Virtual Machine High Availability (VM HA) is a crucial feature for virtualization and hyperconvergence infrastructure. It ensures that VMs can be quickly rebuilt in case of server failures, thereby minimizing failure‘s impact on business operations. To maintain business continuity as much as possible, VM HA should be able to cover a broad range of failure scenarios, accurately identify specific failures, and carry out appropriate switchover strategies according to failure issues.
Featuring the converged deployment of compute and storage, SMTX OS (SmartX hyperconvergence infrastructure software) enhances the effectiveness of VM HA through storage features such as multi-replica strategy and rack awareness (topology-aware data allocation). Additionally, it offers rich VM rebuilding services that enable IT engineers to address various server and VM failure scenarios through an optimized VM HA function.
In the following sections, we will first explore how to ensure the availability of hyperconverged infrastructure, followed by an introduction to the VM HA designs and functionality of SMTX OS.
1 Ensuring Availability of Hyperconvergence Infrastructure
Hyperconverged infrastructure offers a VM HA feature similar to that of traditional virtualization platforms. In the event of a server failure, affected VMs are automatically rebuilt and migrated to other healthy hosts within the cluster. This feature reduces downtime and minimizes service interruptions, eliminating the need for dedicated backup hardware and additional software installations. Key stages of VM HA generally include:
- Accurately detect faults and trigger VM HA.
- Independent from VM operating systems and software, VM HA will implement host migration while ensuring VM consistency.
- Select an appropriate target host to restart the VM, and complete the HA process.
1.1 Core Difference Lies in Storage Availability
However, differences still exist in the design and implementation of VM HA between hyperconvergence infrastructure and virtualization platform. In a virtualization platform, once a failure occurs, to transfer and resume VMs on other hosts, VM data needs to be stored in a shared storage device accessible to all hosts. This means VM HA on a virtualization platform heavily relies on shared storage (such as external storage devices like FC-SAN or IP-SAN). In traditional architecture, as hosts and shared storage operate independently, storage availability is ensured by the storage device itself. Consequently, the HA feature of the virtualization platform does not involve storage availability capabilities.
In contrast, hyperconvergence infrastructure converges compute virtualization and software-defined storage on the same host. This convergence introduces the complexity of designing HA for hyperconverged infrastructure, as it requires ensuring the availability of both compute virtualization and storage simultaneously.
1.2 Impact of Server Node Failures on SMTX OS Clusters
1.2.1 Impact on Virtualized Computing
Server node failures can directly impact the functionality of VMs:
- If the entire node fails, VMs will naturally cease to operate.
- In the case of a partial failure, VMs may continue to operate but might not be able to connect to the network or perform read and write I/O operations normally.
Regardless of the failure types, it is highly likely to affect the normal operation of business services and requires VM HA to restore business services as quickly as possible.
1.2.2 Impact on Storage
SMTX OS provides data redundancy protection through multiple replicas, with all written data automatically replicated into multiple copies (optionally 2 copies or 3 copies) and different copies of the same data written to separate servers. Therefore, in the event of one or more server node failures, one or more copies of the software-defined storage will go offline.
