
Highlight
- SmartX distributed block storage ZBS supports 2 types of data access protocols when deployed in the storage-and-compute-separation mode: iSCSI and NVMe-oF. While iSCSI has many benefits, it is not suitable for high-performance workloads. This is one of the reasons why ZBS was designed to support NVMe-oF.
- ZBS was designed to support NVMe over RDMA/RoCE v2 and NVMe over TCP because of better performance and network conditions. This design could meet customers’ diverse needs.
- In ZBS, NVMe-oF access adopts inheritance strategy and balancing strategy. Such design can make full use of multiple storage access points while avoiding tying up the processing capacity of all storage access points, keeping the workloads at each access point largely balanced.
- We ran two performance tests over ZBS with different access protocols, one for the lab benchmark and one for a financial services customer. The tests disclosed that compared with iSCSI and NVMe over TCP, ZBS showed higher I/O performance, i.e., higher random IOPS and sequential bandwidth, and lower latency, when using NVMe over RDMA as the access protocol.
In the article “Exploring the Architecture of ZBS – SmartX Distributed Block Storage”, we explained the communication between the Access (data access component) and the Meta (management component) in ZBS when I/O occurs. This is the latter part of the I/O path.
In this article, we will focus on the former part, i.e., the access protocol layer for communication between the computation side and ZBS. We will first evaluate different access protocols and explain the design and implementation of NVMe-oF in ZBS, and then provide test data of ZBS performance based on different access protocols.
Overview: Access in ZBS
Access is the interaction boundary between virtual storage objects (Files/LUNs/Namespaces) and actual data blocks (Extents). Access receives read and write requests from NFS Clients, iSCSI Initiators, NVMF Initiators, escapes different protocol objects (e.g., Files, LUNs, Namespaces) into ZBS’s internal Volume and Extent objects, and handles ZBS internal logic such as multiple data replicas.
Access is connected to Meta through the Session mechanism, which ensures the uniqueness of data access permission (Extent Lease).
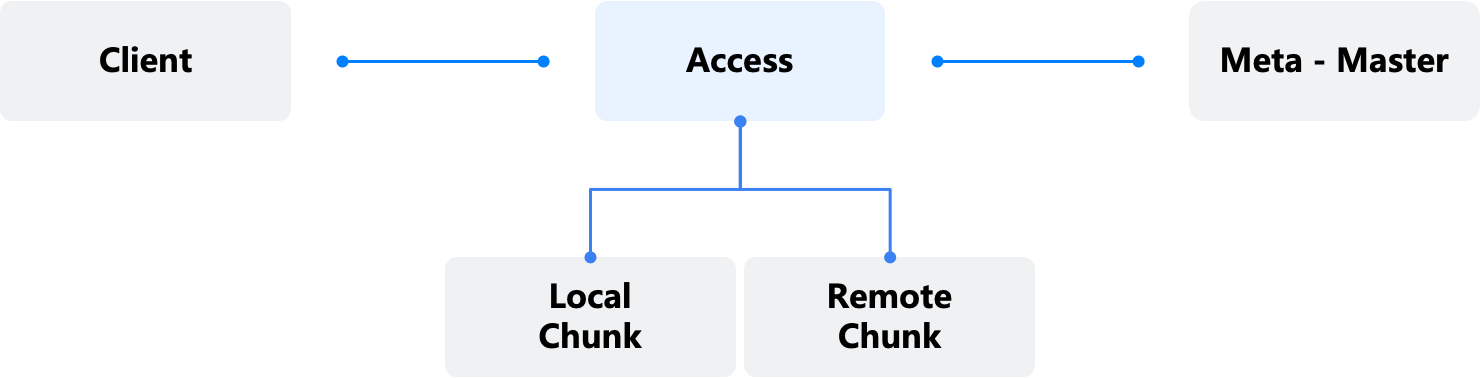
Access Protocols in ZBS
At present, ZBS supports 4 types of access protocols, namely NFS, iSCSI, NVMe-oF and vHost. Among these access protocols, NFS and vHost are mainly used in the hyperconvergence scenario. So in this article, we will focus on iSCSI and NVMe-oF, which are the access protocols used in the architecture where storage and compute are deployed separately.
iSCSI & NVMe-oF access protocols in ZBS
Implementation of iSCSI in ZBS
Currently, for cloud computing with block storage, iSCSI is one of the mainstream access methods for distributed storage SDS due to various advantages, including being based on standard TCP/IP protocol stack, no request of changing existing client systems, wide compatibility with server hardware and standard Ethernet, and ease of management.
