With the release of SMTX OS 6.1, ZBS (distributed block storage component of SMTX OS and SmartX ECP) has enhanced its storage tiering model by segmenting the cache layer into a cluster-level write cache pool and a node-level read cache pool, allowing users to leverage Erasure Coding (EC) for data redundancy protection under extensive data storage scenarios while improving space utilization. This blog will explain the upgraded cache mechanism and storage I/O path.
Storage Tiering Model of SMTX OS 6.1
Instead of using the LRU (Least Recently Used) algorithm for storage data management, ZBS of SMTX OS 6.1 adopts an enhanced storage tiering model that divides storage devices within a cluster into cache and capacity tiers:
- Cache Tier: It is split into write cache and read cache pools.
- Write Cache Pool (also called Performance Tier): At the cluster level, the write cache pool ensures that newly written data, whether using replication or EC strategy, is initially stored in the write cache as a replica. Even data already offloaded to the capacity tier will also be written to the write cache first when it is newly written to ensure the write performance. For critical applications, users can leverage the volume pinning feature to keep data in the write cache, which helps to prevent performance degradation caused by cache breakdown and ensures consistently high performance.
- Read Cache Pool: A node-level read cache pool that caches frequently accessed data in the capacity tier to improve data read performance and access speed.
- Capacity Tier: Used to store cold data. Data will be stored as a replica or EC according to the redundancy strategy and provisioning type.
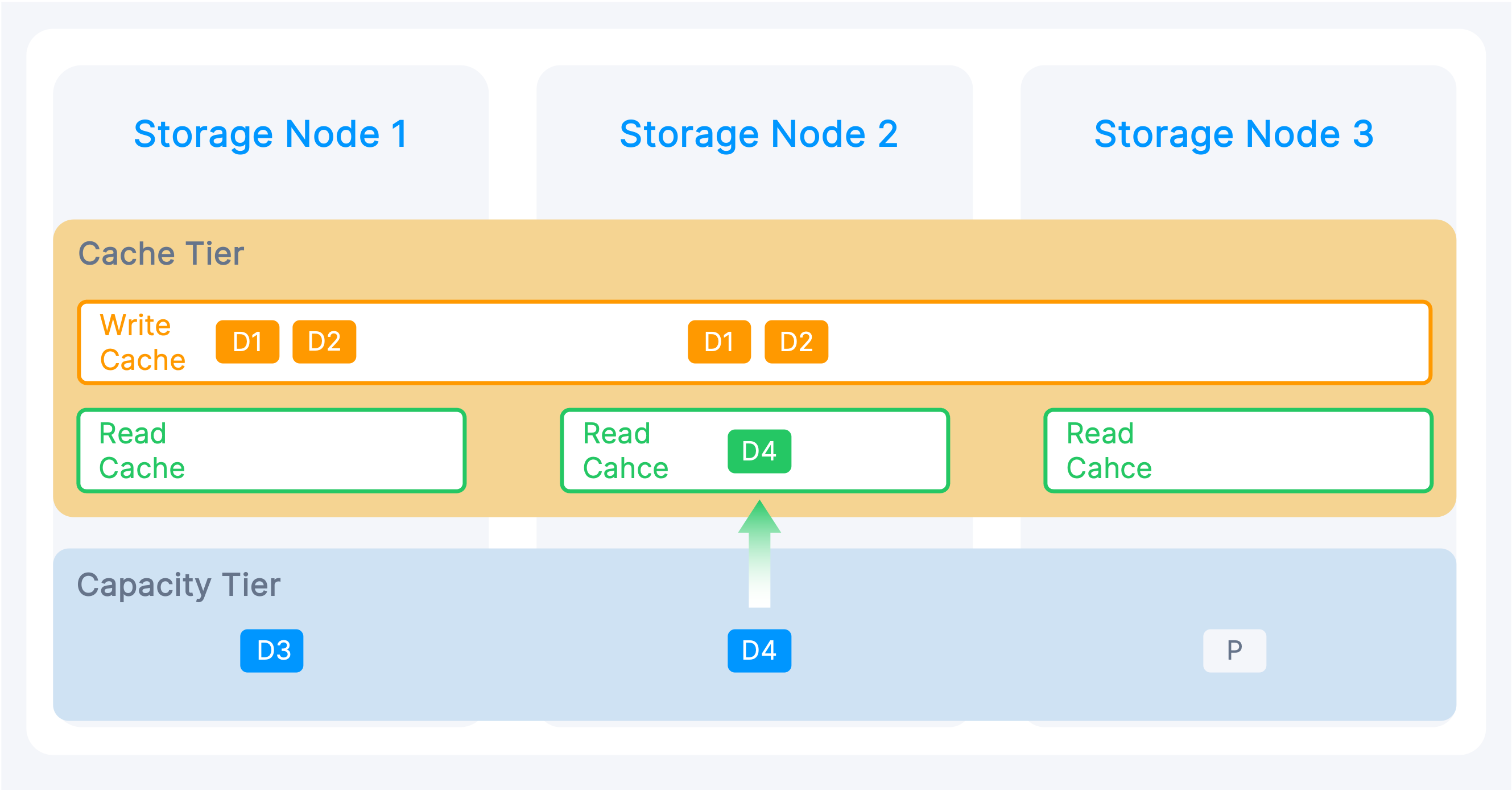
This tiering model allows users to leverage storage-tiering-reliant features like EC to optimize space utilization and lower storage and network overhead. The system can dynamically adjust the ratio of read and write cache pools to further improve cache space utilization and avoid the risk of cache breakdown, ensuring performance for various I/O demands.