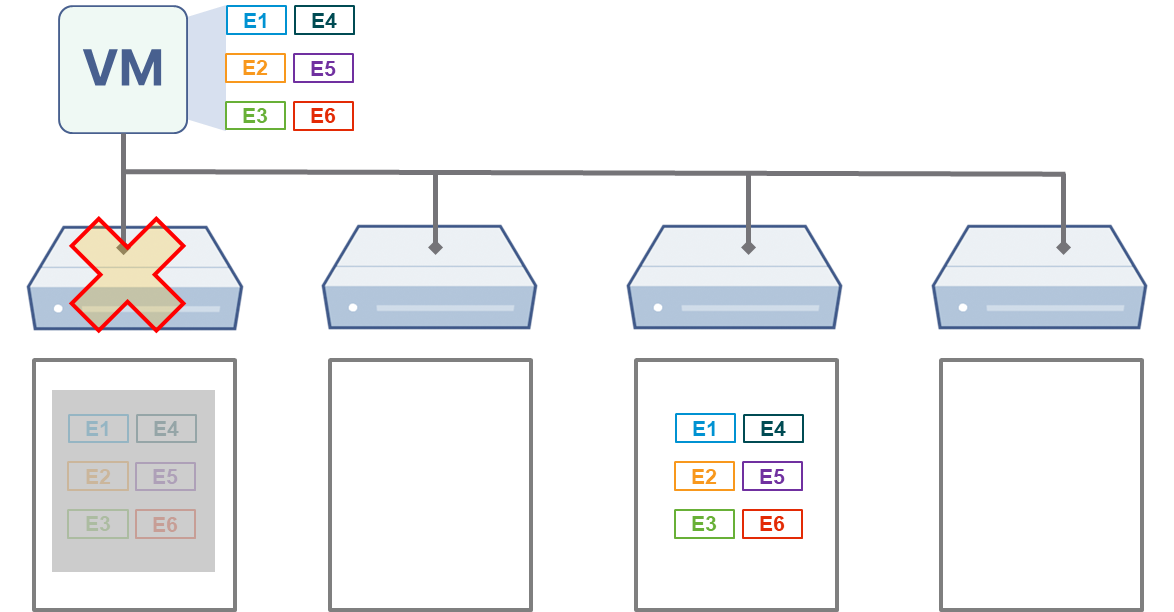
2 Protection Scope of VM HA in SMTX OS
2.1 Applicable Failure Scenarios
Given the complex and varied nature of failures in production environments, VM HA must accurately identify failure scenarios. Incorrect or overly frequent triggering of HA can negatively impact business continuity.
To address this, VM HA in SMTX OS is designed to handle a wide range of failure scenarios. Currently, it covers the following four common failure scenarios and can trigger appropriate HA switchover strategies accordingly.
2.1.1 Server Node Fails or Not Respond
If a server node goes down and the VMs on it are passively shut down, the system will automatically trigger VM HA. It will obtain a list of VMs from the failed server and rebuild these VMs on other healthy nodes in the cluster to resume business operations.
2.1.2 Server Node’s Storage Network Fails
If all the storage network ports of a server node fail, this node’s hard disk devices and data will go offline and the node cannot communicate with other healthy nodes in the cluster. At this time, the network heartbeat will go timeout. If the network outage lasts for 9 detection cycles (90s), the system will trigger the node to isolate itself and actively suspend the VMs on the failed node (if the suspension is not possible, these VMs will be shut down directly). Subsequently, the system will rebuild these VMs on other healthy nodes to resume business operations.
2.1.3 VM Network Fails
SMTX OS also supports the detection of VM network failures. If all business network ports on a node fail while the storage network ports remain functional, the system will trigger an HA within 60 seconds. In this scenario, the VMs will not be restarted. Instead, the system will automatically migrate the VMs from the failed node to other healthy nodes in the cluster.
2.1.4 Inconsistent VM Status
If a power outage occurs in the server room, causing all nodes in the cluster to go offline simultaneously, the system cannot initiate VM HA. However, once power is restored, the HA function will be retriggered. Since there is no hardware failure, the system will prioritize restarting the VMs on the original nodes to restore normal VM operations.
2.2 VM HA Switch
In addition, for specific VMs that users do not expect an automatic trigger of the HA function, SMTX OS provides a VM HA switch feature. This feature allows users to enable or disable the HA function for each VM individually. In the event of a node failure, VMs with the HA function disabled will remain powered off, allowing users to choose to manually restart them.
3 Design and Functionality of SMTX OS VM HA
3.1 VM HA Trigger Mechanism
- VM HA function of a cluster is enabled by default, with one node designated as the HA Leader and the others as HA Followers.
- Each node in the cluster has a VM Monitor.
- HA Followers write heartbeat information periodically (every 10s) through VM Monitors.
- The HA Leader node reads the heartbeat information periodically (every 10s) through the VM Monitor, and assesses the status of other nodes.
HA Trigger Timeline:

*Note: The time points above are not applicable if the HA leader node fails.
3.2 VM Rebuilding Mechanism
Theoretically, when HA is triggered, the system can restart the VM at a randomly selected host in the cluster as long as it’s healthy. However, considering that not all hosts in the cluster have identical hardware configurations, restarting VMs on another host may disrupt normal business operations if they are sensitive to the host’s hardware environment. Therefore, SmartX provides a fine-grained VM rebuilding mechanism.