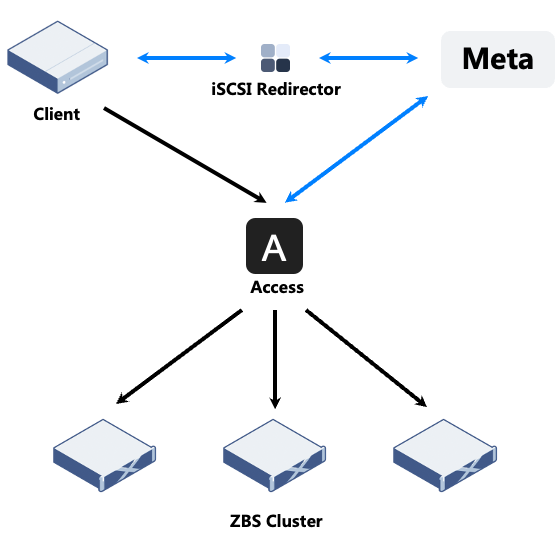
In ZBS, none of the clients point (initiators) directs to a specific storage node, but to the iSCSI Redirector service address, with Access being the protocol access side. When the iSCSI initiators send Login requests to the iSCSI Redirector, the latter forwards the Login requests to Meta, which looks for the bound Access Server basing on the Session information maintained by Access, and returns the corresponding Access Server address, if there is one. Otherwise, any Access Server address is returned. The clients (initiators) will complete the Login process and the subsequent I/O processing flow with the corresponding Access Server.
The complexity of high availability configurations in iSCSI access can be simplified with the Redirector service. Similarly, iSCSI also provides single-point access guarantee with single client (initiator) accessing one iSCSI Target by using only one data link (to avoid multi-point access to the same Target) based on the Redirector service, as well as balancing access links.
Although iSCSI has many advantages, it cannot sufficiently support high-speed storage and network equipment and provide an optimized performance. The design of the SCSI protocol can date back to the last century when the hardware market was still dominated by mechanical disks. So the protocol has shown its weakness in adapting to today’s high-performance hardware, such as NVMe media, as well as modern workloads. Besides, compared with new protocols, iSCSI is more bulky and inefficient resulting from the long-term development.
Notably, iSER (iSCSI Extensions for RDMA) presents a performance evolution of iSCSI. The capability of RDMA improves iSCSI’s performance on the network layer. However, ZBS does not adopt this technology stack. The reason’s simple: now that RDMA is to be used, using the new NVMe protocol to support high-performance workloads would be a better choice.
An Introduction to NVMe-oF
Before introducing NVMe-oF, let’s briefly walk through the NVM Express (NVMe) protocol specification. NVMe defines how hosts communicate with non-volatile memory over the PCIe bus. The NVMe specification is tailored to SSD high-speed storage media and is more efficient than SCSI. It supports 65,535 I/O queues with 65,535 commands supported per queue (queue depth). Queue mapping provides expected scheduling of CPU resources and can accommodate device drivers in interrupt or polling mode, resulting in higher data throughput and lower communication latency.
