Enterprise IT O&M engineers often have to replace or upgrade server hardware under the following circumstances:
- The server’s warranty is about to expire: Typically, in the financial service industry, servers in the production environment often have a 3-to-5-year warranty. Beyond this lifespan, servers should be replaced to avoid unexpected downtime.
- The server’s maintenance costs have increased: As a server ages, its performance and stability may drop significantly, resulting in increased maintenance costs like manpower and hardware resources.
- The server no longer meets business needs: As business grows and demands change, aged servers may no longer meet current business needs.
One of the key challenges is ensuring the stability of mission-critical services during the hardware replacement. With SmartX HCI, O&M staff can achieve seamless replacement of HCI servers through two solutions: rebuilding the cluster on a new server, and rollingly replacing servers in the same cluster.
In this blog, we will dive into these two solutions and provide users with implementation suggestions through an in-depth comparison of their use cases.
Seamless Replacement of HCI Servers
Solution 1: Rebuilding the Cluster on A New Server
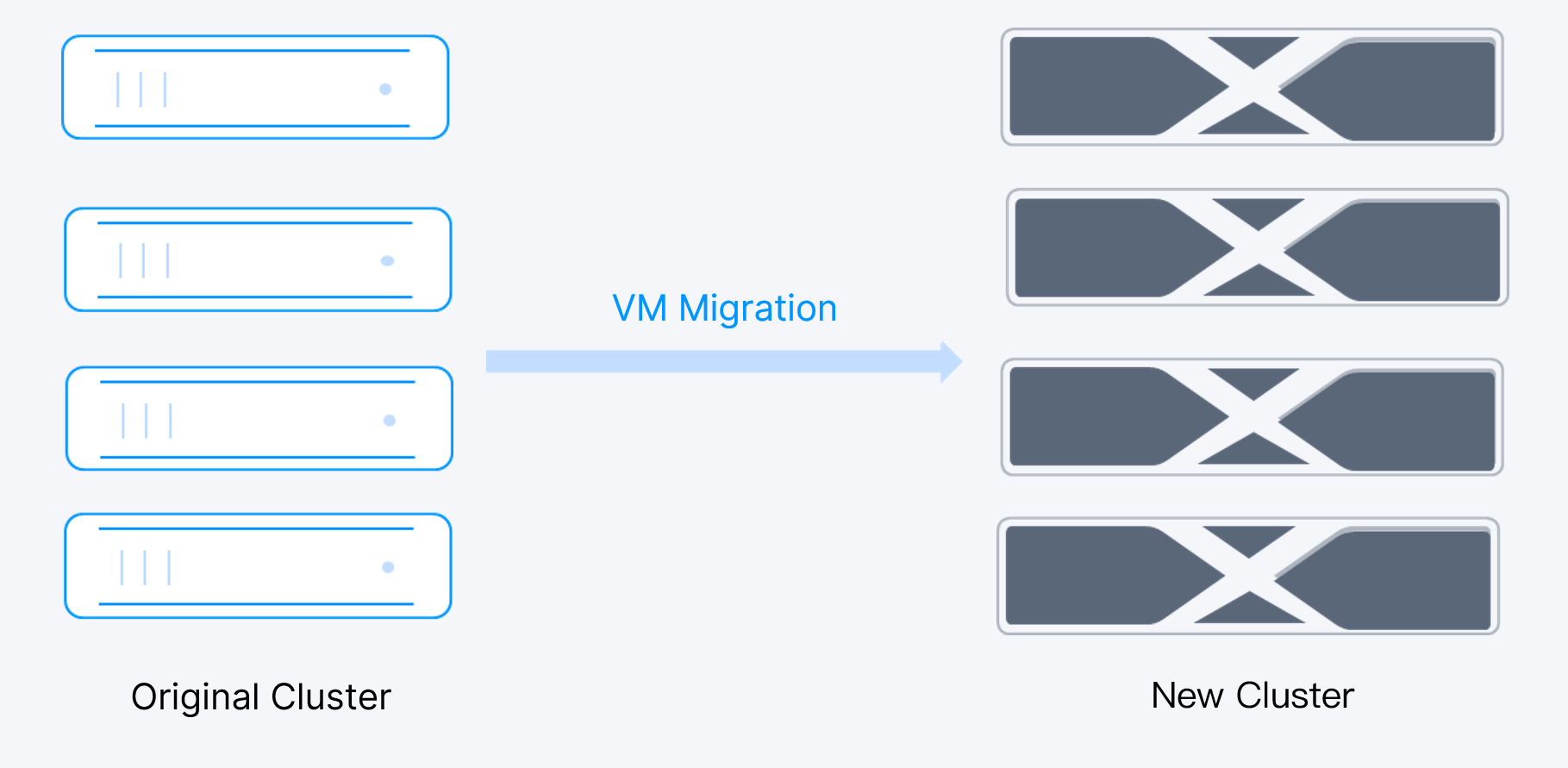
After building a new cluster on the new server, users migrate the VMs from the original cluster to the new one without interrupting business services, thus achieving a smooth server replacement.