I/O Path under Two Data Redundancy Strategies
SMTX OS 6.1 allows users to choose from replication and EC strategies for data redundancy protection. With the new storage tiering model, ZBS’ storage I/O path differs slightly when using different data redundancy strategies.
Using Replication for Data Redundancy Protection
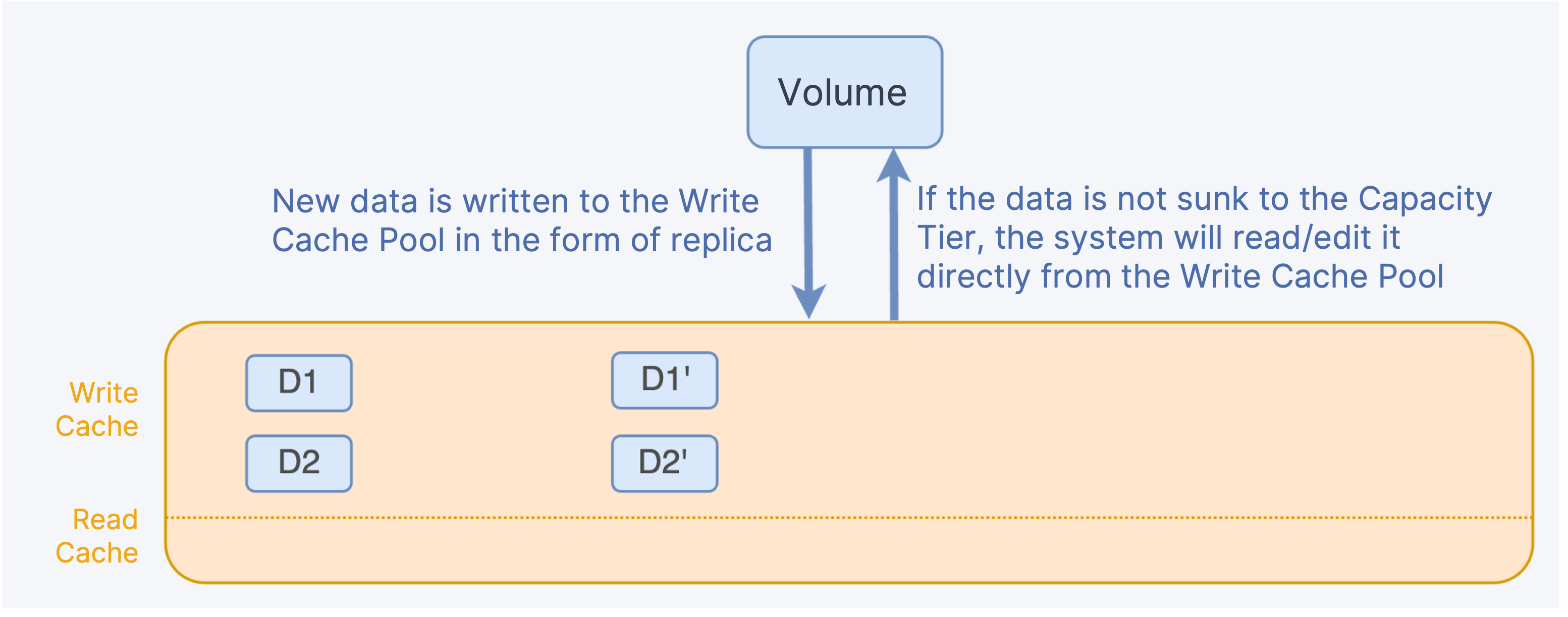
New data is written to the Write Cache Pool as a replica. If the data is not sunk to the Capacity Tier, the system will read/edit it directly from the Write Cache Pool.
