With technical advancements across four key dimensions—system kernel, hardware acceleration, storage-network aggregation, and storage scalability—SmartX ECP 6.3 delivers 11M+ IOPS and 130+ GiB/s bandwidth that matches tier-1 all-flash arrays.
This level of performance is not the result of simple hardware stacking or parameter tuning, but rather comes from deep architectural enhancements. In this blog, we’ll showcase SmartX ECP 6.3’s real-world performance with test data, and disclose the four innovations behind the performance surge.
Real-World Testing: Performance Under Intel and ITAI Environments
Test Environment
The test environment was built on three-node physical servers running SmartX ECP 6.3 (SMTX OS 6.3). Deployments were conducted separately on Intel x86, Hygon, and Kunpeng platforms. Detailed configurations are as follows:
| Component | Intel Cluster | Hygon Cluster | Kunpeng Cluster |
| CPU | Intel Xeon Gold 6442Y | Hygon C86 7375 | Huawei Kunpeng 920 5250 |
| Memory | 512GB | 480GB | 1TB |
| Storage | 8 × Intel 3.2TB NVMe SSD all-flash array | 4 × Intel 3.2TB NVMe SSD | 4 × Intel 3.2TB NVMe SSD |
| Network | Mellanox ConnectX-7 | Mellanox ConnectX-5 | Mellanox ConnectX-5 |
During testing, ECP’s Boost mode and RDMA high-speed networking capabilities were fully enabled. A 3P6V model (3 nodes, 6 virtual machines) was used to simulate high-concurrency workloads.
Test Results
4K Random Read/Write
4K random read/write is a key metric for evaluating hyperconvergence infrastructure (HCI) storage performance and its ability to support high-concurrency workloads of mission-critical databases (such as MySQL and Oracle Database).
Under a concurrency level and queue depth of (1*1), the performance results are as follows:
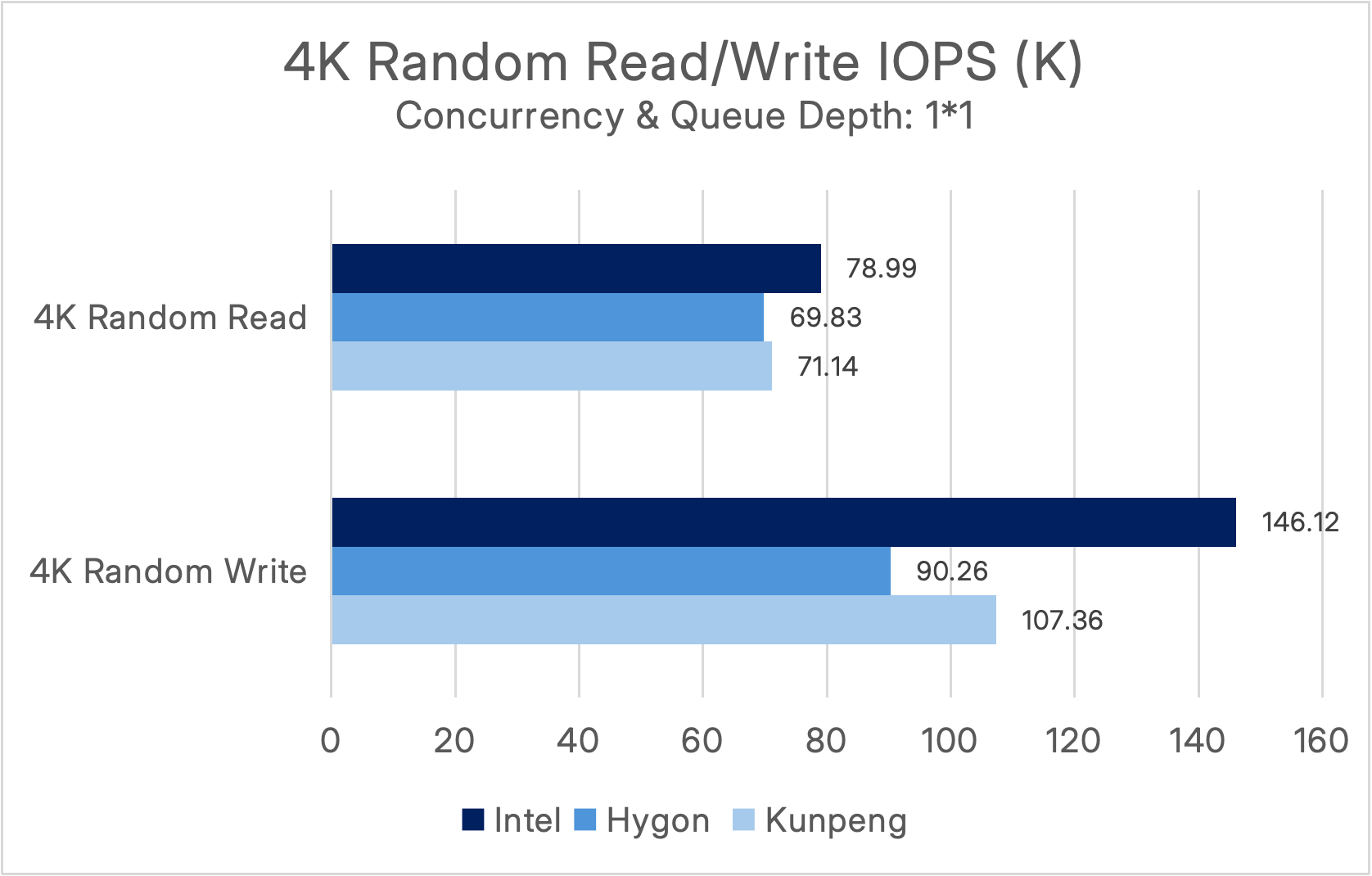
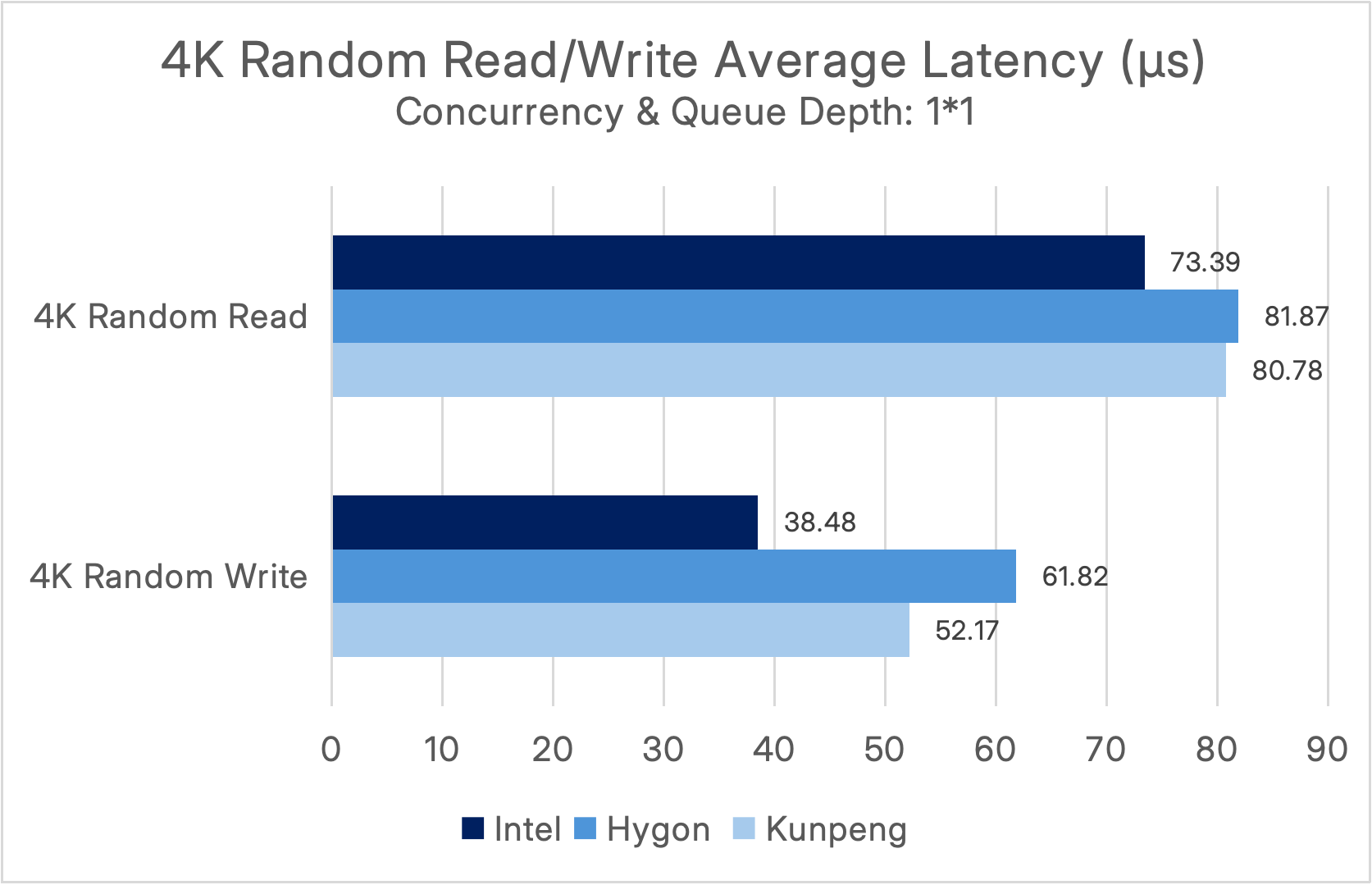
Under a concurrency level and queue depth of (8*64), the performance results are as follows:
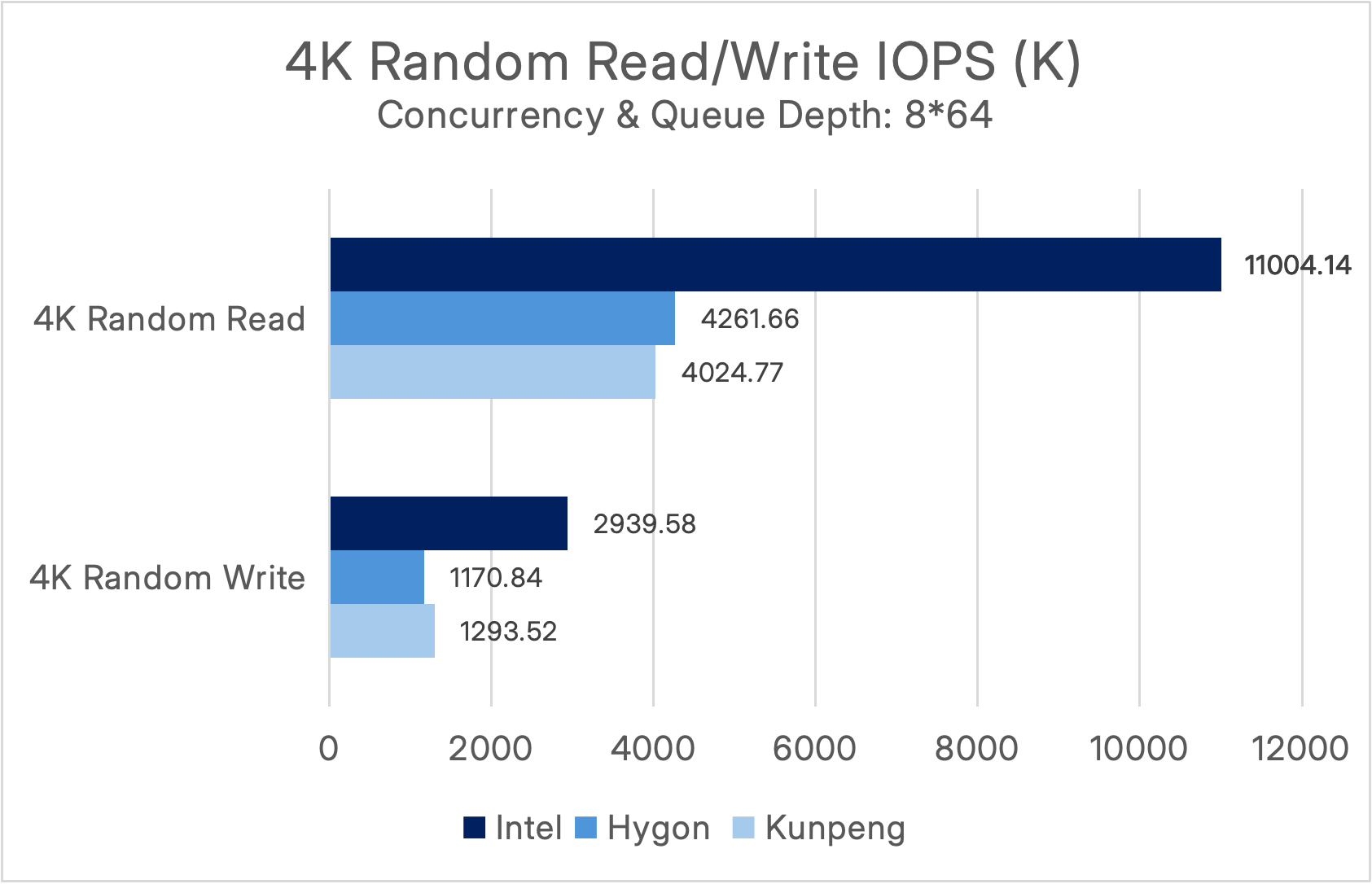
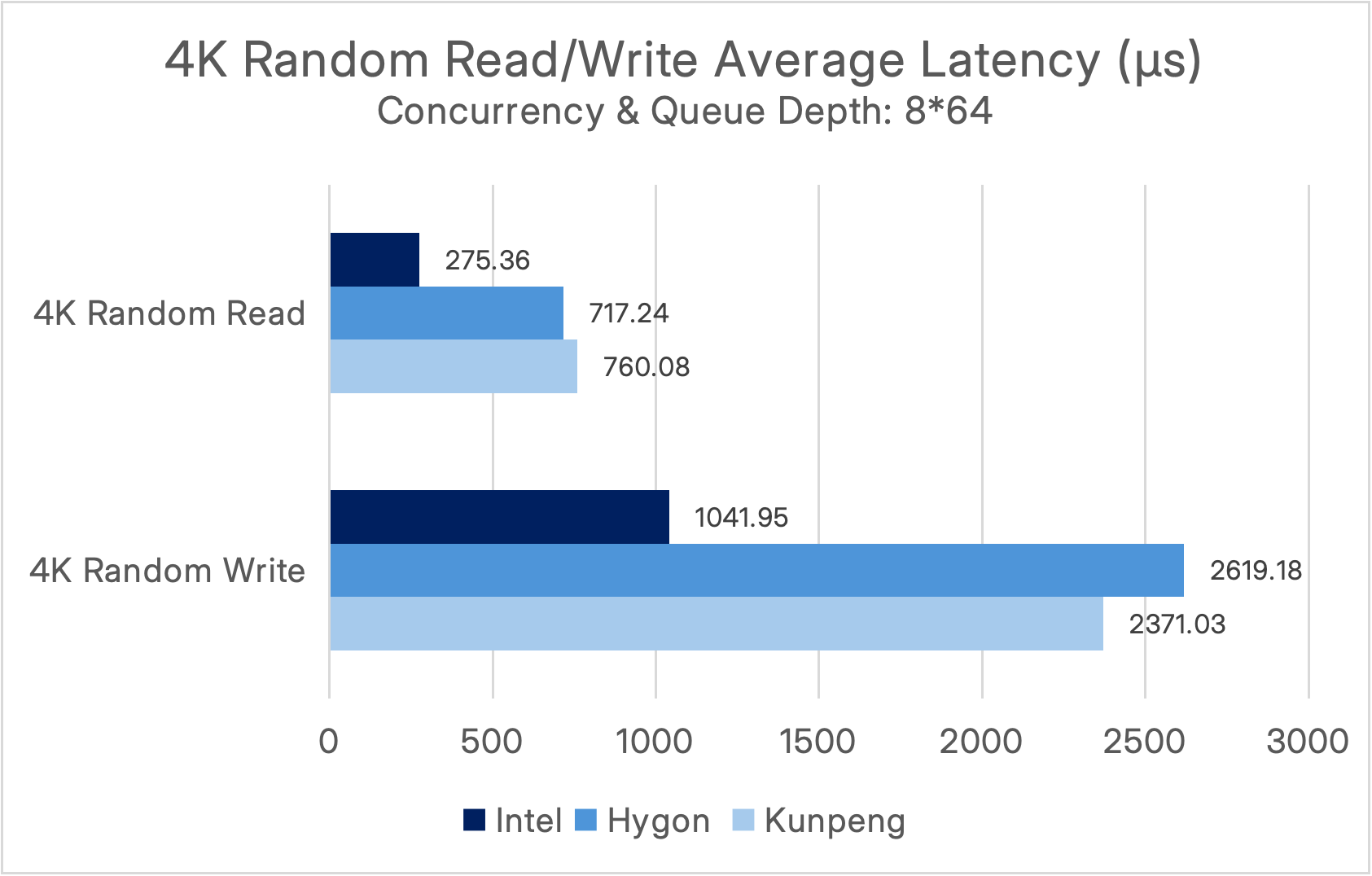
It can be observed that in the Intel environment, under a high-concurrency 4K random read scenario (8×64), SmartX ECP 6.3 delivers exceptional performance exceeding 11 million IOPS. Under the optimal (1×1) condition, it achieves an ultra-low average latency of below 100 