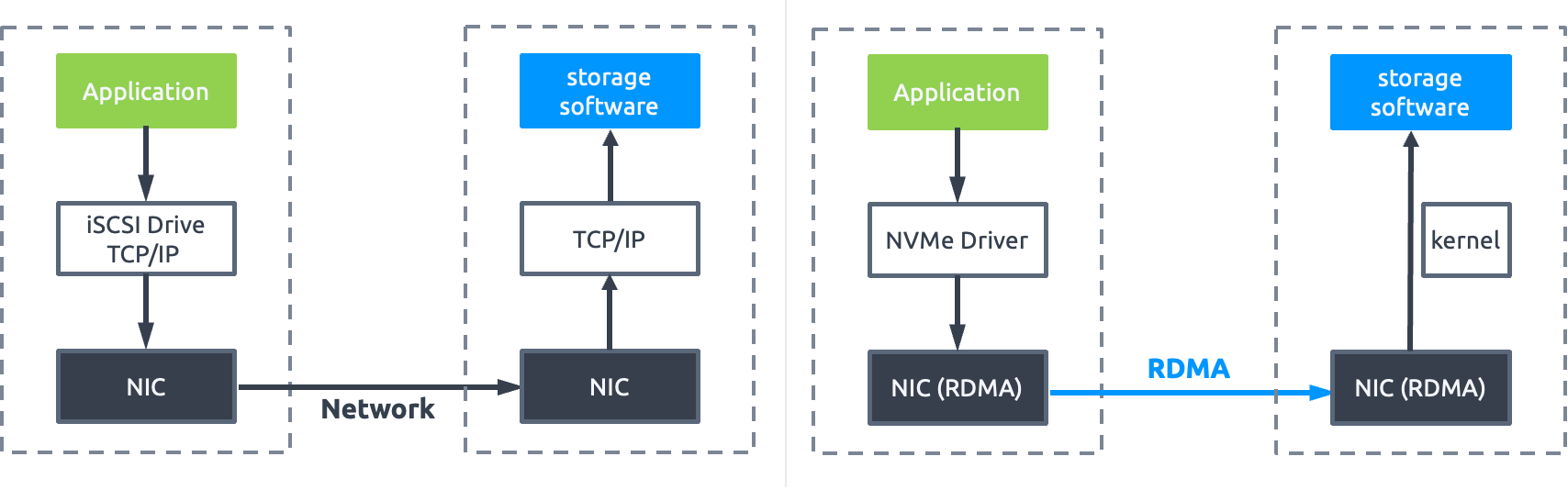
Faster storage requires faster network. NVMe-oF (NVMe over Fabrics), inherits such advantages as high performance, low latency and ultra-low protocol overhead that NVMe provides within a single system and extends them to the network structure where the clients interconnect to the storage system. NVMe-oF defines the use of multiple universal transport layer protocols to implement NVMe remote connection capabilities.
The NVMe-oF hosted network (data plane) includes:
- NVMe over FC: Based on traditional FC network (proprietary communication network built with host bus adapter HBAs and optical fiber switches), NVMe over FC can run simultaneously with FC-SAN (SCSI) in the same FC network, maximizing the reuse of FC network basic environment and taking advantage of the new NVMe protocol. It is often used for upgrading traditional centralized storage.
- NVMe over RDMA: Allowing client programs to, by means of remote direct memory access technology, remotely access the memory space of the storage system for data transfer. It has features such as Zero Data Copy (no network stack involved in performing data transfer), Kernel Bypass (application can perform data transfer directly from user space without kernel involvement), and reduced CPU resource consumption (application can access remote memory without consuming any CPU Cycle in the remote server).
- InfiniBand – Using RDMA over the InfiniBand network is very popular in the High-Performance Computing (HPC) field. Like FC, it requires proprietary network adapter and switching network support.
- RoCE – RoCE is the abbreviation of RDMA over Converged Ethernet, i.e., implementing RDMA over Ethernet. Currently it has two versions: RoCEv1 is non-routable and only works at Layer 2; RoCEv2 uses UDP/IP and has Layer 3 routing capacity.