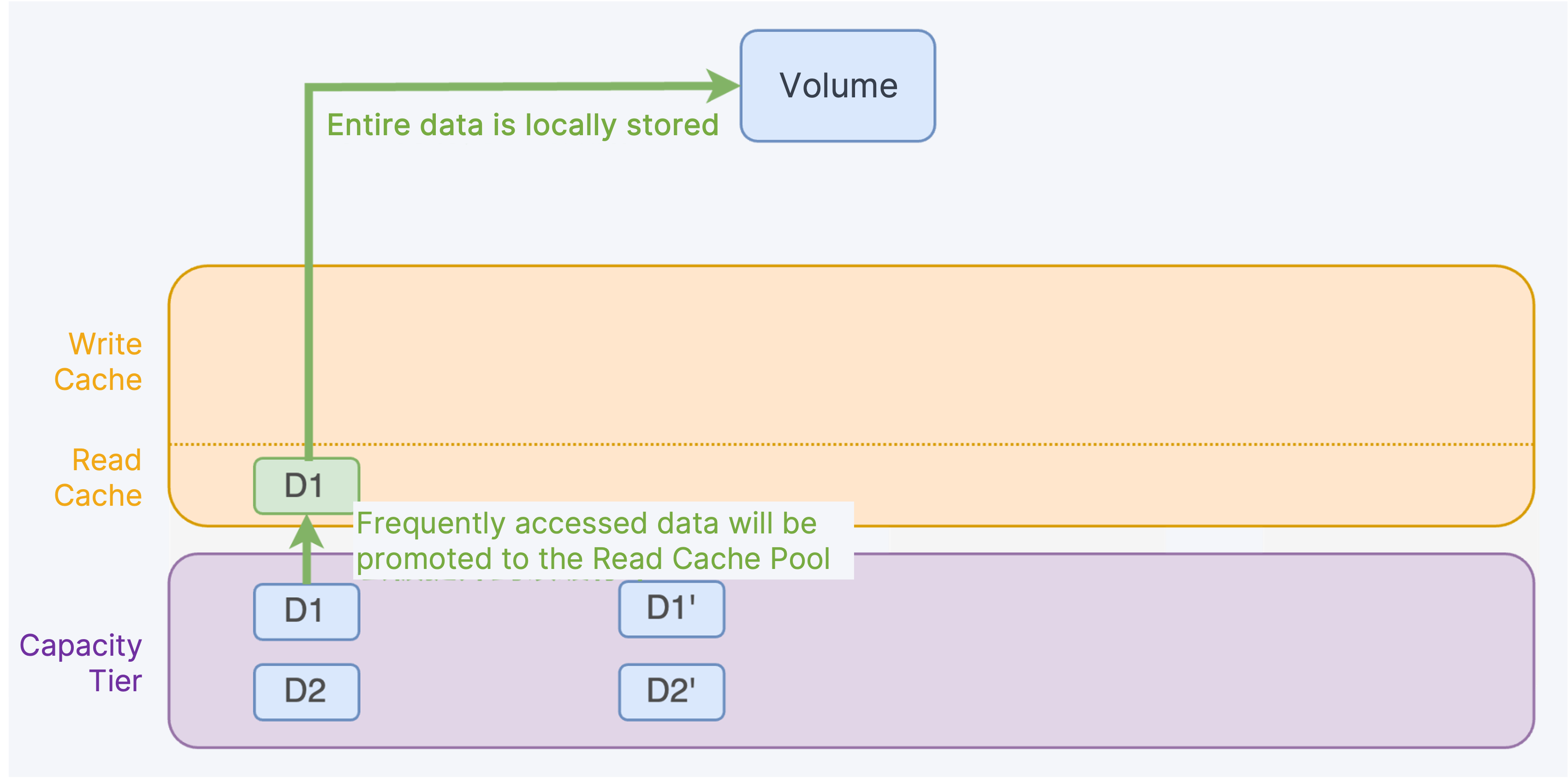
If the system needs to read data that was sunk to the Capacity Tier, frequently accessed data will be promoted to the Read Cache Pool, and as local storage contains the entire data volume, the system can read the entire data from the local Read Cache Pool.