μs, fully meeting the high-concurrency, low-latency requirements of mission-critical systems in industries such as finance and manufacturing.
In ITAI environments, both the Hygon and Kunpeng platforms achieved a performance baseline of over 4 million random read IOPS under highly concurrent 4K random read/write workloads (8×64), while random write performance consistently remained at the million-IOPS level. Under the ideal 1×1 scenario, ultra-low average latency was reduced to below 100μs, breaking the industry misconception that “ITAI platforms suffer significant performance degradation.”
256K Sequential Read/Write Performance
256K sequential read/write is a key metric for evaluating the bandwidth capability of HCI storage systems and their ability to support high-throughput workloads such as big data analytics and backup & recovery.
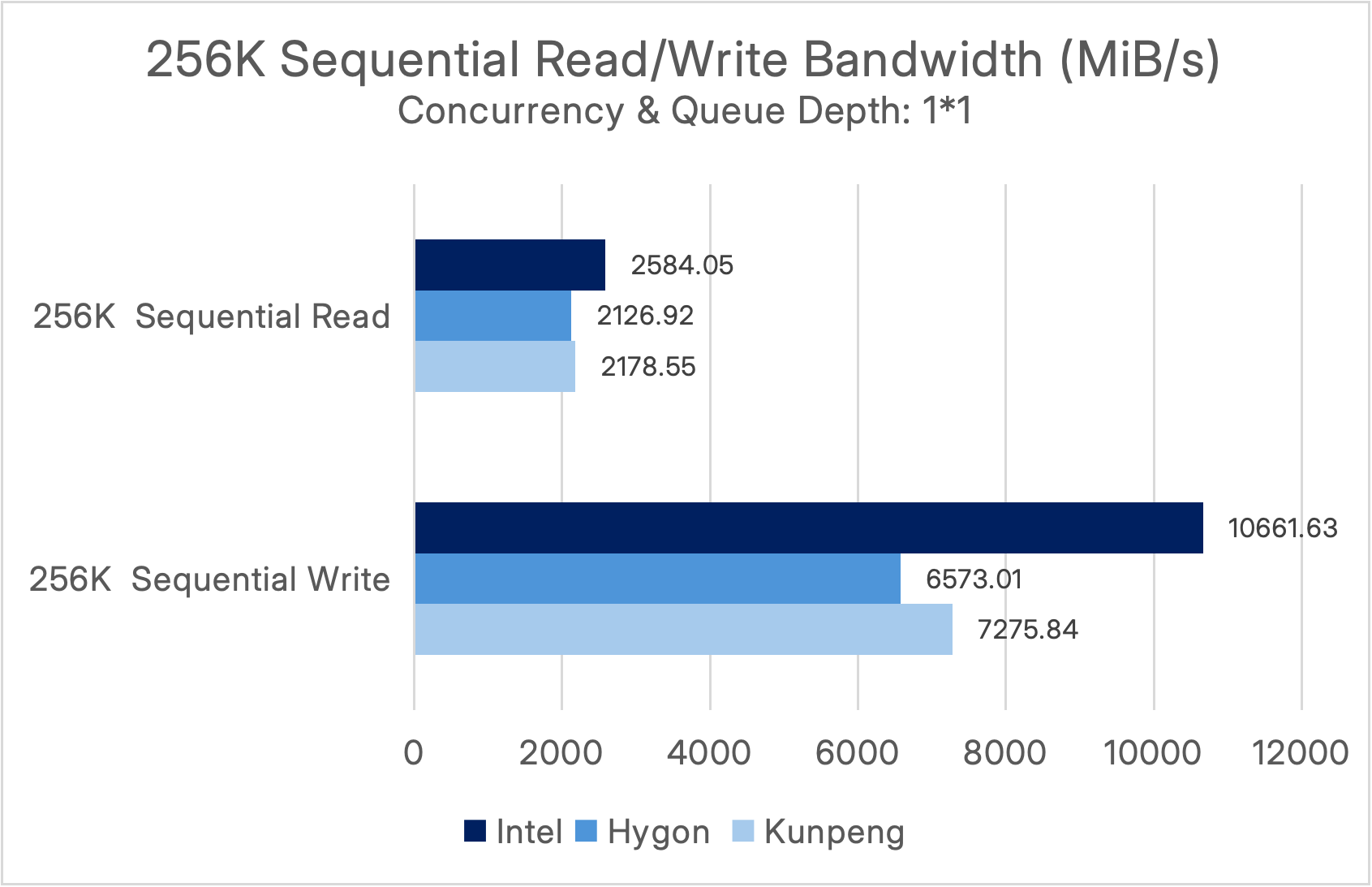
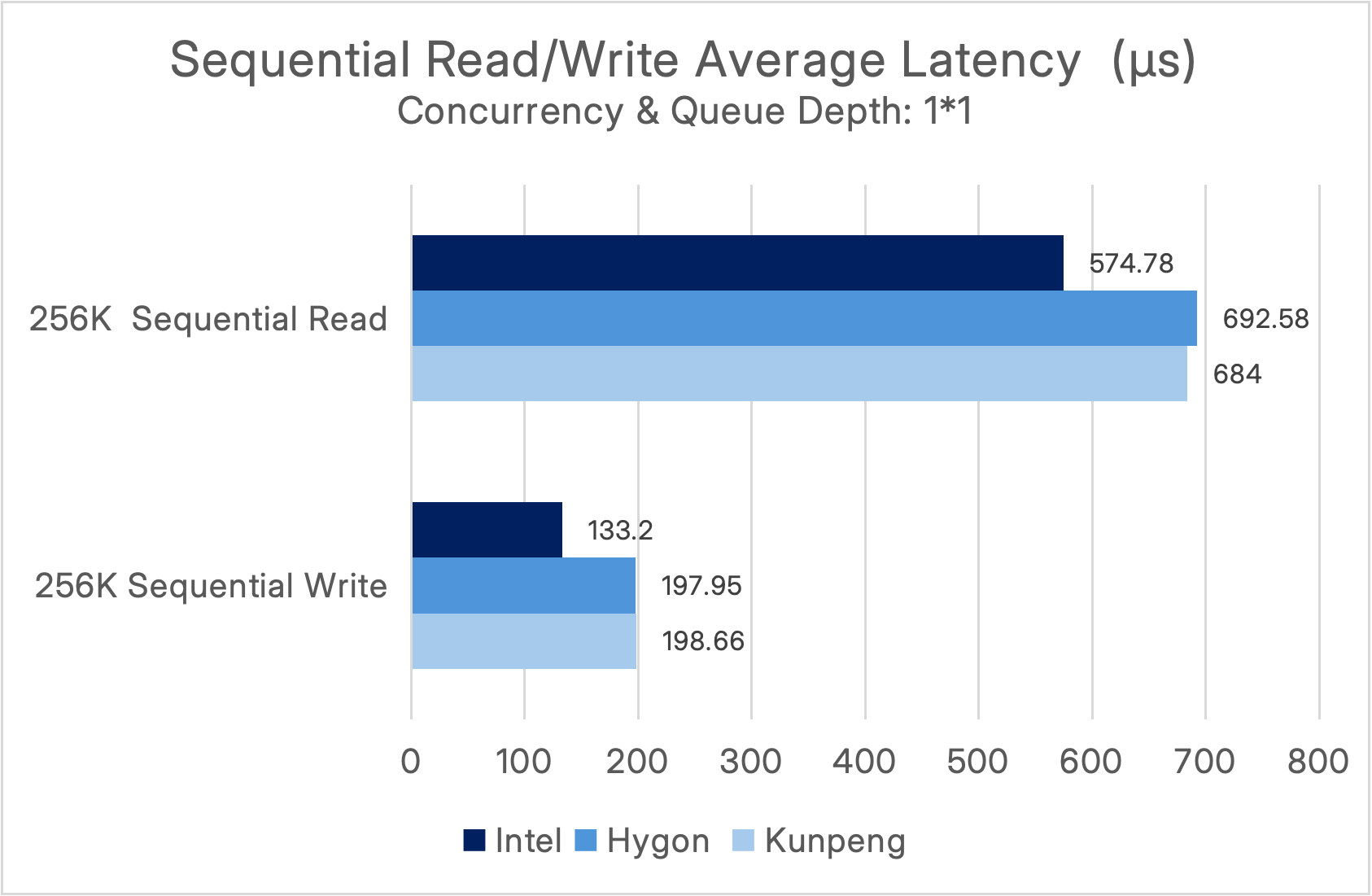
Under a concurrency and queue depth of (1*1), the performance results are as follows:
Under a concurrency and queue depth of (8*32), the performance results are as follows:
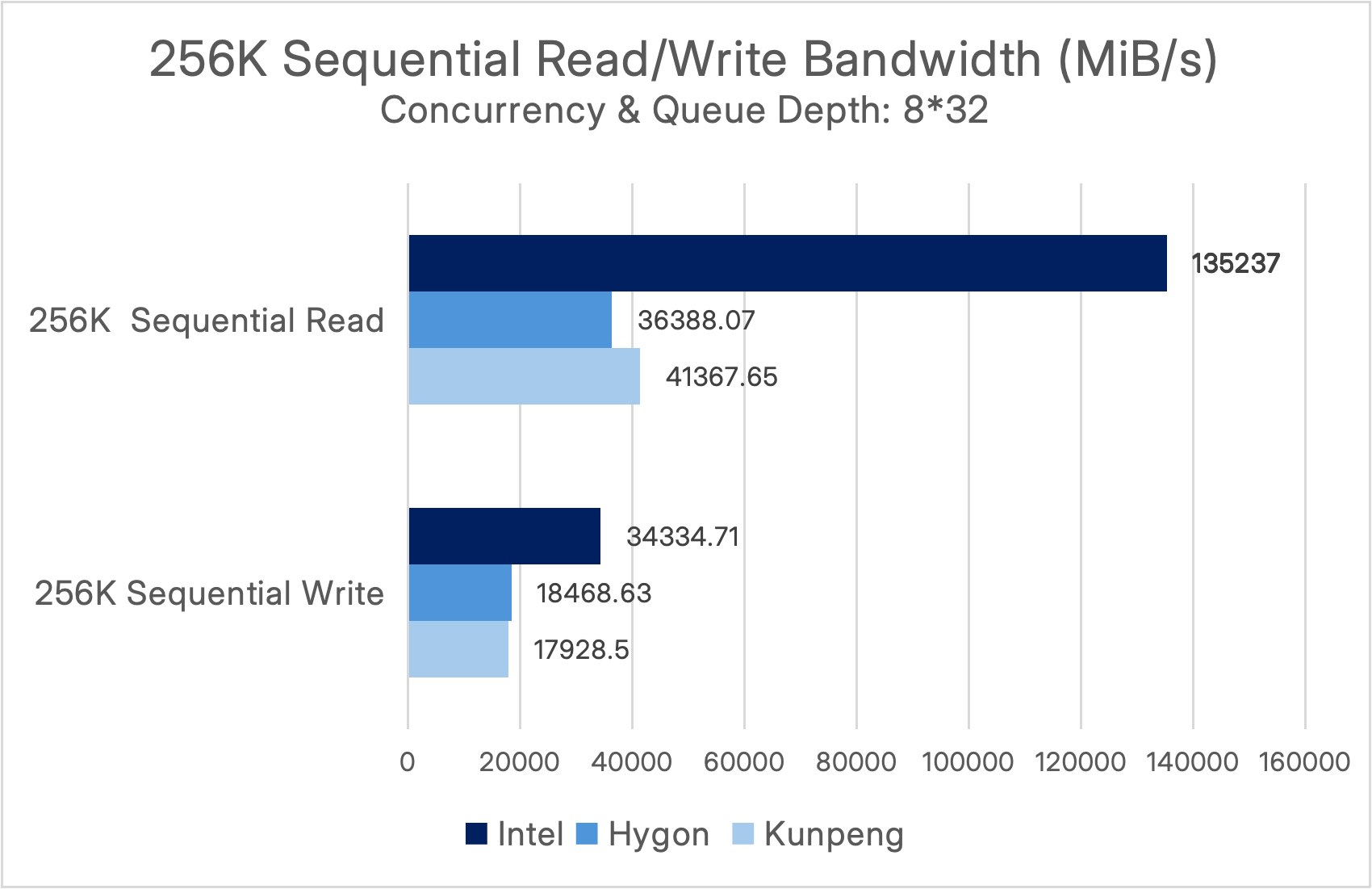