3.2.1 VM Placement Group
The essence of creating a virtual machine placement group is to enforce placement rules for a group of virtual machines so that they will be placed on proper nodes without unexpected interruption every time they are powered on, migrated, or rebuilt after high availability is enabled. Applicable scenarios include:
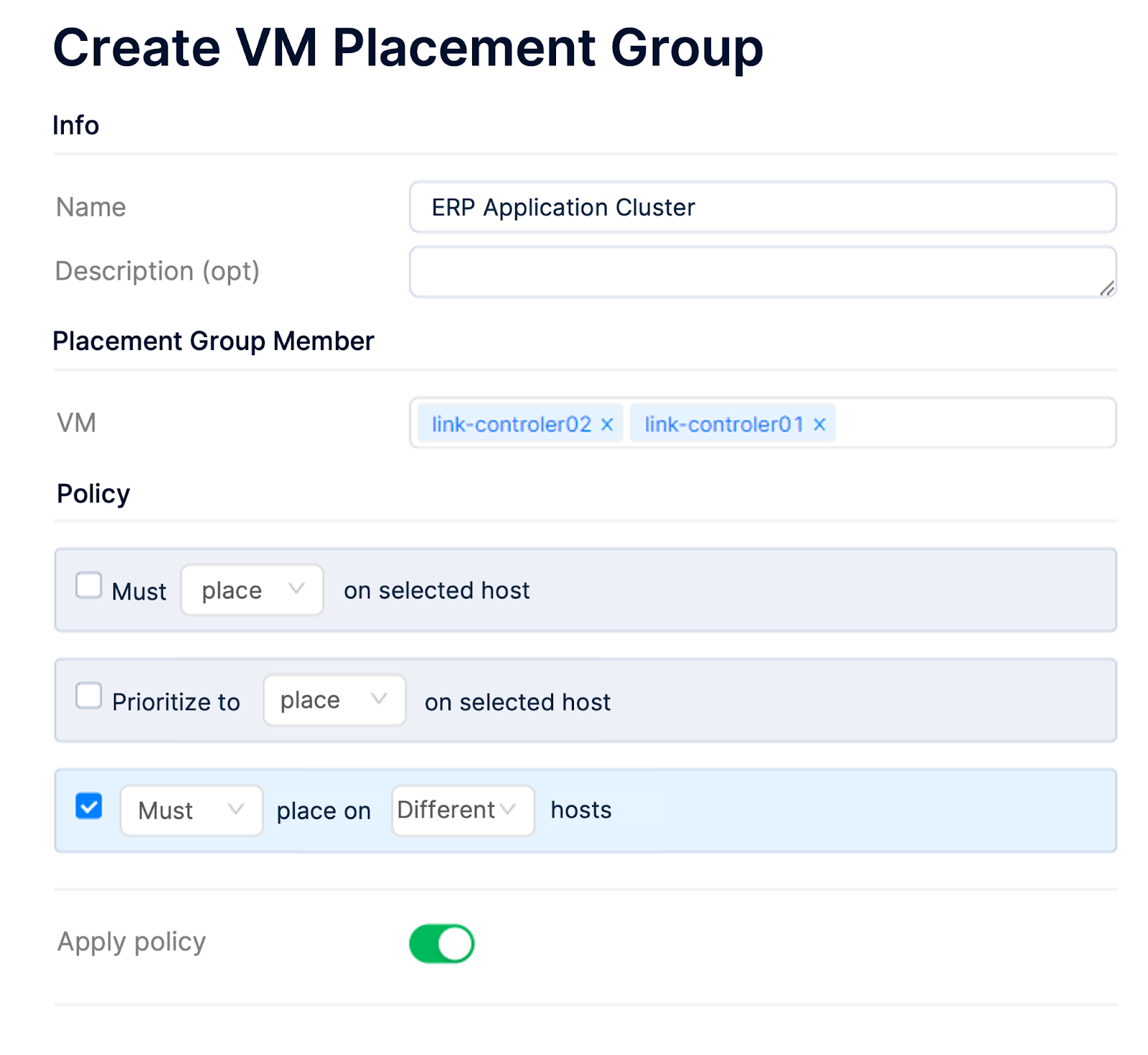
(1) HA for business services
Multiple VMs supporting the same business should not be placed on the same host when implementing application-level failover. Otherwise, a single host failure may affect the business continuity. In this case, users can leverage the placement group policy and set relevant VMs to get rebuilt on different hosts when HA is triggered.