Solution 2: Rollingly Replacing Servers in the Same Cluster
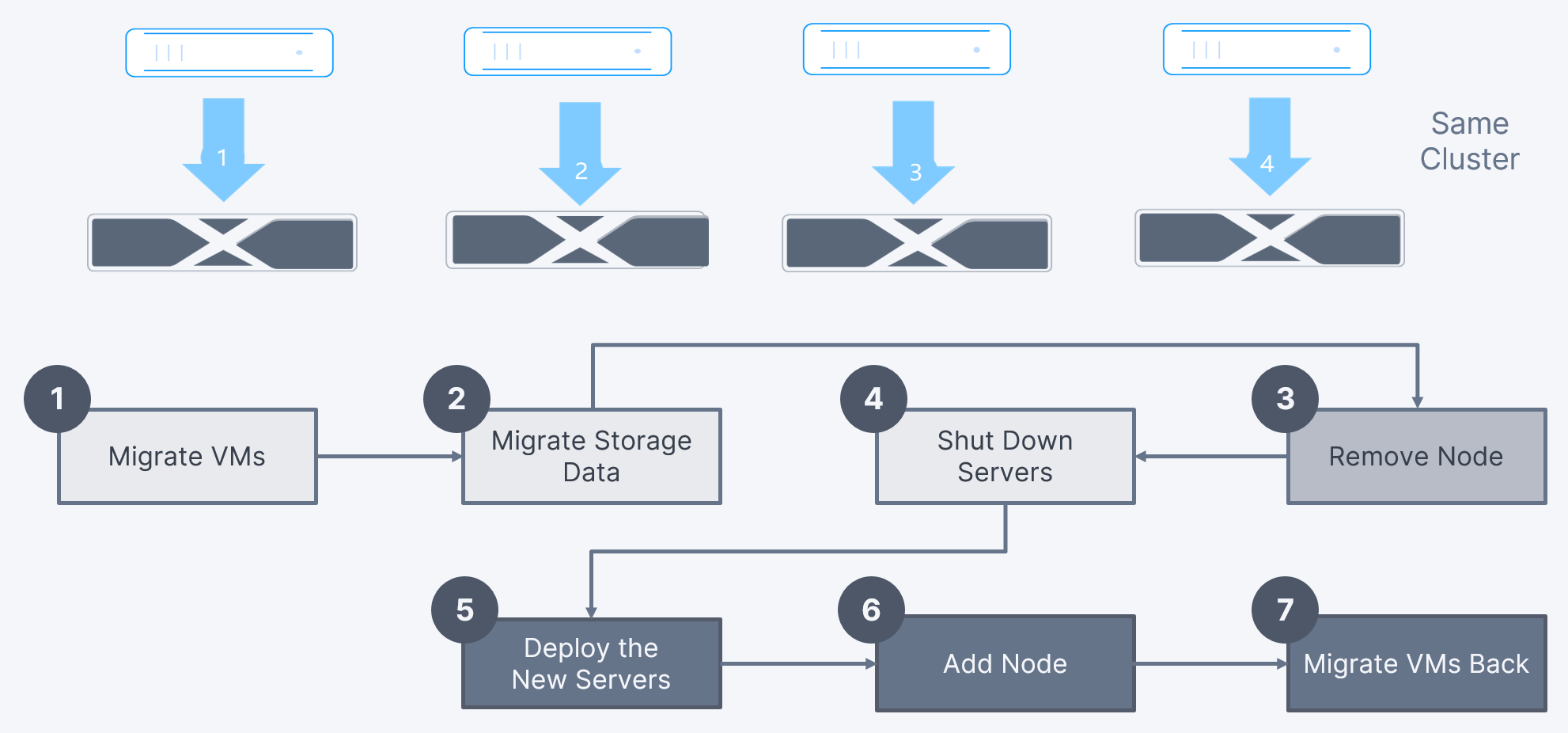
This solution allows users to sequentially replace servers in the same cluster after migrating VMs to other nodes. The steps are as follows:
1. Migrate VMs: Migrate VMs from the original node to other nodes in the cluster.
2. Migrate storage data: Migrate storage data from the original node to other nodes in the cluster.
3. Remove nodes: Remove the original node from the cluster.
4. Shut down the original server: Power off and remove the original server.
5. Deploy the new server: Deploy and power on the new server.
6. Add nodes: Add the new server nodes to the cluster.
7. Migrate VMs back: Migrate the VMs back to nodes on the new server.
To learn more about how to use SmartX HCI for server hardware rolling replacement, please refer to How to achieve seamless and zero-downtime upgrade of IT infrastructure software and hardware?
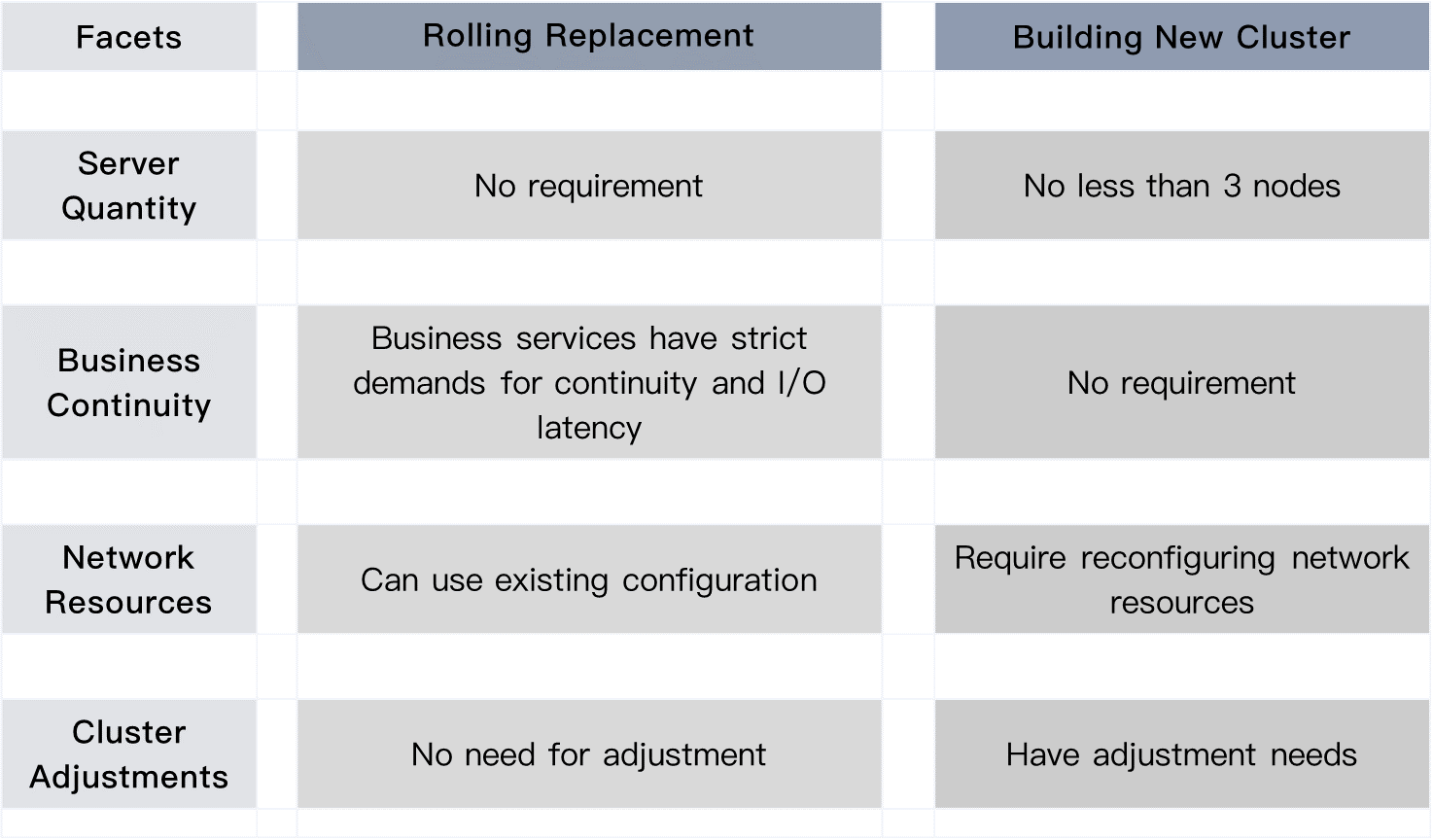
Comparison of Two Solutions
Users can adopt both solutions for server replacement. The question is: How should enterprises make the right choice between them? It’s important to consider the advantages and disadvantages associated with each option given different business demands.