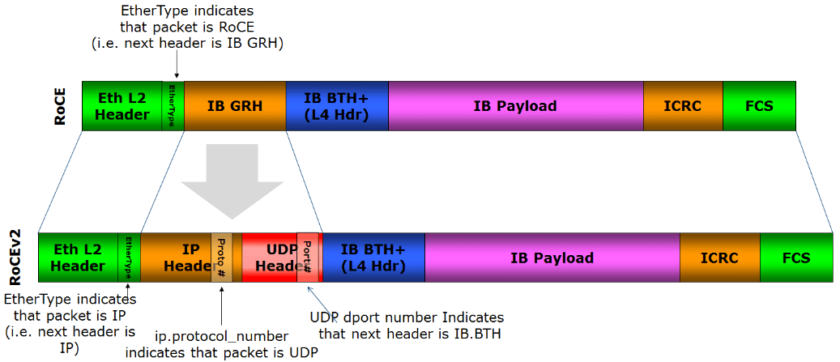
RoCEv1/v2 (Resource: Wikipedia) - iWARP – Built on top of TCP/IP. Unlike the RoCE protocol, which is inherited from Infiniband, iWARP itself is not directly developed from Infiniband. Both Infiniband and RoCE protocols are based on the “Infiniband Architecture Specification”, which is often referred to as the “IB Specification”. iWARP, on the other hand, is self-contained and follows a set of protocol standards designed by IETF. Although following different standards, iWARP’s design has been influenced by Infiniband in many ways, and currently uses the same set of programming interfaces as Infiniband.
- NVMe over TCP: Unlike the previous two implementations, NVMe over TCP does not have any special hardware requirements and is based on the universal standard Ethernet. Low cost is an advantage of this protocol. The disadvantages include involving more CPU resources in data processing. Limited by the TCP/IP protocol, more latency will be introduced in data transfer compared with RDMA.
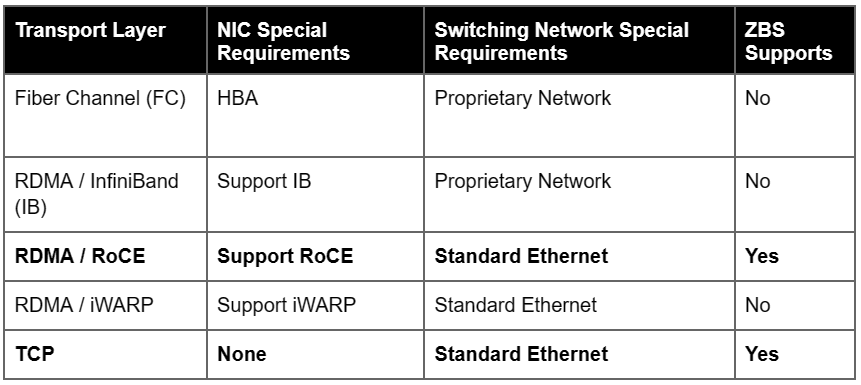
ZBS’s missing support for FC and IB is mainly due to their reliance on proprietary network, which is in conflict with the product positioning (i.e., building distributed storage networks based on standard Ethernet).
ZBS does not support iWARP either. This is because, compared with RoCE*, SmartX is more optimistic about the future development of RoCE in terms of ecology, protocol efficiency and complexity. Also, to pursue an optimized performance, RoCE will have better potential than iWARP. Admittedly, RoCE is protocol-limited in terms of data retransmission and congestion control and requires a lossless network environment (RoCE has a very poor performance in terms of NACK retransmission mechanism for packet-dropping PSNs). But we believe RoCE’s advantages outweigh more and could bring more benefits to our customers.
* The support of iWARP and RoCE is an either/or situation.
To summarize, we’ve identified three technology routes available for NVMe-oF application, namely FC, RDMA and TCP. Considering performance and network conditions, ZBS has chosen to support RDMA/RoCE v2 and TCP, which is a combination that can perfectly meet individual needs of diverse customers.
- Users who are performance-sensitive and are willing to increase network investment for improved performance may choose to use the RDMA/RoCE v2 access option.
- Users who are cost-sensitive or restricted by network conditions may choose the TCP access option.
Implementation of NVMe-oF in ZBS
ZBS supports two NVMe-oF formats, i.e. RDMA/RoCE v2 and TCP. They differ only in the protocol that external clients use to access Access. There is no difference in terms of metadata management.
