
Many enterprises are trying out mature LLMs (Large Language Models) to develop AI applications, or directly running well-trained AI applications in their production environments. These scenarios require both robust computing power and capable IT infrastructure to provide GPU resources, flexible scheduling of resources, consistent support for VM-based and container-based workloads, and storage of diverse data.
Tailored for above scenarios, SmartX has introduced an HCI solution for AI applications. Featuring the convergence of compute resources (CPU and GPU), convergence of workloads, and convergence of storage resources, SmartX HCI provides enterprise-grade AI applications with high-performance, low-latency computing and storage that enables flexible allocation of resources.
Enterprise-Grade AI Application’s Demands on IT Infrastructure
Currently, most enterprises opt to enable AI capabilities by fine-tuning industry-standard LLMs, or by directly deploying AI applications in their production environment. Although these scenarios may not require extensive TFLOPS on GPUs for training LLMs, they still place considerable demands on IT infrastructure in terms of performance, resource utilization, support for containerized environments, and storage of diverse data types.
Flexible Scheduling of Compute and Storage Resources
During the development and testing of AI applications, development teams often require varying amounts of GPU resources, with certain tasks not fully utilizing the entire GPU. Likewise, when running AI applications, the demand for GPU and storage resources may fluctuate frequently. Therefore, IT infrastructure should allow flexible slicing and scheduling of compute and storage resources, as well as the integration of high-performance CPU and GPU processors. This approach can enhance resource utilization while accommodating the diverse requirements of different applications and development tasks.
High-Performance and Low-Latency Storage System
Fine-tuning LLMs using industry-specific data requires significant GPU resources. Accordingly, storage systems should offer high-performance and low-latency support for parallel tasks. The workflow of AI applications comprises several stages that involve extensive data read and write across multiple data sources. For example, the raw data might be pre-processed before it could be utilized for fine-tuning and inference. Additionally, the text, voice, or video data produced during inference must be stored and exported. Meeting these requirements entails a storage solution that delivers high-speed performance.
Storage of Various Data Types and Formats
AI applications often need to process structured data (such as databases), semi-structured data (like logs), and unstructured data (such as images and text) simultaneously. This underscores the need for IT infrastructure that supports diverse data storage. Furthermore, storage requirements for AI applications can vary throughout the workflow. For instance, certain stages may necessitate fast storage responsiveness, while others may prioritize shared reading and writing of data.
Simultaneous Support for Virtualized and Containerized Workloads
