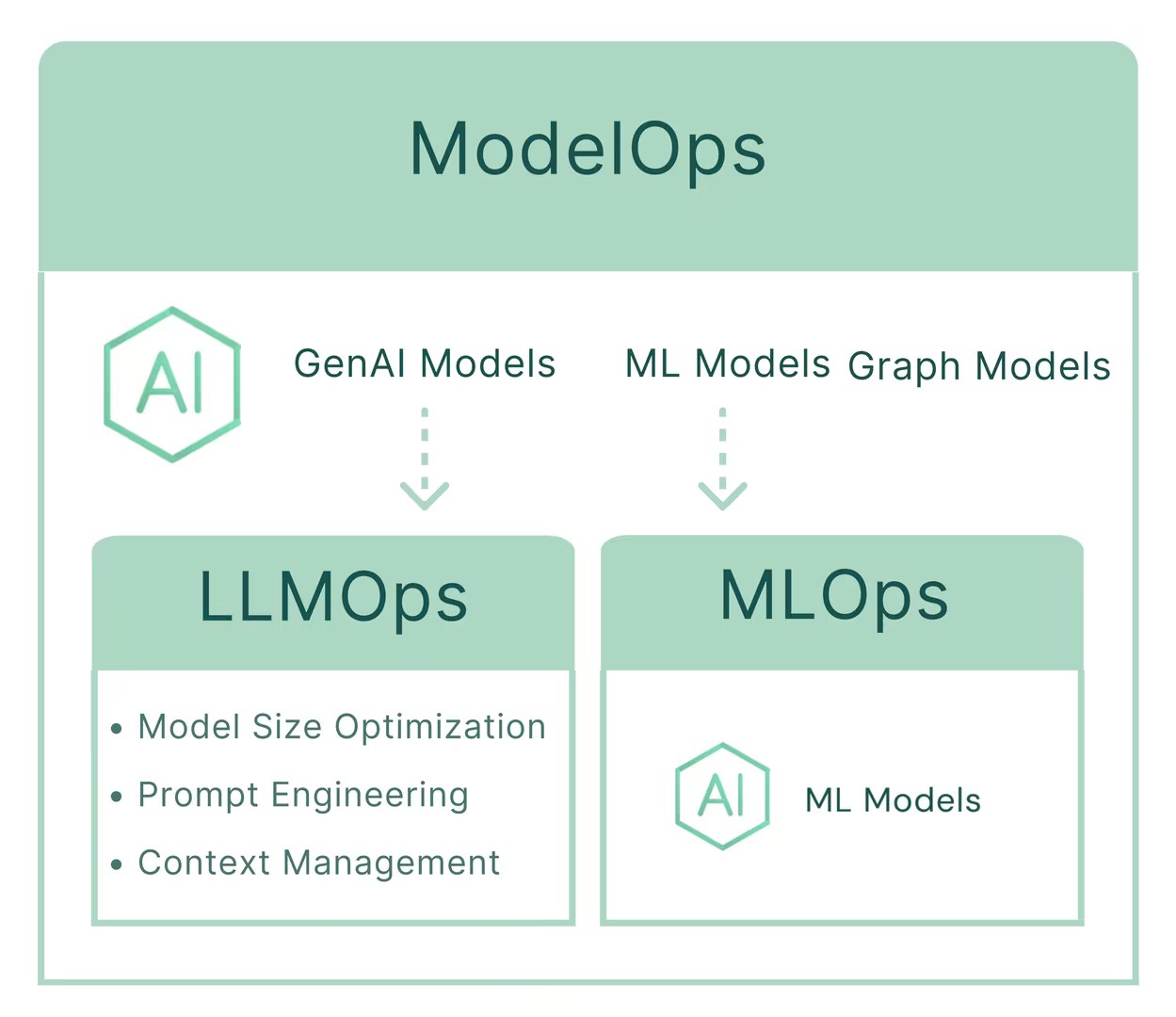
ModelOps vs. MLOps vs. LLMOps
The primary difference between ModelOps, MLOps, and LLMOps lies in the types of models they focus on.
ModelOps focuses not only on machine learning (ML) and large language models (LLM) but also on the operational management of various models, such as graph models, decision models, and deep analytics.
MLOps (Machine Learning Operations) aims to simplify the end-to-end process of development, testing, validation, deployment, and instantiation of ML models.
LLMOps (Large Language Model Operations) represents “customized practices” within the MLOps framework specifically for LLMs, focusing on addressing unique challenges compared to other ML models (such as model size optimization, fine-tuning, prompt engineering, and context management).
Therefore, the concept of ModelOps umbrellas MLOps and LLMOps, though they all share the goal of making AI model deployment, management, and O&M simpler and more standardized.
MaaS (Model as a Service)
Traditionally, during AI model deployments, tasks such as environment setup, model development or downloading, model deployment, training and fine-tuning, as well as resource monitoring and optimization are all performed manually by operations teams. This approach is time-consuming and labor-intensive, resulting in slow model delivery and increasingly complex management as the number of models grows.
As a result, many cloud service providers now offer MaaS (Model as a Service)—sometimes also referred to as AI platforms or inference platforms—to deliver “out-of-the-box” AI model capabilities for enterprises. The main goals of MaaS include simplifying model deployment, management, and fine-tuning, while improving inference efficiency and overall resource utilization.
What Capabilities Does MaaS Typically Provide?
- Model repository: A centralized library of callable pre-trained models, including Large Language Models (LLM), NLP, CV, and speech models.
- Compute resource management: Unified management of heterogeneous compute resources (CPU & GPU) across different locations.
- Inference services: Pre-integrated inference engines and frameworks for running models (such as vLLM, Llama.cpp, and SGLang).
- API / SDK interfaces: Support for HTTP, gRPC, and other invocation methods.
- Model management: Centralized operations and lifecycle management for multiple models.
- Observability: Monitoring of resource utilization and inference performance metrics (e.g., TTFT, TPOT, ITL).
- Metering and billing: Tracking invocation counts, token usage, and related consumption metrics.
- Security and access control: Access restriction mechanisms and data privacy protection.
AI Agent
An AI Agent is an AI system capable of perceiving its environment, making decisions, executing actions, and continuously adjusting its behavior based on feedback.
While ordinary application systems can acquire AI capabilities by calling model APIs, they typically require explicit instructions from the user for every step, and their context usually relies on user input or temporary variables.
In contrast, an AI Agent acts more like an “autonomous decision-making brain”; it only requires a goal provided by the user, after which it plans multiple steps to call models and other tools, and typically possesses “long-term memory” (such as a knowledge base).
Learn more about SmartX’s AI infrastructure solutions from our website and related blog post:
Introducing SmartX HCI Solution for AI Applications
Accelerate DeepSeek Deployment in Enterprises with SmartX ECP: Solution and Validation