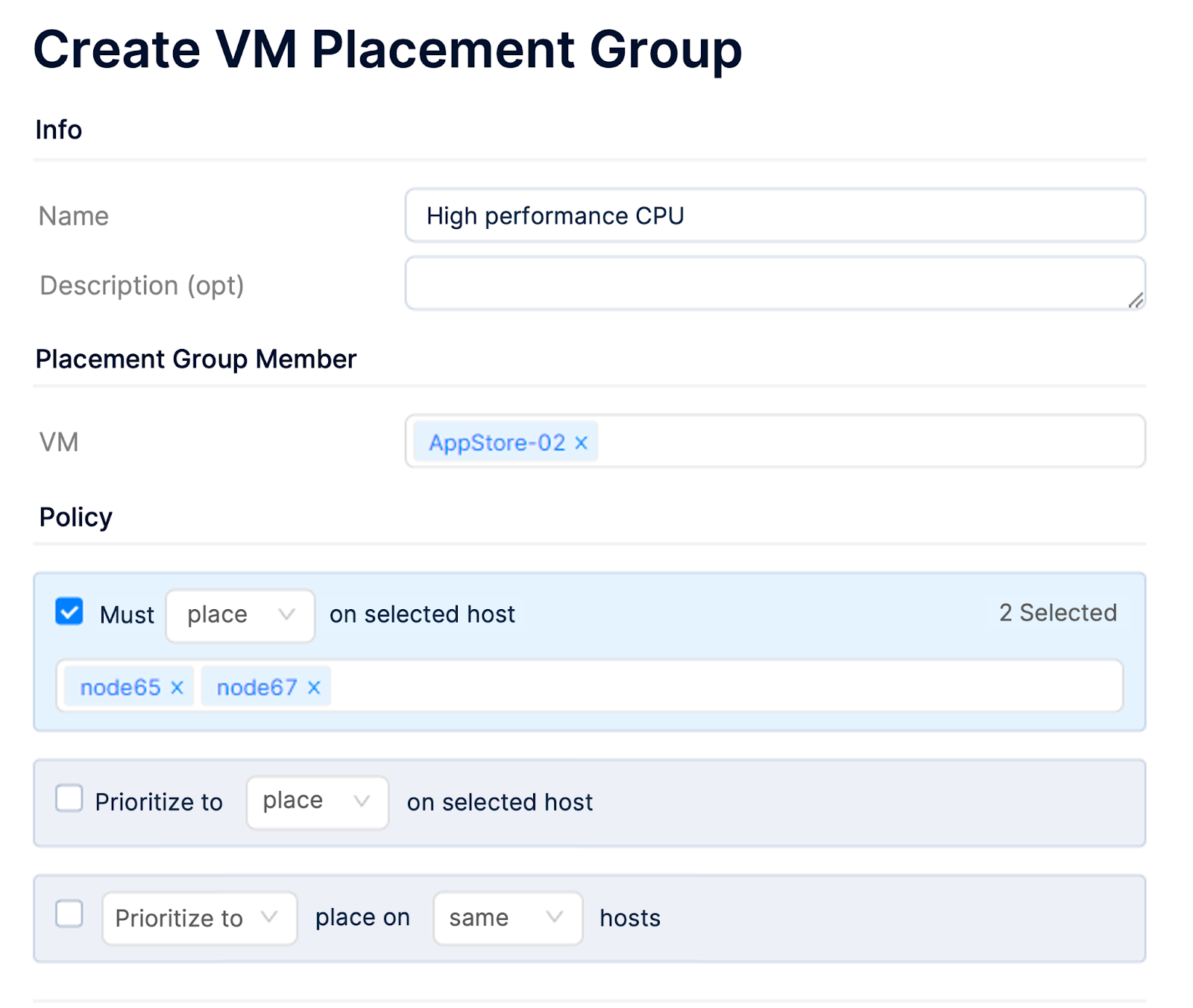
(2) Business service is sensitive to the host CPU
- If the VM’s vCPU uses pass-through mode and is rebuilt on a host configured with a different CPU model, the vCPU model of that VM will also change. As some applications are bound to machine codes that include CPU information, this change may cause the license to get invalidated.
- If a VM has specific requirements for CPU performance, such as requiring a specific CPU main frequency or CPU family, rebuilding it on other hosts could potentially result in degraded business performance.