As Kubernetes features flexible scheduling, an increasing number of AI applications are being deployed on containers and cloud-native platforms. However, as many traditional applications are still expected to run on VMs in the future, there is a rising demand for IT infrastructure capable of supporting and managing both VMs and containers.
In addition, to support the agile deployment and scaling of AI applications as business grows, the IT infrastructure should possess flexible scalability, straightforward operation and maintenance (O&M), and quick deployment capabilities.
SmartX HCI Solution for AI Applications
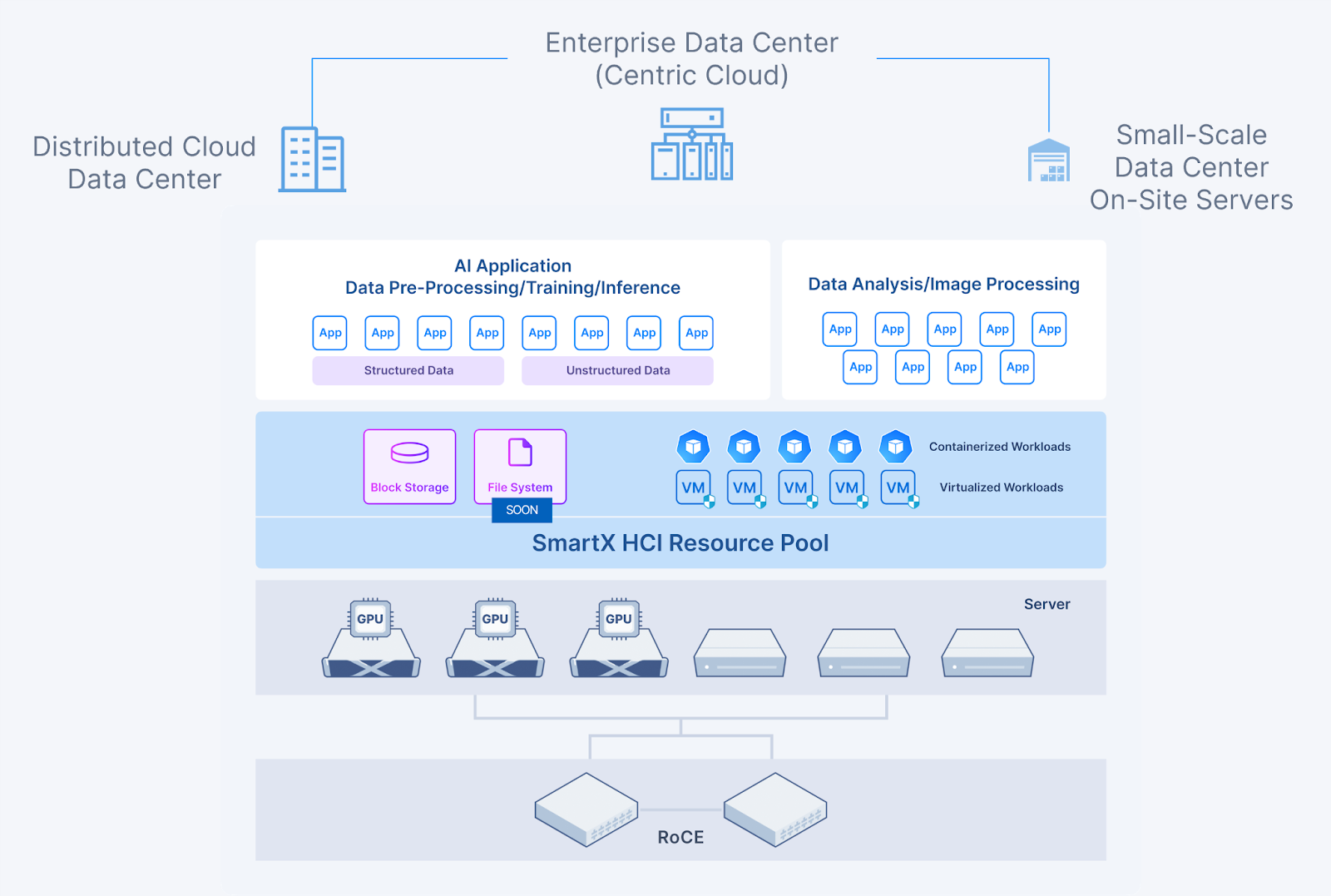
SmartX HCI can provide converged compute and storage resources for AI applications deployed in virtualized and Kubernetes environments:
- Convergence of compute resources (CPU and GPU): Hosts in SmartX HCI cluster can be flexibly configured with different numbers and models of GPU processors, allowing workloads to obtain CPU and GPU resources on demand. Specifically, SmartX HCI supports GPU passthrough and vGPU, along with technologies such as MIG and MPS. These features enable users to slice GPU processors flexibly, enhancing GPU utilization and the efficiency of AI applications in virtualized and containerized environments.
- Convergence of virtualized and containerized workloads: Based on SmartX HCI, users can leverage SMTX Kubernetes Service (SKS) to provide unified support for VM-based and container-based AI applications. This solution caters to the varied requirements of workloads in terms of performance, security, and agility.
- Convergence of diverse data storage: SmartX HCI features a distributed storage solution with proprietary IP. Storage of SmartX HCI supports various storage media, addressing diverse data storage requirements of AI applications. Additionally, it delivers exceptional and stable storage performance, particularly for high I/O use cases.
Convergence of Compute Resources: Flexible Scheduling of CPU and GPU Resources on an Integrated Computing Platform
While LLM-based AI applications require the parallel computing capability of GPUs, the computing resource pools used for generative AI applications should cater to different types of workloads to reduce unnecessary scheduling across CPU and GPU resource pools.
SmartX HCI allows servers with different components to be deployed within the same cluster, which means that each host can be configured with different numbers and models of CPU and GPU processors, supporting AI applications and non-AI applications with an integrated computing resource pool.
With GPU passthrough and vGPU support, SmartX HCI can deliver GPU capability to HPC-centric applications (such as artificial intelligence, machine learning, image recognition processing, VDI, etc.) running in the virtualized environment. The vGPU feature enables users to slice and allocate different GPU resources on demand. This allows multiple VMs to share one GPU, increasing resource utilization while improving AI application performance. >>Click here to learn more about SmartX HCI’s GPU passthrough & vGPU feature.
SmartX HCI also supports NVIDIA MPS and MIG technologies, allowing users to benefit from the flexible sharing of GPU resources.