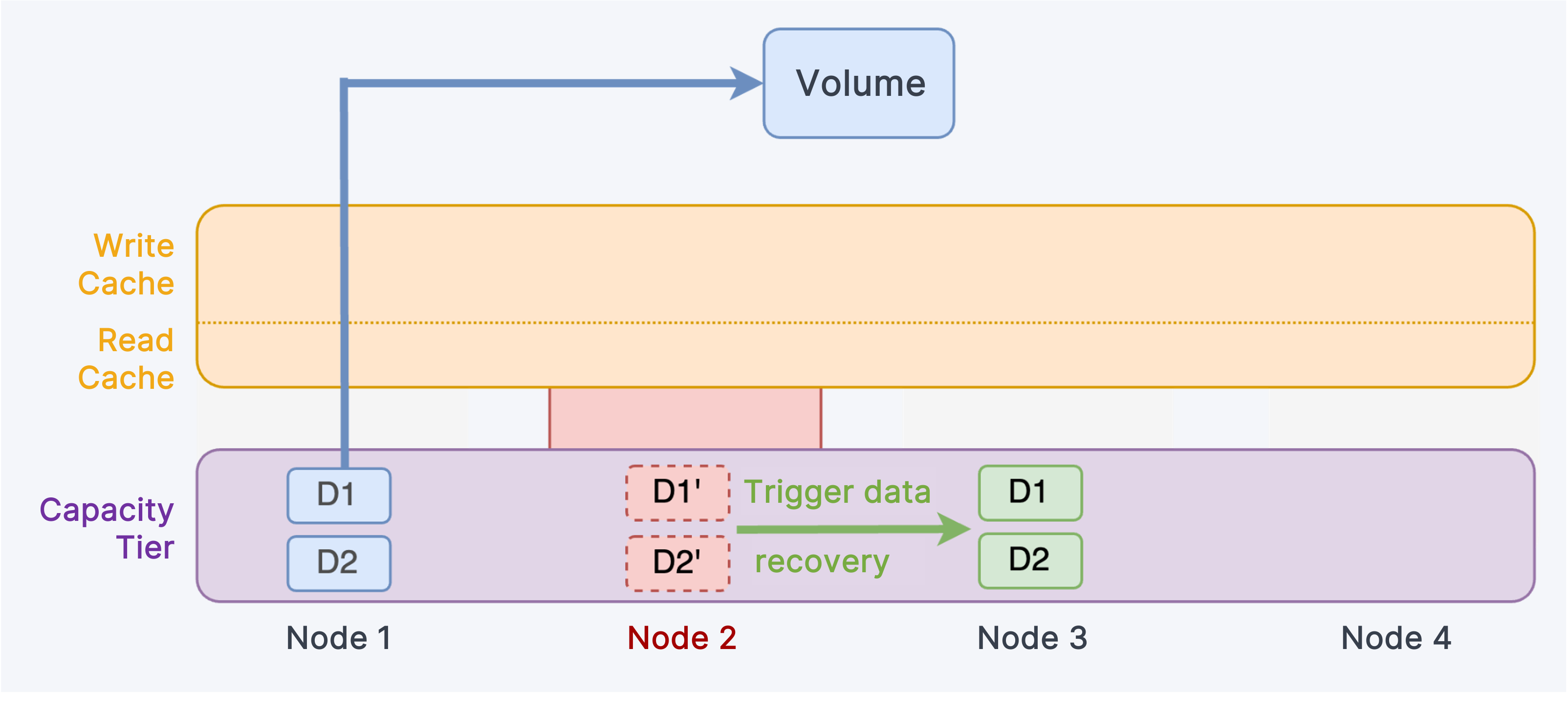
In case of server failures, the system will read healthy data replicas from the Capacity Tier while the abnormal data replica automatically triggers data recovery on the other health node. If the healthy replica is not stored in the local node, the system needs to read across nodes, which will cause a performance decline.
Using EC for Data Redundancy Protection
Similar to the replication strategy, when using EC for data redundancy, new data is written to the Write Cache Pool in the form of a replica (2 replicas when m = 1, 3 replicas when m ≥ 2), with each replica allocated to different nodes. Subsequently, based on data