Business Continuity
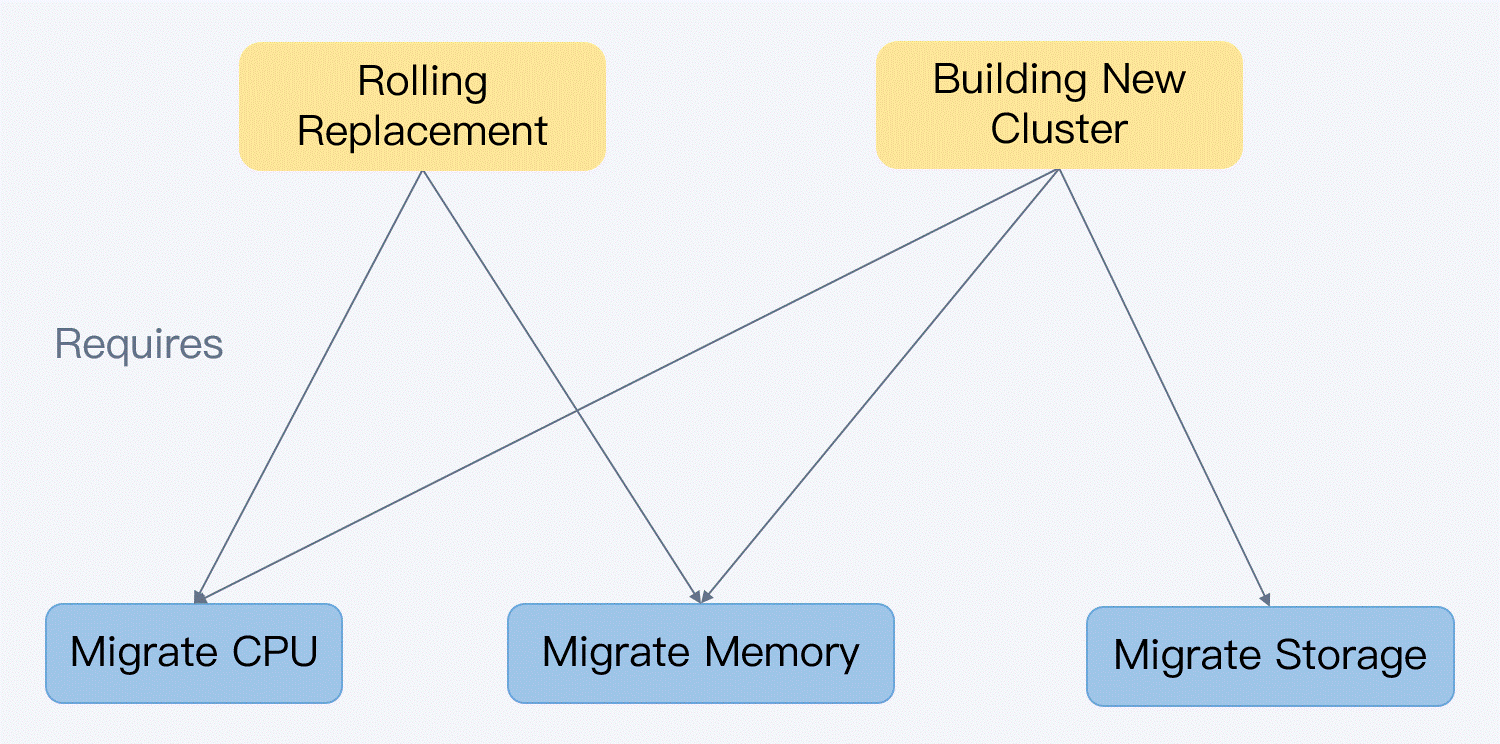
When replacing server hardware, it is essential to ensure that business services are unaffected.