For the above scenarios, users can set the placement group policy to ensure that VMs will be rebuilt on a designated host (with specific CPU resources) after triggering HA.
(3) Businesses with Specific Network Requirements
If VMs need to access a particular network, and only certain hosts in the cluster can access that network or network port, it is possible that the VM can not communicate properly after HA. In this case, users can set the placement group policy to ensure that the VMs will be rebuilt on the designated hosts (with specific network resources) after triggering HA.
3.2.2 HA Priority
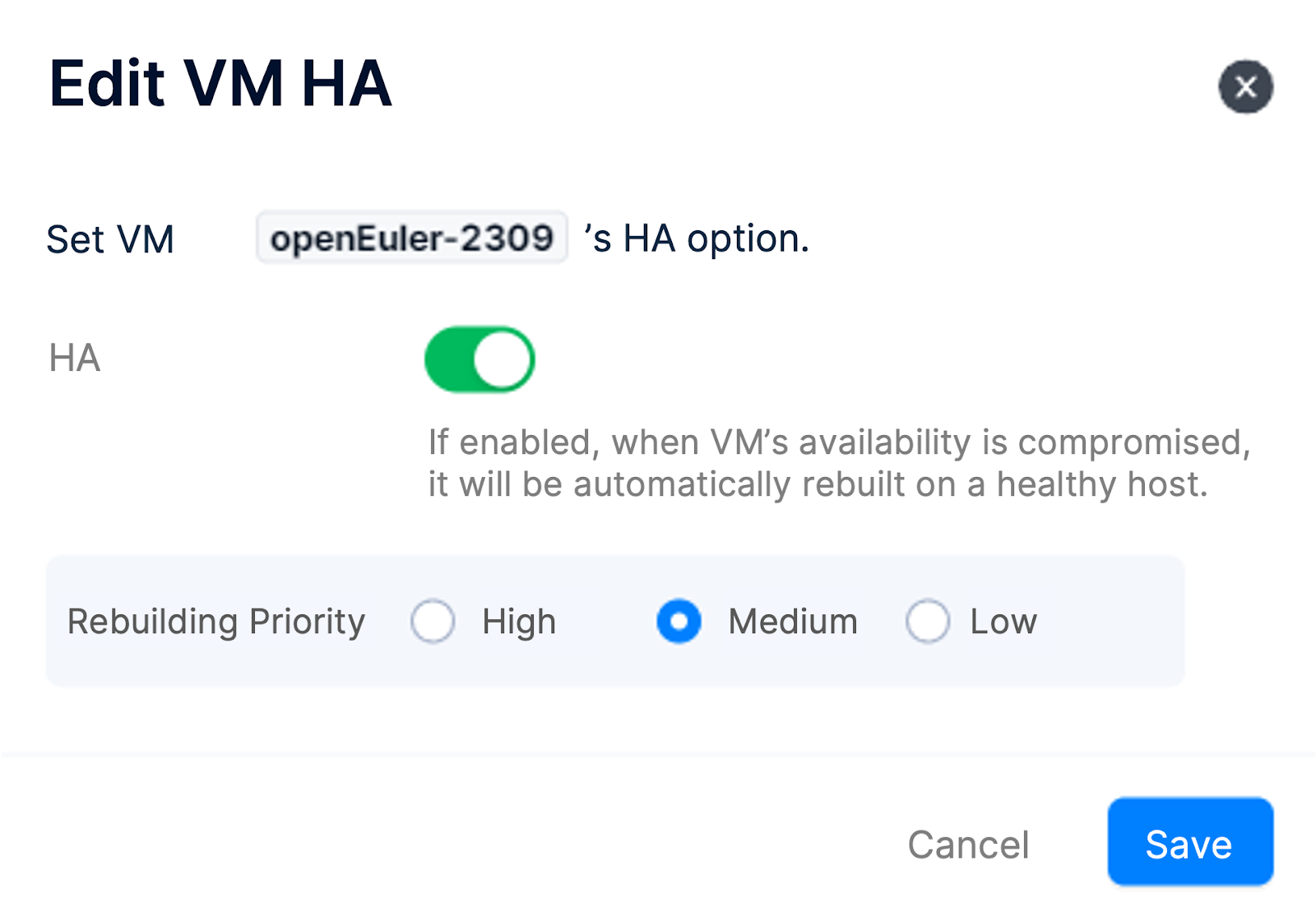
When HA is triggered, all the VMs with HA enabled on the failed node enter the rebuild queue in random order. It does not prioritize VMs carrying critical business applications for recovery. Furthermore, a node failure will leads to a decrease of the overall resources (including CPU, memory, storage resources, etc.). If the remaining cluster resources are too tight to support all the VMs that need to be rebuilt, it may result in rebuilding failure of crucial VMs.