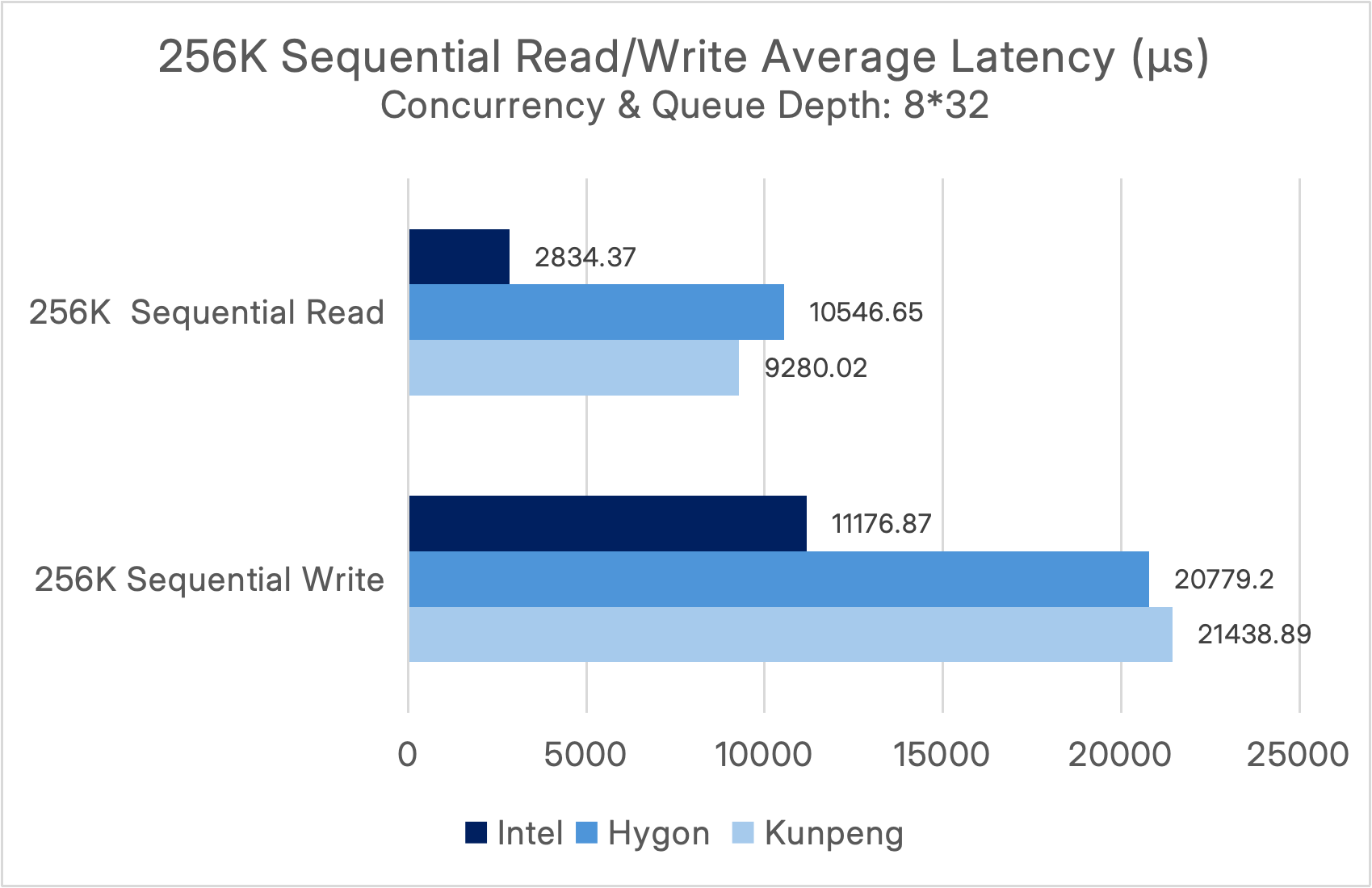
It can be observed that ECP 6.3 achieves sequential read bandwidth exceeding 135,000 MiB/s (~135 GiB/s) and sequential write bandwidth surpassing 34 GiB/s, enabling it to easily handle high-throughput workloads such as big data processing and AI training.
In ITAI environments, the Hygon and Kunpeng platforms both achieved sequential read bandwidths of 36–41 GiB/s and sequential write bandwidths exceeding 18 GiB/s, meeting the bandwidth requirements for big data analytics, backups, and other workloads in ITAI scenarios.