Both solutions involve VM migration. However, in the rolling replacement approach, migration is limited to compute resources, whereas in the new-cluster solution, it encompasses both compute and storage resources. While both methods can achieve uninterrupted VM operation, the rolling replacement solution is more suitable for business services that prioritize continuity and low I/O latency. This is because it eliminates the need for storage migration, which can be advantageous in maintaining seamless operations.
Server Quantity
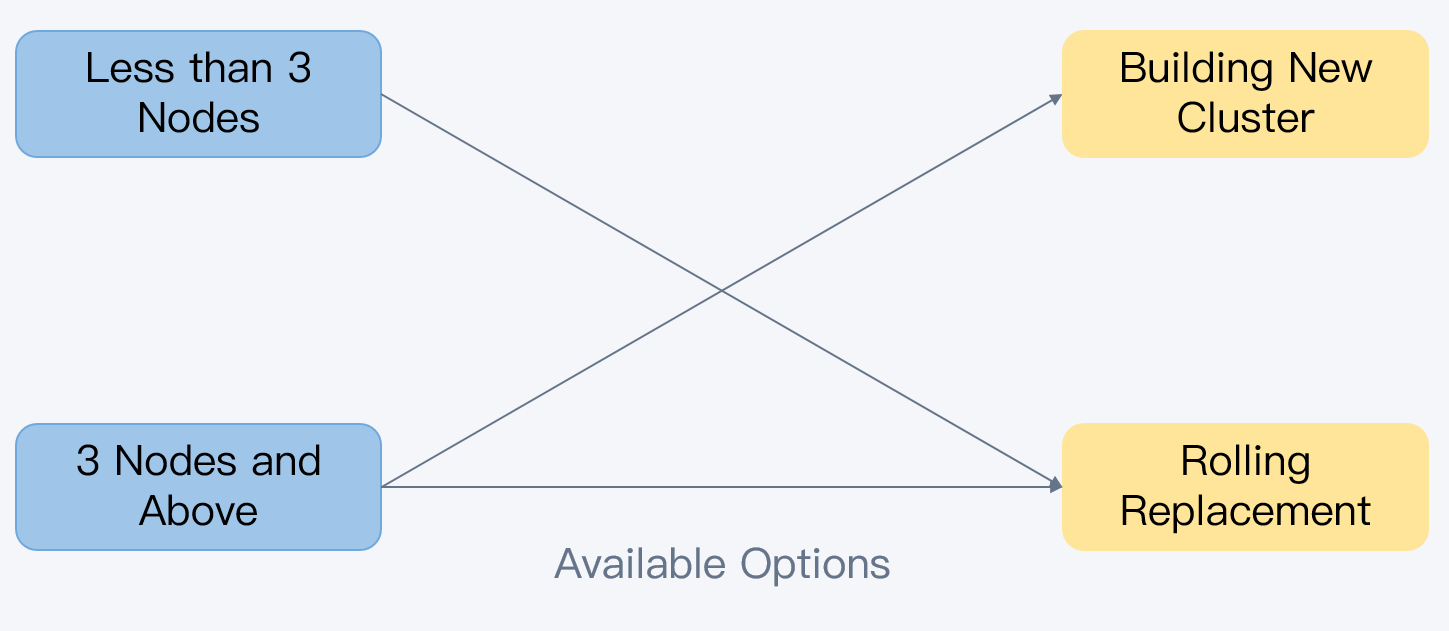
The two solutions also differ in the number of servers to be replaced. The rolling replacement has no limits on server quantity. On the other hand, the new-cluster solution mandates a minimum of 3 servers in the original cluster. Consequently, users aiming to replace fewer than 3 servers within a cluster are limited to the rolling replacement solution.