To address this issue, SMTX OS provides VM HA priority feature, which allows users to set three priority levels for VM rebuilding, i.e., high, medium, and low. When HA is triggered, the system rebuilds the VMs according to the priority order, ensuring that crucial VMs are rebuilt first.
3.3 Rack Awareness: Enhancing VM HA Effectiveness
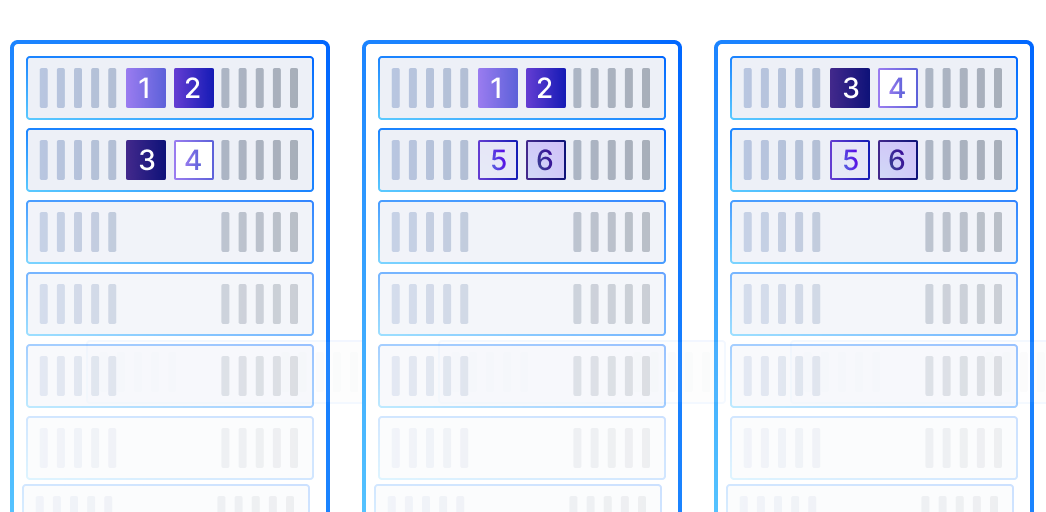
As previously mentioned, SMTX OS places multiple data replicas on different servers, which can withstand server hardware failures and automatically recover data using surviving copies. However, if all these servers are placed in the same cabinet and the shared PDU power supply fails, multiple hosts will go offline simultaneously, potentially causing the failure of multiple replica protection. Rack awareness feature can solve this problem by detecting the server storage topology (placed in different cabinets) and automatically placing data replicas on multiple servers located in different cabinets. Even in the event of a power failure in one cabinet, the system can retrieve the corresponding data copies from servers in other cabinets and trigger the data recovery process.
As previously emphasized, storage availability is the key to VM HA. The rack awareness feature not only enhances cluster availability but also improves the effectiveness of VM HA.
To sum up
Overall, in the initial stage of failure, SMTX OS can accurately identify the failure scenario and carry out corresponding HA reactions to minimize the impact of HA switching. After triggering HA switching, the system will accurately arrange the VMs to be rebuilt on appropriate hosts based on predefined rules, with the rebuilding order being arranged according to the business importance. Moreover, with rack awareness, SMTX OS VM HA can ensure business continuity effectively.
For more information on SMTX OS features and capabilities, please refer to:
SmartX HCI 5.1: Enhanced Features and New Components
Why Enterprises Choose SmartX ELF Virtualization as a VMware Alternative: Five Customer Stories
Improving Resource Utilization: Innovative Implementation of DRS in SmartX HCI
GPU Passthrough & vGPU: Using GPU Application in Virtualization with SMTX OS 5.1
Network I/O Virtualization in SmartX HCI: Virtual NIC, PCI Pass-through and SR-IOV Pass-through
Preserving Data Integrity with Temporary Replica Strategy of SmartX HCI