access frequency, the system calculates parity blocks for infrequently accessed data and writes the data blocks and parity blocks to the capacity tier. Taking EC 2+1 as an example, every 2 data blocks and 1 parity block form an EC stripe, with the coded blocks within the same stripe distributed across different nodes.
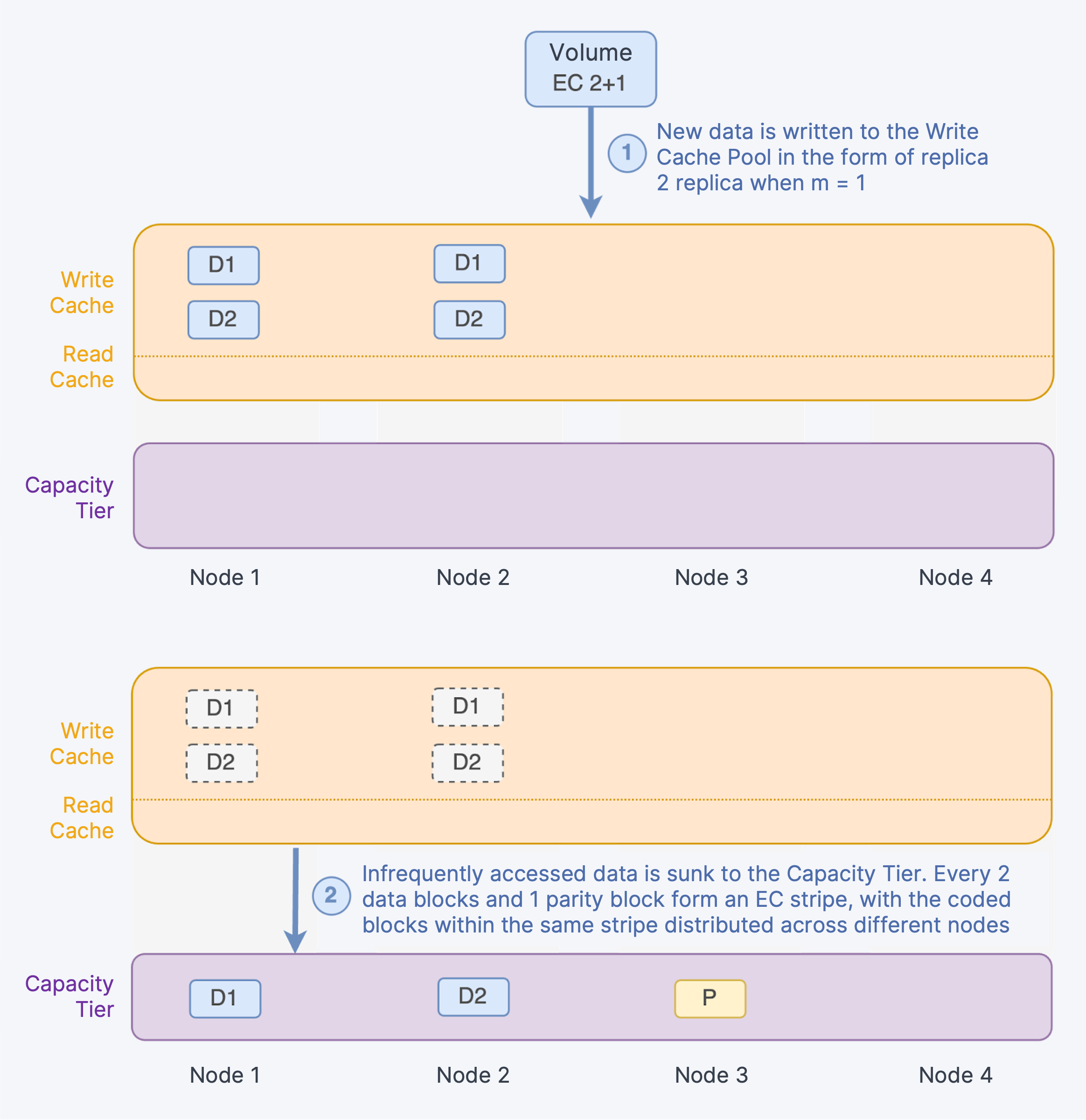
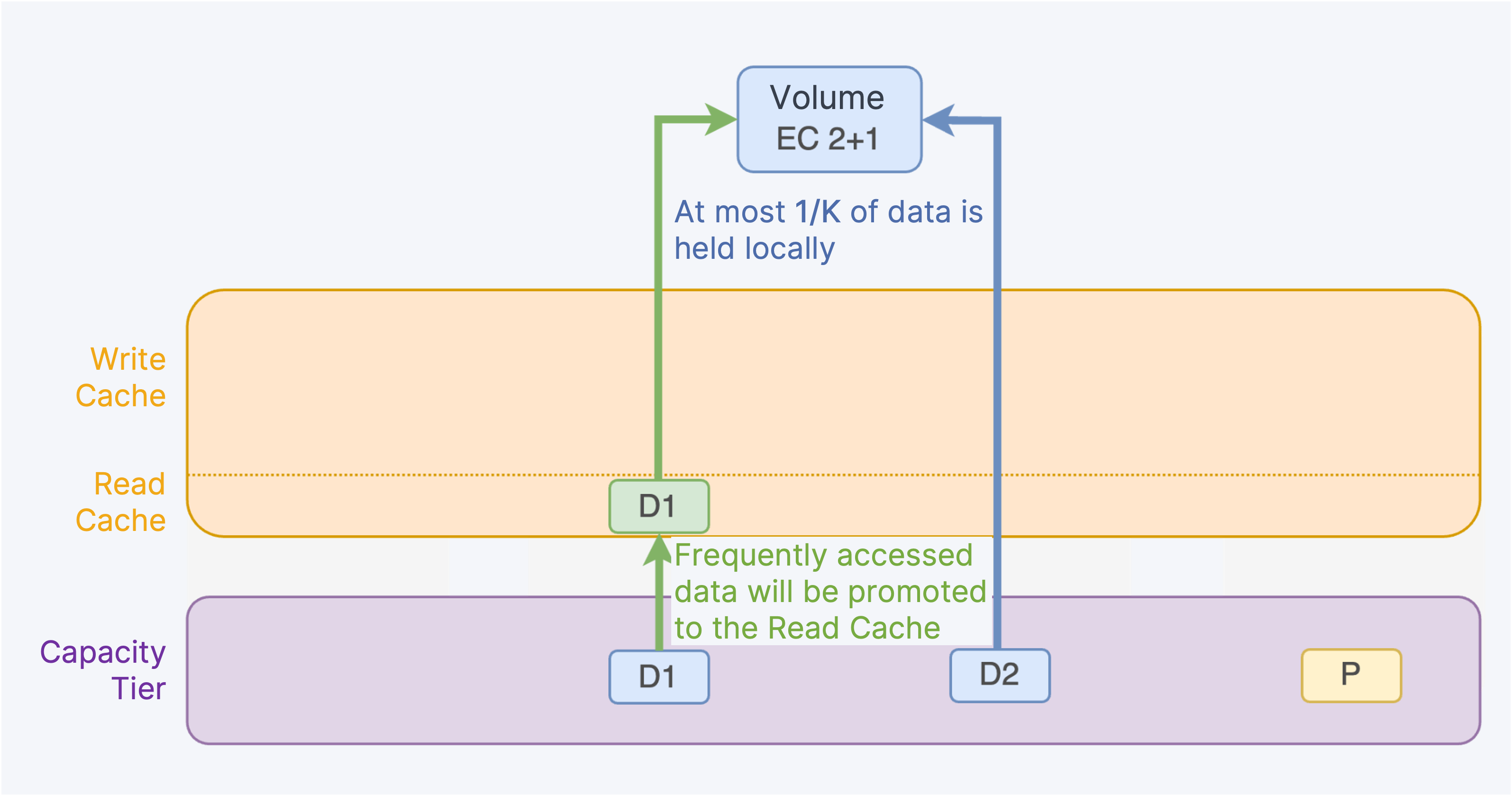
When reading data, if the data resides in the Cache Tier, the system will directly read it. If the data is in the Capacity Tier, the system will read the EC data blocks. Frequently accessed blocks will be promoted to the Read Cache Tier to ensure data reading