The Four Features Behind Tier-1 All-Flash Performance
IO_uring for Kernel-layer Asynchronous I/O Path: Redefining Storage I/O Efficiency with Less CPU
The traditional Linux storage I/O model is like “running to the courier station personally for every single package”: each I/O request triggers system calls and context switches. Under high concurrency, this not only consumes significant CPU resources but also introduces noticeable latency jitter, becoming a performance bottleneck.
SmartX ECP 6.3 introduces the next-generation IO_uring asynchronous I/O framework to optimize the I/O path at the kernel level:
- Shared Queue Mechanism: The user space and kernel space directly share I/O command queues. This effectively reduces the number of system calls and eliminates frequent “back-and-forth” overhead.
- Zero-Copy Optimization: Data is transferred directly via shared memory without being repeatedly moved between the kernel and the application, significantly lowering latency.
- Asynchronous Batching: Supports batch submission and completion of I/O requests, dramatically reducing CPU utilization under high-concurrency workloads.
- Stable Low Latency: Achieves higher IOPS and smoother latency performance for I/O-intensive workloads like databases.
In simple terms, IO_uring transforms “handling each request individually” into “batch delivery”—achieving higher and more stable storage performance with fewer CPU resources.
Intel DSA (Hardware Data Stream Acceleration): Offloading “Heavy Lifting” to Specialized Hardware
The core value of a CPU lies in running business logic, rather than wasting on “manual labor” such as data copying, relocation, and compression.
SmartX ECP 6.3 leverages the Intel DSA (Data Stream Accelerator)—a hardware acceleration engine built into the latest generation of Intel Xeon CPUs—to achieve precise offloading of computing power:
- Hardware-Level Offloading: Common operations like memory copying, data movement, and reorganization are stripped away from general-purpose CPU computing and handed over to dedicated hardware.
- Releasing Compute for Business: Under the same storage load, the CPU utilization of storage services is significantly reduced, leaving more processing power for core business applications.
- Substantial Bandwidth Boost: With data movement accelerated by hardware, performance gains are exceptionally strong in large I/O and high-throughput scenarios.
- Synergy with IO_uring: The combination of asynchronous I/O framework and DSA forms a “dual-engine” foundation, achieving a 1+1 > 2 effect.
By letting specialized hardware handle data movement tasks, the CPU can focus on core workloads—naturally maximizing overall system performance.
Multi-Link Bandwidth Aggregation: Breaking Single-Link Bottlenecks to Unleash Full NIC Bandwidth
Inter-node communication in traditional HCI is often like a “single-lane highway.” Even with NIC Bonding, traffic is typically restricted to a single-link bandwidth. The redundancy of multiple NICs cannot lead to a higher throughput, resulting in link bottlenecks in high-concurrency scenarios.
SmartX ECP 6.3 adopts user-space multi-link bandwidth aggregation to completely remove this limitation:
- Multiple parallel TCP/RDMA logical links are established between nodes, turning a “single lane” into a “multi-lane highway.”
- Intelligent traffic distribution and dynamic load balancing at the application layer ensure full utilization of every NIC.
- Bandwidth across multiple NICs is truly aggregated, no longer constrained by a single link, enabling linear throughput scaling at the cluster level.
- Combined with RDMA networking, it delivers both high bandwidth and low latency.
With this approach, the network is no longer a performance bottleneck, and the full potential of multiple NICs can be realized.
Multi-Instance Storage Architecture: Elastic Scaling Beyond Single-Process Limits
As cluster size grows and the number of VMs increases, the traditional “single storage process” architecture in HCI acts like a “single service window handling all requests.” This architecture inevitably leads to queue congestion and becomes a performance bottleneck, failing to sustain high-density, high-concurrency workloads.
SmartX ECP 6.3 introduces a multi-instance storage architecture (multiple physical disk pools) to address this at the architectural level:
- Multiple independent storage instances can run on a single node, turning “one window” into “multiple service windows in parallel.”
- Core capabilities—protocol processing, disk I/O, and network forwarding—can scale horizontally on demand.
- I/O streams are distributed and processed in parallel, avoiding single-queue bottlenecks and enabling linear performance scaling under heavy workloads.
- In high-concurrency test models such as 3P6V, the multi-instance storage architecture demonstrates significant performance gains.
Multi-Instance storage architecture ensures that HCI concurrency is no longer throttled by the limitations of a single process, truly enabling a “scale-out, power-up” capability.
From rebuilding the kernel I/O path with IO_uring, to offloading compute with Intel DSA; from breaking bandwidth bottlenecks through multi-link interconnect, to scaling concurrency with a multi-instance architecture—SmartX ECP 6.3 achieves top-tier performance through a comprehensive set of foundational innovations.
Rather than relying on hardware stacking or resource overprovisioning, it optimizes the architecture end to end, delivering stable, predictable performance at scale—this is the key to achieving leading performance within an HCI architecture.
Learn more about the upgraded features and capabilities of SmartX ECP 6.3 from our latest blogs:
SmartX ECP 6.3 Released: Leading the New Standard for Critical Business Support in HCI
Unveiling SmartX ECP 6.3 Upgrades in Availability: Expanding HA to SR-IOV, vGPU, and HCT-Enabled VMs