VM CPU Compatibility
When a SmartX HCI cluster is deployed, the functionality of VM CPU Compatibility will be automatically enabled. This feature distributes VMs with CPU models similar to their host. As all VMs in the cluster share the same CPU properties, they can migrate between nodes with CPUs of different generations. Additionally, users can also customize VM CPU compatibility, such as enabling physical passthrough and other compatibility features.
Therefore, it is essential that the CPU model of the destination host or cluster include the CPU model instruction set required by the VM being migrated. Even after the migration, the VM will retain the CPU model inherited from the original cluster.
If the destination host or cluster cannot meet these requirements, it is advisable for users to shut down the VM before initiating the migration process.
Network Resources
To rollingly replace servers in the cluster, there is no need to change network configuration. However, the new-cluster solution necessitates reconfiguring network resources. If users wish to adopt this approach, the data center and new cluster must meet the following three requirements:
- The data center has sufficient rack space to place new servers.
- The switch has sufficient ports for management, storage, and business networks.
- The new cluster has sufficient IP addresses for management, storage, and business networks.
Cluster Adjustments
Along with replacing server hardware, users may also adjust the cluster configuration in the following ways:
- Business network adjustment: Physically isolate the business network from the management network within the cluster.
- Rack room adjustment: Place servers in an IDC for central management.
- Hypervisor change: Transform from VMware virtualization to SmartX native hypervisor ELF in the SmartX HCI cluster.
- CPU vendor change: Migrate business services to clusters with specific CPUs to meet special requirements.
In particular, if users want to change the virtualization platform and CPU vendor, building new clusters is the only choice, as one cluster only supports one hypervisor and CPU brand.
Application Scenarios
It should be noted that the two solutions are not mutually exclusive; as mentioned earlier, they can both be applicable in certain scenarios. However, each solution has its own limitations. To provide a clear overview, we have summarized the key differences between them in the table below.
Case Studies: Solution Selection and Implementation
Case 1
Background
- The user has a 10-node SmartX HCI cluster (based on native hypervisor ELF) with storage capacity ranging from 15TB to 20TB per node.
- Four servers needed to be upgraded within a week.
- The cluster ran services that required high continuity and low I/O latency.
- The data center lacked available rack space and switch ports, and the cluster did not have any spare IP addresses for allocation.
Solution Selection and Implementation
Since the user did not have sufficient network resources for building new clusters and only a part of the servers in the cluster needed to be replaced, the user should replace servers in a rolling approach. This solution also eliminated the maintenance workload of splitting one cluster into two.
In the end, the user successfully completed the server replacement within a week using the rolling replacement approach.
Case 2
Background
- The user had an 8-node SmartX HCI cluster with storage capacity ranging from 12TB to 15TB per node.
- Eight servers needed to be replaced within three weeks.
- The 8-node cluster had been designated as a testing cluster, which entailed adjustments to the data center and cluster network.
Solution Selection and Implementation
As the user requires cluster adjustments, the new-cluster solution should be chosen to achieve a seamless upgrade of servers. In this solution, the network adjustments and relocation have minimal impact on the existing cluster. The only task is to migrate VMs across clusters to complete the replacement.
Ultimately, the user successfully completed the task within a week using this approach.
In addition, to keep up with the rapid business growth, Minmetals Futures also used SmartX’s native hypervisor ELF to scale out 3 times (from 4 nodes to 10 nodes) and upgraded server hardware through a rolling approach. The whole upgrade didn’t cause any disruptions to mission-critical services. For more information, please read our previous blog: Minmetals Futures: Achieving IT Infrastructure Dynamic Upgrade and Cross-Cluster Management Through HCI.
You may also be interested in:
Introducing SmartX HCI 5.1, Full Stack HCI for Both Virtualized and Containerized Apps in Production
Hard Disk Health Check with SmartX HCI: Three Ways to Auto-Detect and Isolate Abnormal Disks
Reuse Existing Devices with SmartX HCI: 4 Customers Achieve IT Infra Transformation at a Lower Cost
3 Comparisons Disclosing How SmartX HCI Outperforms VMware HCI
Explore Product Features Behind SmartX HCI’s Critical Capabilities