performance. However, with the EC strategy, at most 1/K of the data is held locally, while the rest must be read across nodes. Therefore, even if the data is promoted to the read cache layer, the read performance will still be lower than that before the data was sunk to the Capacity Tier, due to cross-node access.
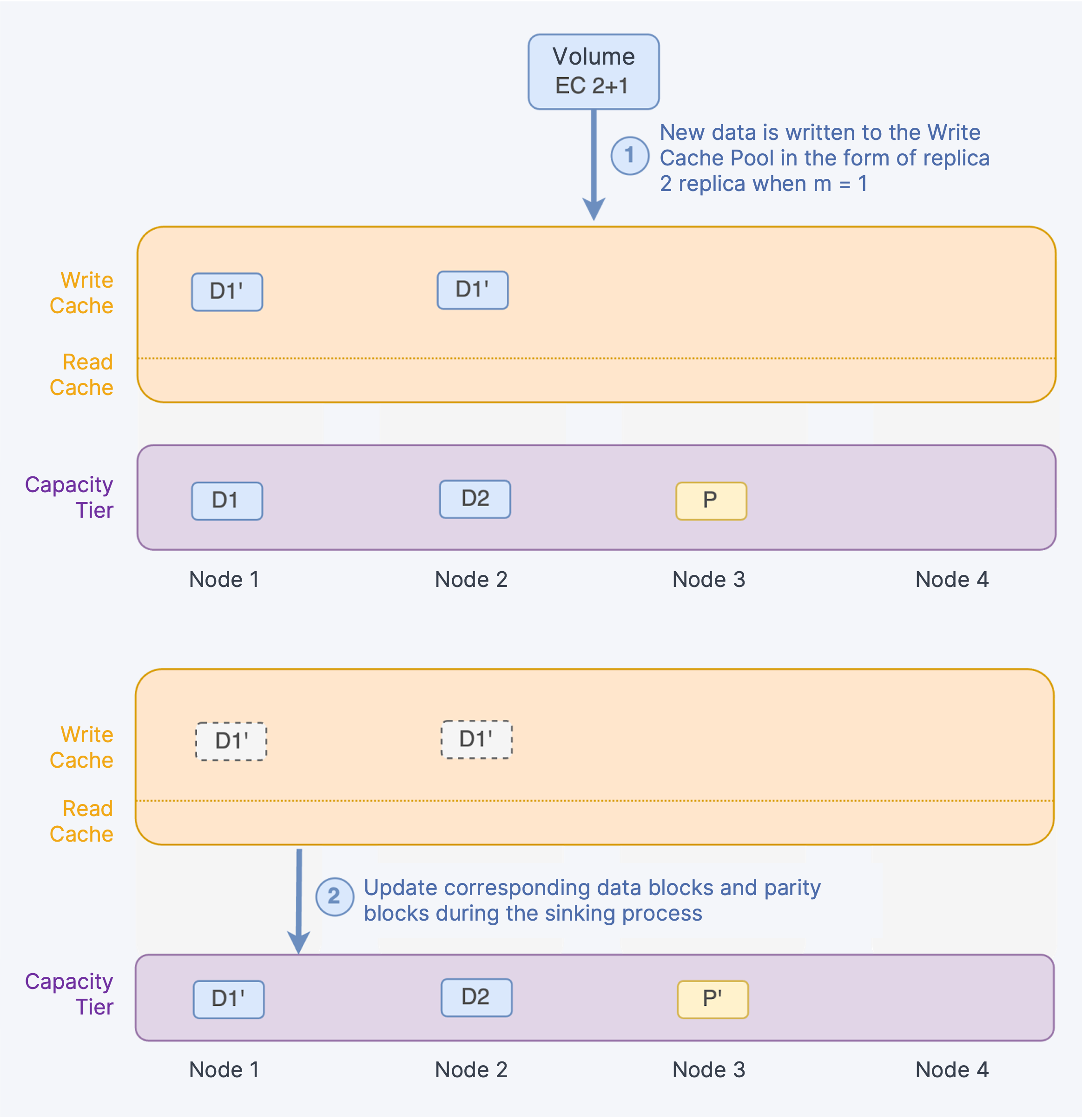
When editing data, if the data resides in the Cache Tier, the system will directly modify multiple data replicas. If the data has already been sunk to the Capacity Tier, the new data is first written to the Write Cache Tier as replicas and then updates all/corresponding data blocks and parity blocks during the sinking process.