The NVMe-oF protocol itself has many similarities with the iSCSI protocol, for example, the client side is identified as the initiator side, the server side is identified as the Target side, and the NVMe-oF protocol uses NQNs (similar to iSCSI IQNs) as the identifiers for both parties of the protocol communication. But NVMe-oF defines proprietary standards for Subsystem (equivalent to Target under the SCSI architecture) and Namespace (similar to LUN under the SCSI architecture).
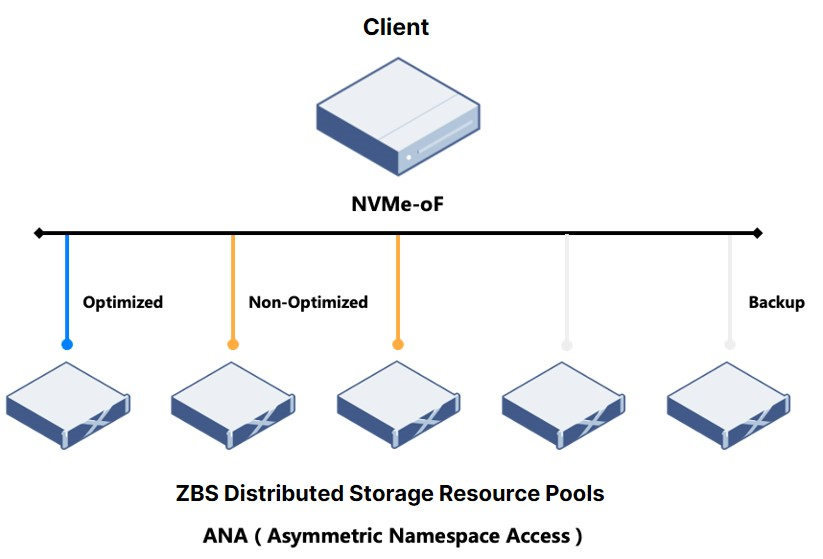
Compared with iSCSI which controls data links via initiator + Target, NVMe-oF supports a smaller granularity of link control: initiator + Namespace. In terms of path strategy selection (Multipath is natively supported by the protocol), what NVMe-oF does is specify the Target link priority through the ANA (Asymmetric Namespace Access) mechanism. Then, the client will select the specific I/O path by combining the priority with its own link state detection result.
Particularly, ANA states include Optimized, Non-optimized, Inaccessible, Persistent Loss, and Change.
ZBS will set all available links to both OP (Optimized Link) and Non-OP (Non-Optimized Link) states. The Driver in case of exceptions or changes automatically marks other states. For each initiator + Namespace, only 1 optimized access point and 2 non-optimized access points are returned. When the optimized access point is available, the client will access data only through the optimized access point. In case of exception, one of the 2 non-optimized access points will be selected for access (To simplify security processing, the client must be deployed in AB mode. Even if the 2 non-optimized access points are equivalent, they will not enter AA mode and dispatch I/O from both access points at the same time).
ZBS has two access strategies:
- Inheritance strategy: all Namespaces in the same Subsystem are accessed by the same client using the same access point.
- Balancing strategy: guaranteeing that Namespaces in the same Namespace Group use different access points as much as possible.
These strategies can achieve the following goals:
- From the client perspective, it permits the use of the processing capacity of multiple storage access points.
- From the client perspective, it guarantees fairness among different clients and avoids tying up the processing capacity of all storage access points,different clients use their own access points.
- From the storage access point perspective, it keeps the load of each access point largely balanced while maximizing the processing capacity of multiple access points.
Performance Test – Lab Benchmark
Test Environment
Storage cluster consisted of 3 nodes and used SMTX ZBS 5.2. RDMA was enabled on the storage internal network. The storage was based on the tiered storage structure. All storage nodes had the same hardware configuration.