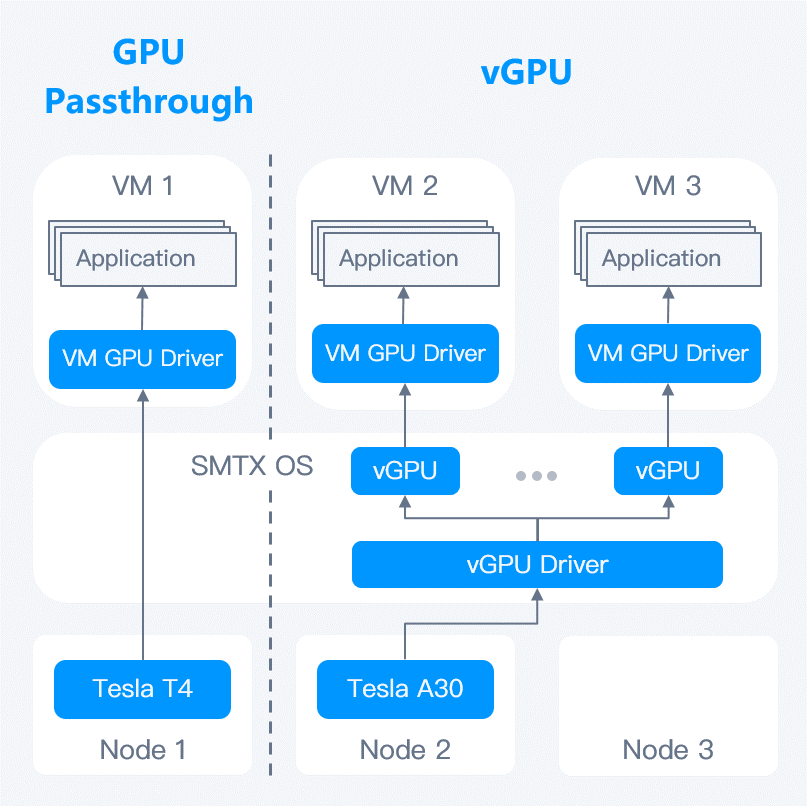
In addition, collaborating with VirtAI Technology, SmartX has introduced a solution for GPU pooling tailored for AI applications on HCI. This solution leverages OrionX’s software-defined capabilities in pooling, managing, and scheduling GPUs to achieve fine-grained slicing and scheduling of parallel computing capability. For example, it can slice a GPU into 0.3 units and combine it with sliced GPU on other nodes. Moreover, it facilitates the management of heterogeneous chips, assisting enterprises in enhancing computing resource utilization and management flexibility.
Convergence of Workloads: Using HCI to Support Both Virtualized and Containerized Workloads
With SKS, users can use SmartX HCI to support both virtualized and containerized AI applications. Given the differing resource consumption models of various AI workloads, a converged deployment ensures efficient resource allocation while meeting the performance, security, scalability, and agility needs of diverse applications. Ultimately, this strategy optimizes resource utilization and reduces total cost of ownership (TCO).
Currently, SKS 1.2 has added support for GPUs, including features such as GPU passthrough, virtual GPUs (vGPUs), time-slicing, multi-instance GPUs, and multi-process service. Additionally, it supports the elastic and flexible management of GPU resources through Kubernetes, meeting the parallel computing requirements of AI applications in container environments while optimizing GPU resource utilization and management flexibility. >>Click here to learn more about SKS 1.2 and its updated features.
Convergence of Storage: Providing High Performance and Reliability for AI Applications on Data Processing and Analysis
AI applications rely on various types of data and require processes such as data collection, cleaning, categorization, inference, output, and archiving during use. The demand this places on storage systems for high-speed access can be easily imagined.
With proprietary distributed storage, SmartX HCI can provide excellent performance and stability for AI applications through technical features such as I/O locality, hot and cold data tiering, Boost mode, RDMA support, and resident cache.
SmartX HCI also adapts to a wide range of storage hardware devices, spanning from cost-effective mechanical hard disks to high-performance NVMe storage devices. For instance, cold or warm data can be stored on low-cost magnetic disks. In cases where there’s a surplus of cold data left after AI tasks, with replication or backup technologies, users can store it in a more budget-friendly storage system, thus achieving a balance between system performance and overall costs.
Furthermore, SmartX HCI offers flexible scalability, enabling users to scale capacity in line with the demands of AI applications, resulting in linear performance growth as capacity increases. Enterprises can also utilize SmartX HCI to support AI applications deployed at edge sites or factories, ensuring that data processing and computing tasks occur at the same site and node. This approach effectively minimizes latency stemming from cross-node communication.
Overall Advantages
Stable and Powerful Storage Core
- The converged deployment of Hypervisor and distributed storage across sites of various sizes can reduce latency caused by data transmission.
- High-performance, highly reliable production-level storage supports the secure preservation of large volumes of unstructured, semi-structured, and structured data, enabling AI applications to perform high-performance processing and analysis.
Flexible and Open Architecture
- Enable seamless scaling of infrastructure to accommodate the expanding demands of AI businesses.
- As a software-defined IT infrastructure, SmartX HCI is decoupled with particular hardware devices. Servers of varying quantities and models can be flexibly configured and managed based on the characteristics and computational requirements of AI applications, including flexible configuration and scheduling of different high-performance processors such as CPUs and GPUs.
Simultaneous Support of Virtualized and Containerized Workloads
- Facilitate the creation, flexible deployment, and timely updates of diverse AI workloads.
- Provide a consistent and integrated runtime environment for virtualized and containerized workloads across various sites.
Simple and Smart O&M
- Simplify IT infrastructure management and improve the O&M efficiency of AI applications and resources.
- Unified management of virtualized and containerized environments across multiple sites, as well as the computing and storage resources required.
For more information on SmartX HCI features and capabilities, please refer to our previous blog: SmartX HCI 5.1: Enhanced Features and New Components.