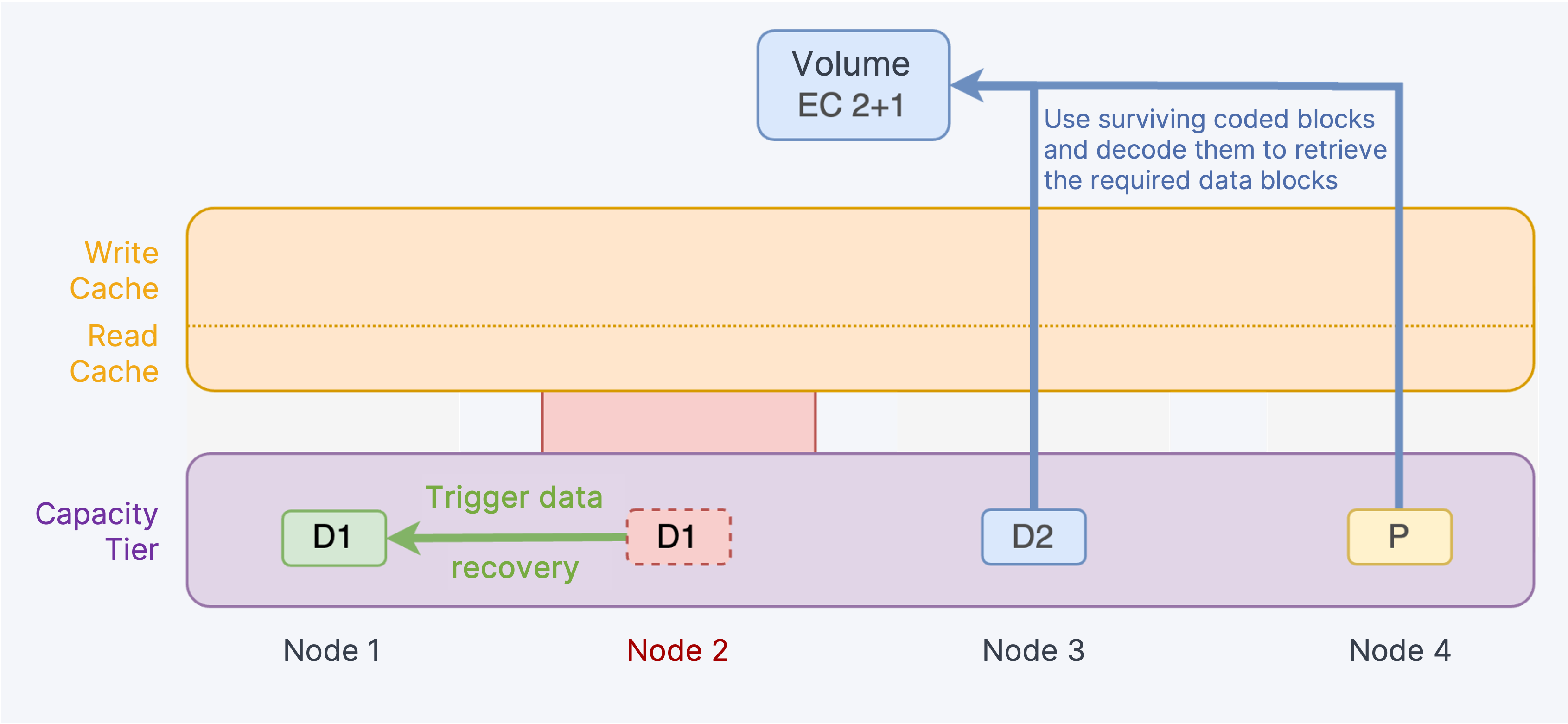
In the event of node failures, the system uses surviving coded blocks to reconstruct the lost coded blocks and places them on nodes that do not already contain blocks from the same stripe. During this time, data blocks cannot satisfy read requests. The system will attempt to randomly read k data blocks or parity blocks from other nodes in the stripe and decode them to retrieve the required data blocks.