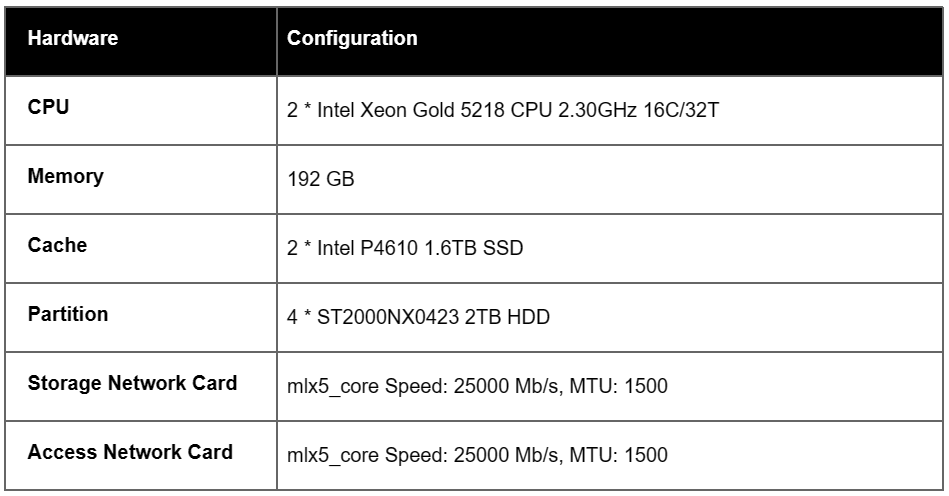
Computation side used CentOS 8.2. FIO stress tool was used (model direct=1, numjobs=1, ioengine=libaio).

Test Result
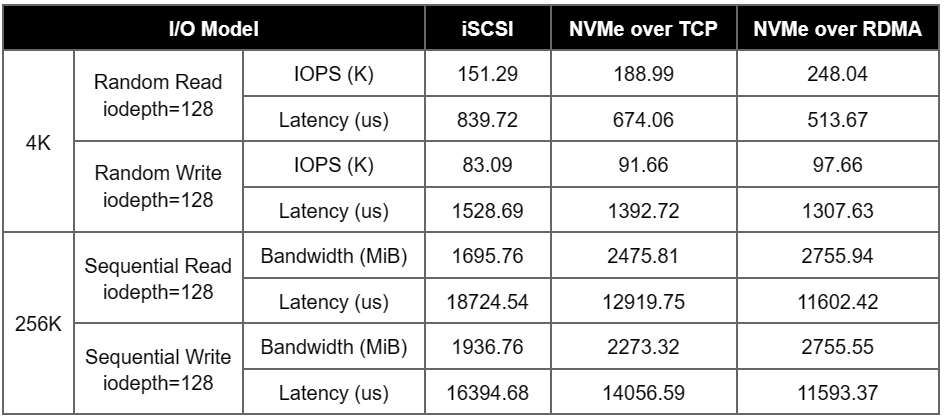
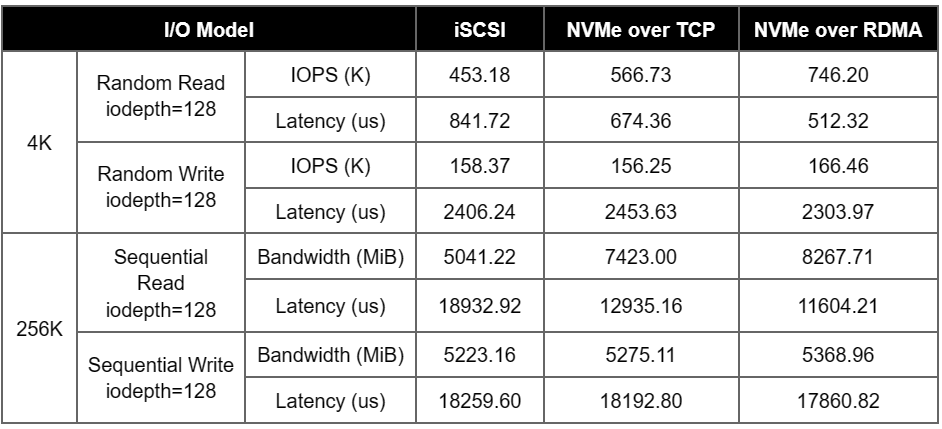
We tested the storage benchmark performance (4K random I/O, 256K sequential I/O) of ZBS with different access protocols (iSCSI, NVMe over TCP and NVMe over RDMA) under the same test environment and test method. We tested the storage based on single volume (Single node performance. 1 volume with 2 replicas was tested) and multi-volume (Cluster performance. For a 3-node cluster, 3 volumes with 2 replicas were tested).
Single Volume
Multi-Volume
Conclusion
Under the same hardware and software environment and testing method, using NVMe over RDMA as the access protocol could achieve higher I/O performance output, which was reflected by higher random IOPS and sequential bandwidth, and lower latency performance.
Performance Test – Under the Requirement of A Commercial Bank
Unlike lab benchmark performance tests, users focus on the I/O model that fits their business services. The performance test requirements from a commercial bank were as follows:
- Validating iSCSI, NVMe over TCP and NVMe over RDMA performance in the same environment.
- I/O models were 8K and 16K random read/write with a read/write ratio of 5:5.
- Validating the IOPS performance based on the maximum average write latency of 300us and 500us, and the corresponding iodepth.
- In all access protocol scenarios, RDMA was enabled internally within the distributed storage.
Test Environment
Storage cluster consisted of 3 nodes and used SMTX ZBS 5.0. RDMA was enabled on the storage internal network. The storage was based on the tiered storage structure. All storage nodes had the same hardware configuration.
Three computation sites used CentOS 8.4. Vdbench stress tool was used.

Test Result
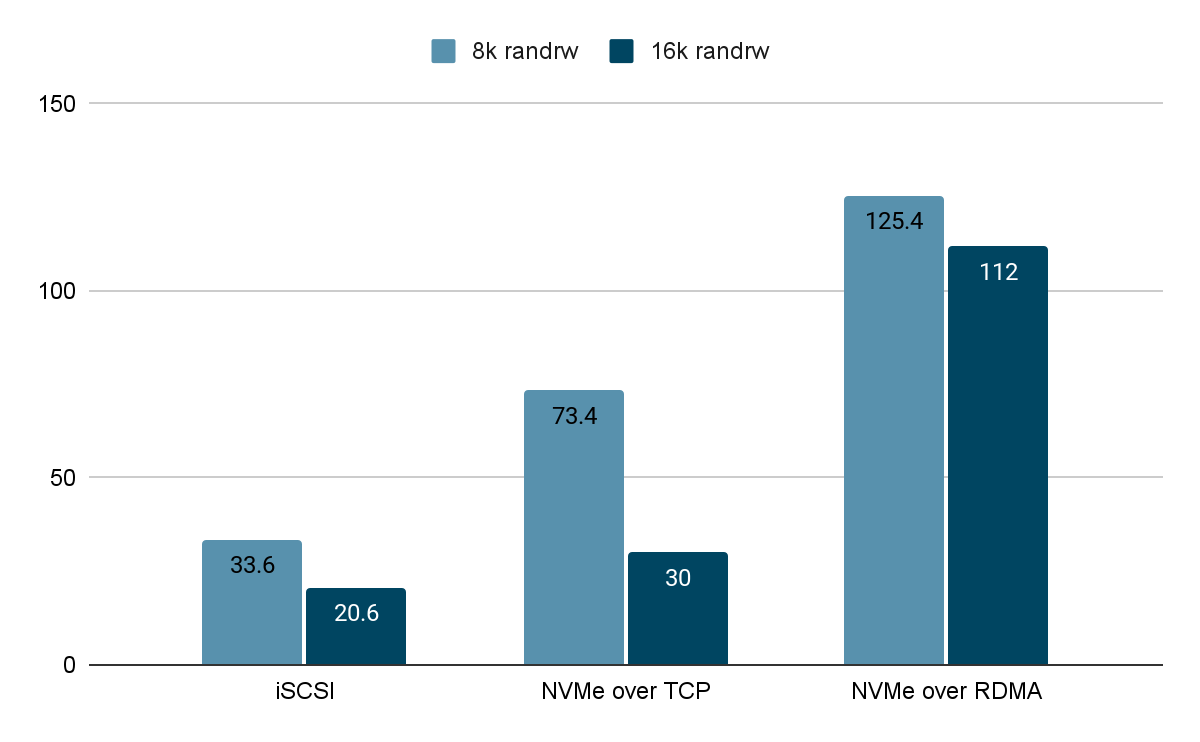
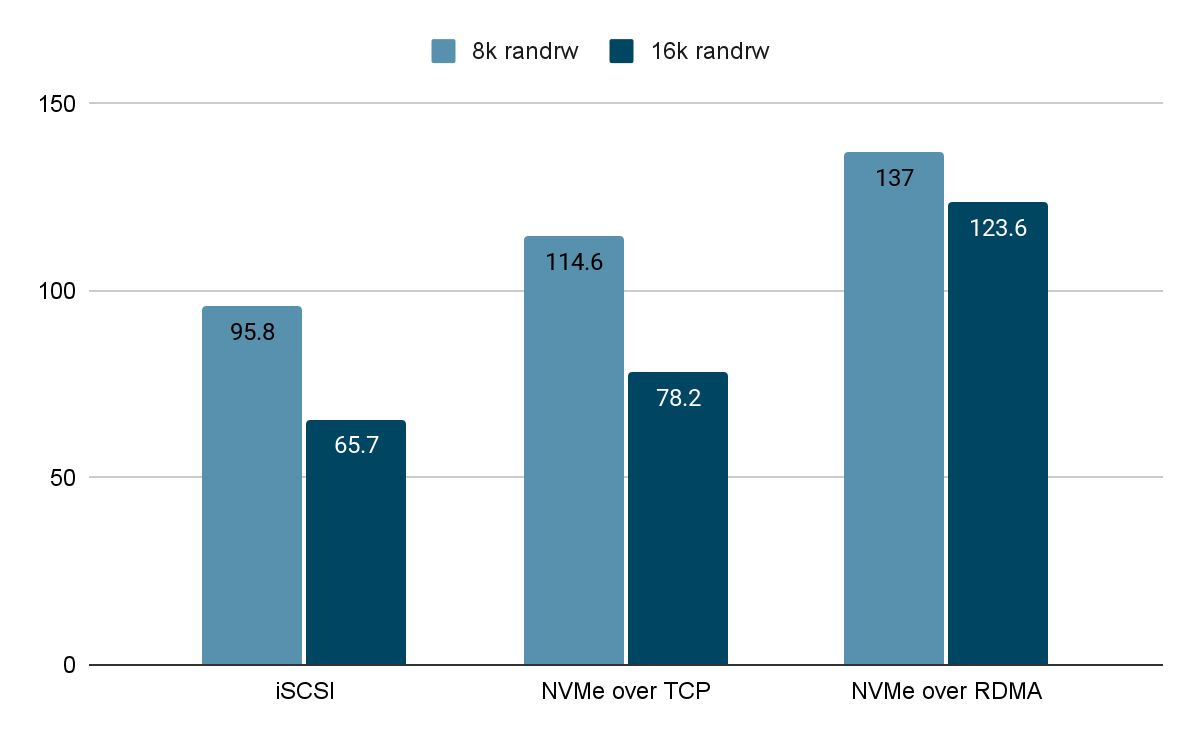
We tested the multi-volume storage performance (For a 3-node cluster, 3 volumes with 2 replicas were tested) of ZBS with different access protocols (iSCSI, NVMe over TCP and NVMe over RDMA) under the same test environment and test method.
IOPS (K) When Latency <= 300us
IOPS (K) When Latency <= 500us
 Conclusion
Conclusion
Under the fixed write latency, NVMe over RDMA still delivered the highest random I/O performance in both 8K and 16K mixed read and write tests.
To Wrap Up
We hope this blog presents a more comprehensive view of the design and implementation of NVMe-oF in ZBS. Overall, with NVMe-oF (RDMA/RoCE v2 and TCP), ZBS can provide higher storage performance to performance-sensitive applications while also providing cost-effective services to general applications, meeting a variety of customer demands.
References:
- RDMA over Converged Ethernet. Wikipedia.
https://en.wikipedia.org/wiki/RDMA_over_Converged_Ethernet
- How Ethernet RDMA Protocols iWARP and RoCE Support NVMe over Fabrics.