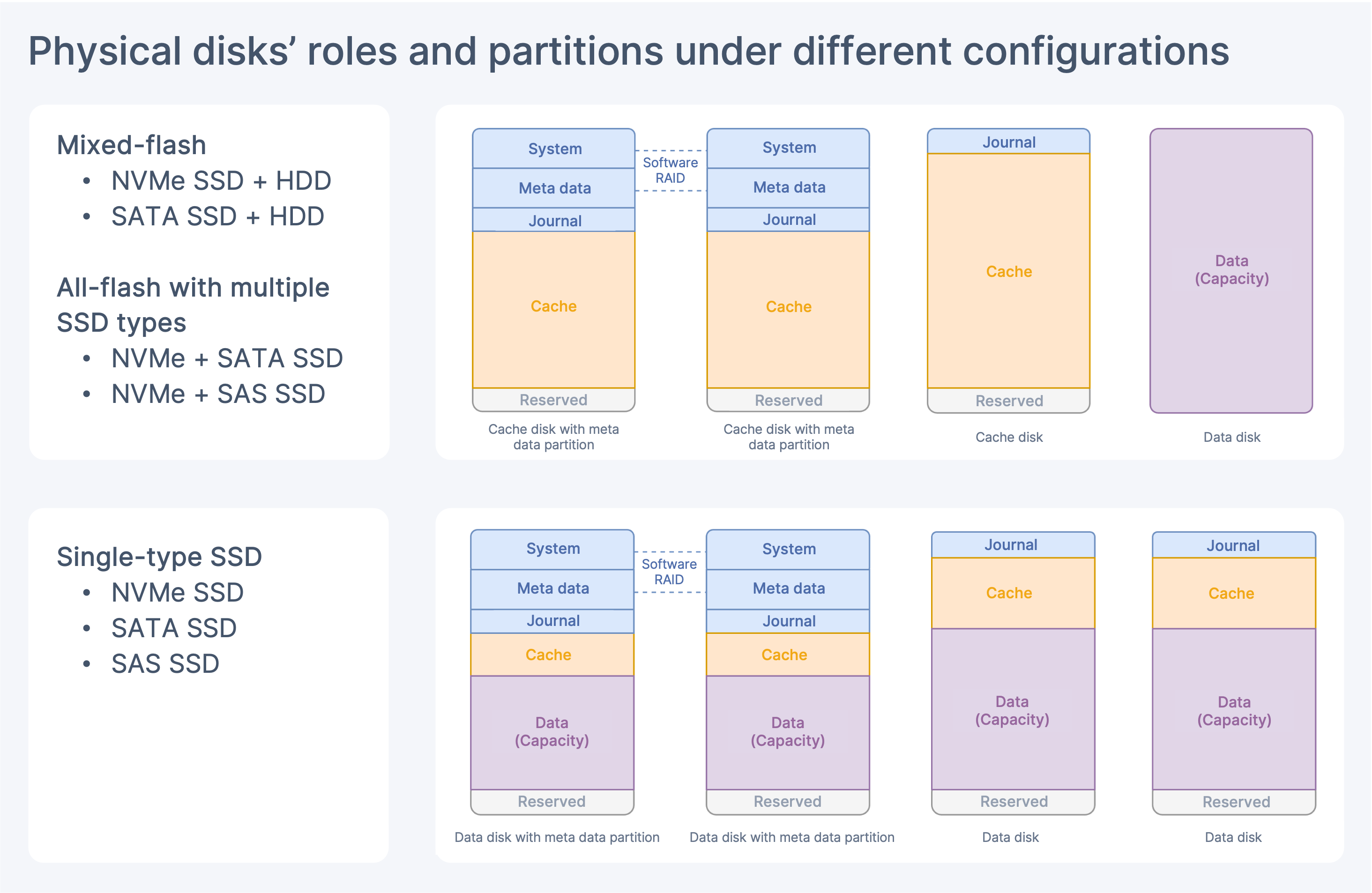
Physical Disk’s Partition under Storage Tiering Model
- Mixed-flash or all-flash with multiple SSD types: High-speed storage media will serve for cache and low-speed media for capacity storage. Each cache disk is internally divided into read and write caches.
- Single-type SSD: All physical disks allocate a portion for caching, with the rest used for capacity, to maximize the performance of all physical disks. In this case, the cache portions are all write caches that organize the data of EC volumes. The data of EC volumes are first written to the write cache before being sunk to the capacity tier. Replica volumes, on the contrary, will be read and written directly through the capacity tier instead of passing the cache tier.
You may also interested in:
VMware vs SmartX: Distributed Storage Caching Mechanism and Performance Comparison
VMware vs SmartX: I/O Path Comparison and Performance Impact
VMware vs SmartX: Snapshot Mechanism and I/O Performance Comparison
SMTX File Storage in HCI 6.0: Providing Diverse Data Storage Services with One Platform
SmartX Releases HCI 6.0 to Enhance Enterprise Cloud Platform